Asynchronous jobs and worker management¶
AtoM relies on a job scheduler in order to execute certain long-running tasks asynchronously in the background (instead of synchronously via your web browser, making you wait until the task is done and the page loaded before continuing), to guarantee that web requests are handled promptly and work loads can be distributed across multiple machines. Example tasks in AtoM that use the job scheduler include:
- Generating finding aids
- Importing records via the user interface
- Exporting records via the Clipboard
- Using the Move module to reorganize archival description hierarchies
- Ingesting DIPs from Archivematica
We use Gearman as our job scheduler in AtoM. Gearman “provides a generic application framework to farm out work to other machines or processes that are better suited to do the work. It allows you to do work in parallel, to load balance processing, and to call functions between languages.”
You’ll need a good understanding of all the components involved to find out what the best configuration and arrangement of services will be for you. You could configure it so every service runs in the same machine, or scale up to many machines across the network. You can always start small in a single-node environment and add more hardware later.
Jump to:
Gearman Job Server configuration¶
You should have completed the initial installation and configuration of Gearman as part of your AtoM installation process. For more information, see:
Other considerations¶
An AtoM worker needs to know where the job server is running, which is defined
in an application setting under config/gearman.yml and defaults to
127.0.0.1:4730.
By default, Gearman’s job queues are stored in memory. However you are free to deploy the queue storage in a different machine or replace it with a durable solution like MySQL or SQLite3. For more configuration options available, visit: http://gearman.org/manual/job_server/.
Note that the job server will perfectly handle multiple workers running simultaneously and the work load will be distributed across all available workers. If there are no workers available because they are busy completing other tasks, the job server will store the job in the queues and deliver them once a worker becomes available.
If you’re planing to connect multiple AtoM instances to the same Gearman server,
make sure to set a different string value for the workers_key setting
located in config/app.yml. This will avoid collisions between those
instances and the workers will only take the jobs that belong to their related
AtoM install.
Whenever you change any of these settings, make sure that the Symfony cache is cleared and the workers are restarted.
Gearman Job Worker management¶
In AtoM, a worker is just a CLI task that you can run in a terminal or supervise with specific tools like upstart, supervisord or circus. The worker will wait for jobs that are assigned by the job server.
The simplest way to run a worker is from your terminal:
php symfony jobs:worker
A better way to run a worker is to use a process supervisor like systemd. This is the recommended method documented in the Ubuntu AtoM installation guide. See:
With this method, you can control the service execution status with the following commands:
sudo systemctl enable atom-worker # Enables the worker (on boot)
sudo systemctl start atom-worker # Starts the worker
sudo systemctl stop atom-worker # Stops the worker
sudo systemctl restart atom-worker # Restarts the workers
sudo systemctl status atom-worker # Obtains current status
Restarting the atom-worker¶
Restarting the atom-worker is often a useful troubleshooting step. You
should consider restarting the atom-worker if:
- You have encountered a 500 error related to a task in AtoM supported by the job scheduler
- You have made changes to the worker configuration
- You have a job that never seems to complete in the queue
Tip
When encountering a 500 error, we recommend first consulting the webserver error log for more information. See:
If you see the following message in the related error log output, it’s likely
that the 500 error can be resolved by restarting the atom-worker:
"No Gearman worker available that can handle the job."
Important
The systemd service configuration also includes a start rate limit of 3
restarts in 24 hours of the atom-worker, after which the the fail counter
will need to be manually reset to be able to restart the worker. See below
for more information:
Atom-worker start rate limit¶
The systemd service configuration file created during the Ubuntu
installation process includes several
parameters that govern how the service will attempt to automatically restart
itself following a failure. The following lines in the [Service] section
of the configuration block tell the service to attempt a restart in 30-second
intervals following a failure:
Restart=on-failure
RestartSec=30
However, to prevent the service from being caught in a loop when restarting
does not resolve the source cause of the failure, the configuration block also
includes a restart attempt limit of 3 attempts in 24 hours, in the [Unit]
section:
# High interval and low restart limit to increase the possibility
# of hitting the rate limits in long running recurrent jobs.
StartLimitIntervalSec=24h
StartLimitBurst=3
If the worker hits the start rate limit (3 starts in 24h), the failed status will need to be manually cleared before the worker can be restarted. You can reset the fail counter with the following:
sudo systemctl reset-failed atom-worker
sudo systemctl start atom-worker
If you see the following message when attempting to restart the
atom-worker, it is likely you have hit the start rate limit and will
need to clear it before successfully restarting:
Job for atom-worker.service failed.
See "systemctl status atom-worker.service" and "journalctl -xe" for details.
Atom-worker journal¶
When configured via systemd, you can have access to the journal of the
atom-worker unit as follows:
sudo journalctl -f -u atom-worker
This is useful in case you need to troubleshoot the worker.
Job and job scheduler management¶
The status of individual jobs executed via the user interface can be
viewed via the  Manage > Jobs page. For more information, see:
Manage > Jobs page. For more information, see:
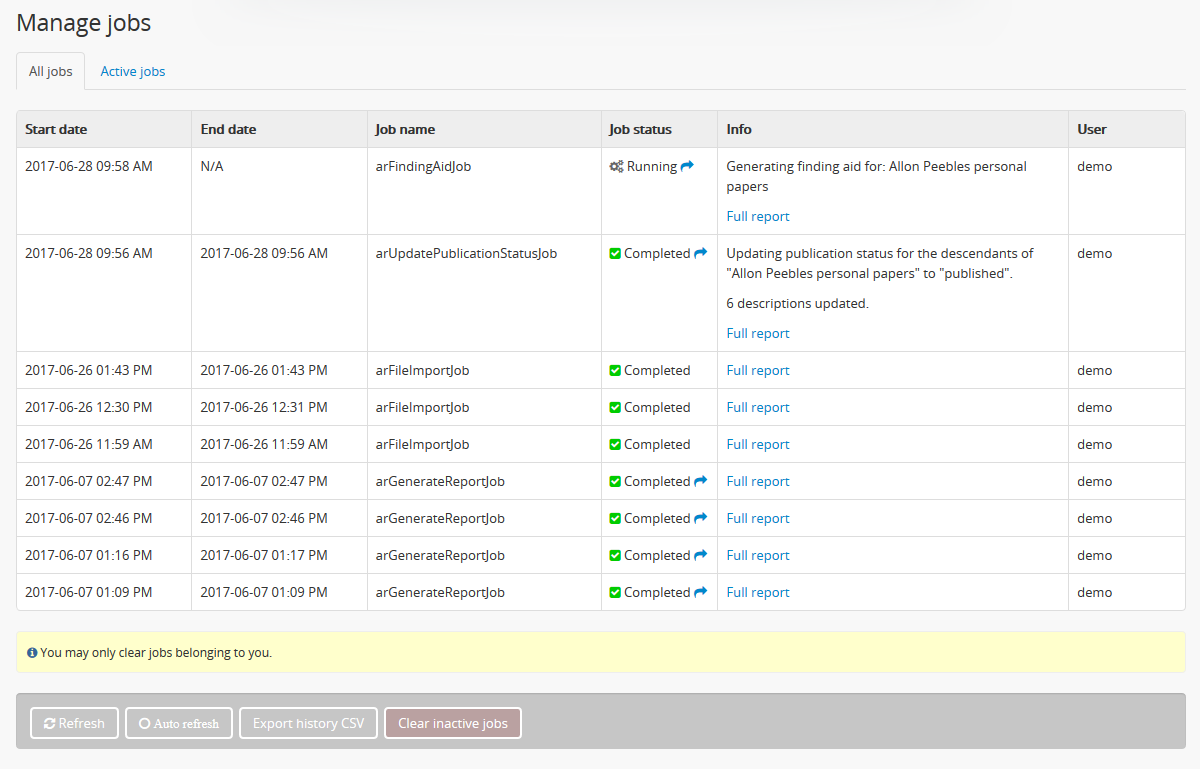
All authenticated (e.g. logged in) users can access the Jobs page. However, most users will only see jobs and be able to clear jobs which they have started. Only an administrator can see the status of all jobs - however, like all users, administrators can only clear jobs that belong to them via the user interface.
For system administrators with command-line access, AtoM has a task that can be used to clear all jobs from the queue as well as clear the job history of previous jobs from the database.
Important
The following task clears ALL jobs, including those currently running and queued. This means you will need to manually restart any jobs you would like to continue after running this command!
Note that the history of previous jobs is also cleared from the database. If you would like to preserve job history information before running this task, the Manage jobs page in the AtoM user interface includes an option to download a CSV of the job history. For more information, see:
To clear all jobs and job history, run the following from AtoM’s root installation directory:
php symfony jobs:clear
Troubleshooting jobs that will not complete¶
Occasionally, a long-running or resource-intensive job can exhaust all available system resources - generally this will result in a job shown on the Manage jobs page of the AtoM user interface that remains indefinitely stuck at the “Running” status.
You can use the jobs:clear command-line task to clear all jobs if desired.
This will terminate the stalled job, as well as any other jobs in the queue,
and delete the prior job history from AtoM’s database. Depending on the cause
of the stall, you may need to restart the atom-worker after - see above:
However, this approach means you will need to manually restart any previously queued jobs you would like to retry.
Alternatively, if you have access to the MySQL command-prompt, you can also use SQL to kill just a specific stalled job if you don’t want to lose other jobs in the queue, and/or the job history. For more information, see: