What is AtoM?¶
AtoM stands for “Access to Memory”. It is a web-based, open source application for standards-based archival description and access in a multilingual, multi-repository environment.
Technical overview¶
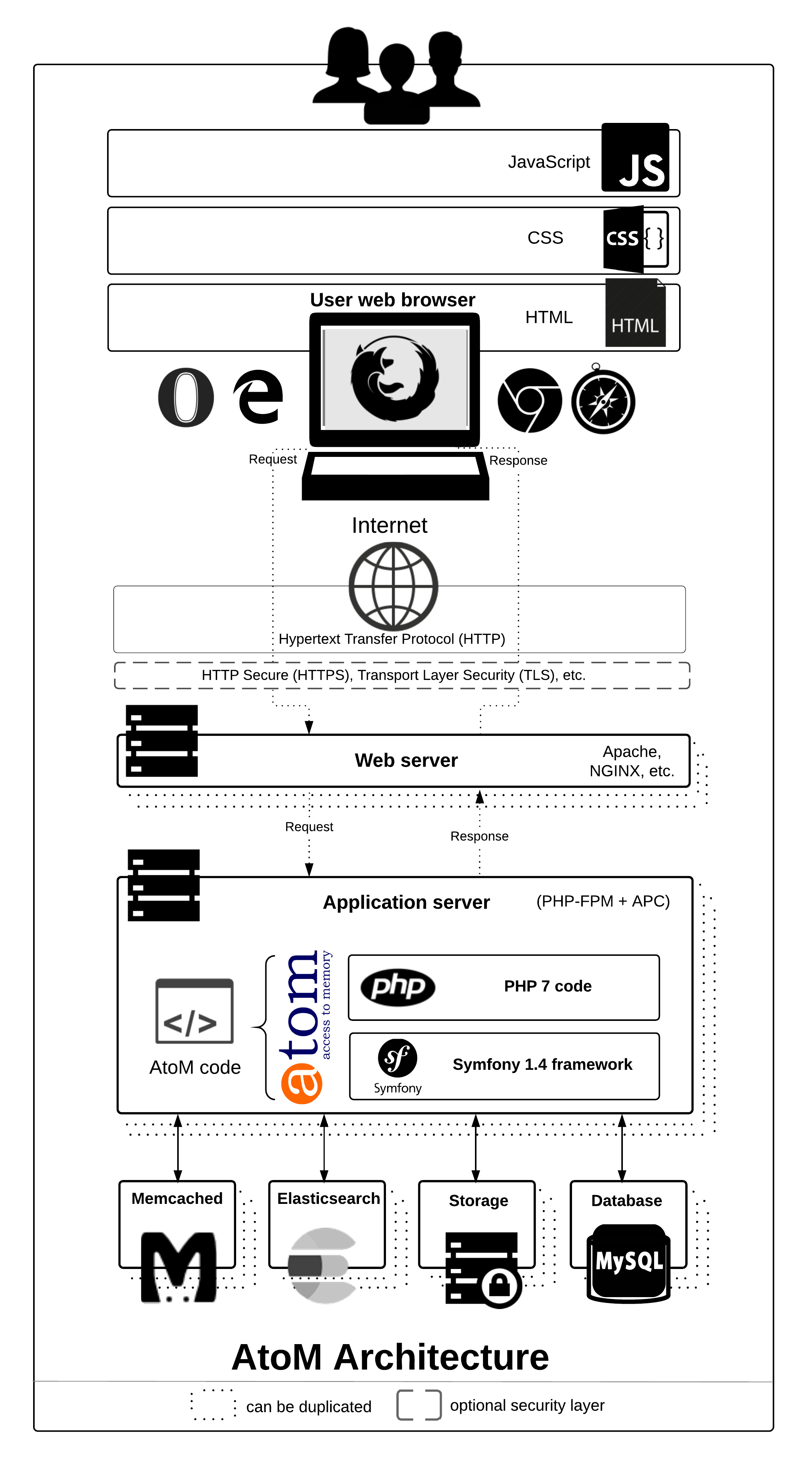
AtoM comprises:
HTML pages served to a web browser from a web server. The team at Artefactual (lead developers of the AtoM project) prefer Nginx in both development and production environments, but Apache has been tested as well; other web servers might be used but they are not tested by AtoM developers.
A database on a database server. MySQL (8.0) is used in development but AtoM uses a database abstraction layer and is therefore potentially compatible with Postgres, SQLite, SQLServer, Oracle, etc. (other solutions are not tested by AtoM developers)
PHP 7.4 software code that manages requests and responses between the web clients, the application logic, and the application content stored in the database. AtoM also makes use of a number of PHP extensions; see: Technical Requirements.
The Symfony (1.4) framework that organizes the component parts using object orientation and best practice web design patterns.
Elasticsearch (5.x), a distributed search server based on Apache Lucene, which acts as the application’s search and analytic engine. Elasticsearch is not integrated directly into AtoM code as a library, but as a service deployed in the same network which AtoM interacts with through a REST ful API.
To encourage application reliability (for example, the replacement of nodes in case of failure) and scalability (e.g. the ability to handle more traffic, requests, etc.), all elements of AtoM’s core stack can be configured in a distributed manner. For more information, see: Advanced configuration using Ansible.
Web-based¶
All user interactions with the system (add, view, search, edit, and delete actions) take place through a web browser. Users access HTML pages on the web server; clicking a button or link triggers a PHP script that sends a command to the database and returns the output as HTML back to the user’s browser.
Warning
With the release of 2.0, AtoM will no longer support Internet Explorer (IE) 8 or earlier versions. If possible, please upgrade your browser to IE9 or higher, or use a supported browser such as Firefox, Chrome, Opera, or Safari.
Please see Technical requirements for more information.
Open source¶
AtoM is built with open source tools (NGINX, MySQL, PHP, Symfony, Elasticsearch) rather than proprietary software. The underlying AtoM code is itself open source, with the source code freely available for use or modification as users or other developers see fit (under the A-GPL version 3 license). Therefore there is no cost to download any of the software required to run the AtoM application.
Our documentation is also freely available under a Creative Commons Attribution-ShareAlike 3.0 Unported licence (CC BY SA), and we maintain a free public User forum.
Find out more information on Open Source and Free Software from:
Standards-based¶
AtoM was originally built around International Council on Archives (ICA) descriptive standards:
- General International Standard Archival Description (ISAD) - 2nd edition, 1999
- International Standard Archival Authority Record (Corporate bodies, Persons, Families) (ISAAR) - 2nd edition, 2003
- International Standard For Describing Institutions with Archival Holdings (ISDIAH) - 1st edition, March 2008
- International Standard For Describing Functions (ISDF) - 1st edition, May 2007
AtoM supports Simple Knowledge Organization System (SKOS) - W3C Recommendation 18 August 2009.
AtoM is designed to be flexible enough for adaptation to other descriptive standards; see Descriptive standards for a full list of other standards currently supported.
Multilingual¶
All user interface elements and database content can be translated into multiple languages. AtoM comes with several translations installed, all of which are generously provided by volunteer translators from the AtoM User Community.
Want to help us translate the AtoM application into your language, or improve an existing translation? Find more information on how to contribute here.
Multi-repository¶
AtoM can be used by a single institution for its own descriptions or it can be set up as a multi-repository “union list” accepting descriptions from any number of contributing institutions.