Command line tools¶
There are a number of command line tools that can help you troubleshoot various AtoM problems.
See below for Common AtoM database queries.
See also
- Populate search index
- Clear cache
- Load digital objects via the command line
- Import and export from the command-line
- Web server logs
We also have a slides and videos of many of our command-line tasks. See:
Find out what version of AtoM you’re running¶
You can always find out what version of AtoM you have installed via the user interface by navigating to Admin > Settings > Global - the application version is the first thing listed on the Settings page. See: Application version for more information.
However, if you’d like to check the application version from the command-line, you can run the following command from AtoM’s root folder:
php symfony tools:get-version
Add a SuperUser (Admin) account¶
You can create a new administrator account from the command-line using the following command:
php symfony tools:add-superuser --email="youremail@example.com" --password="MYSUPERPASSWORD" <username>
The username should not have any spaces in it.
If you’d like to quickly create a user for demonstration, diagnostic purposes, you can use the following command:
php symfony tools:add-superuser –demo
This will create a superuser with username “demo”, email “demo@example.com”, and password “demo”.
Promote a user to an administrator¶
If you’d like to promote a user account in AtoM to have full administrator access privileges via the command-line, you can use the following task. You will need to know the user name of the account.
php symfony tools:promote-user-to-admin <username>
If the user doesn’t exist you’ll see the following error:
Unknown user.
If the user is already an administrator:
The given user is already an administrator.
If the operation succeeds:
The user <username> is now an administrator.
See also
For more information on user permissions, user roles, and how to manage them, see:
Change a password¶
If you need to change the password on a user account in AtoM, you can do so via the command-line.
php symfony tools:reset-password [--activate] username [password]
The username is a required value, while the password is optional - if no password is entered, AtoM will generate an 8-character temporary password to be used for the user account. AtoM will return the new password in the command-line.
Warning
We strongly recommend that these auto-generated passwords ONLY be used temporarily! They are not strong passwords - users should generate longer passwords that include special characters. For more information, see:
If the user account is currently marked inactive in the system (see
Mark a user “Inactive” for more information), you can also use the option
--activate to mark that account as active again.
See also
You can also manage user passwords through the user interface. For more information, see:
Delete a user account from the command-line¶
AtoM provides a method to delete a user account via the user interface, but you can also delete a user directly from the command-line interface. To do so, you will need to know the username of the user you wish to delete. The basic syntax for the command is:
php symfony tools:delete-user <username>
By typing php symfony help tools:delete-user into the console, we can see
the help text and options associated with this task:
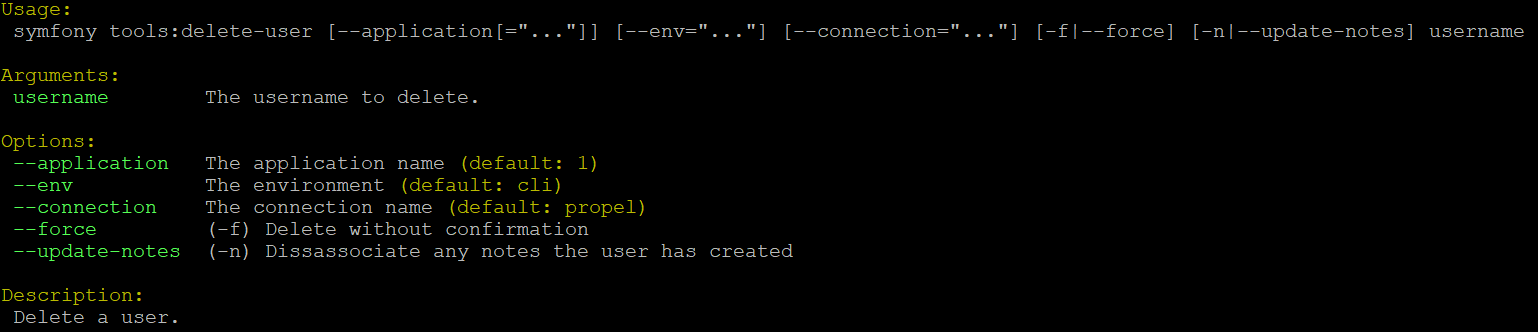
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the task.
The command, when run, will normally prompt you for comfirmation before
proceeding. However, if you wish to skip the confirmation step, you can use the
--force or -f option.
Additionally, if the user has added notes (e.g. General notes; RAD special notes such as Accompanying material notes; Archivists’ notes; etc.) to an archival description, then by default, the user ID of that user is associated with the note in the database. Because of this, AtoM will not let you delete a user without first removing the user association from the notes, and the task will be aborted without delting the user account:
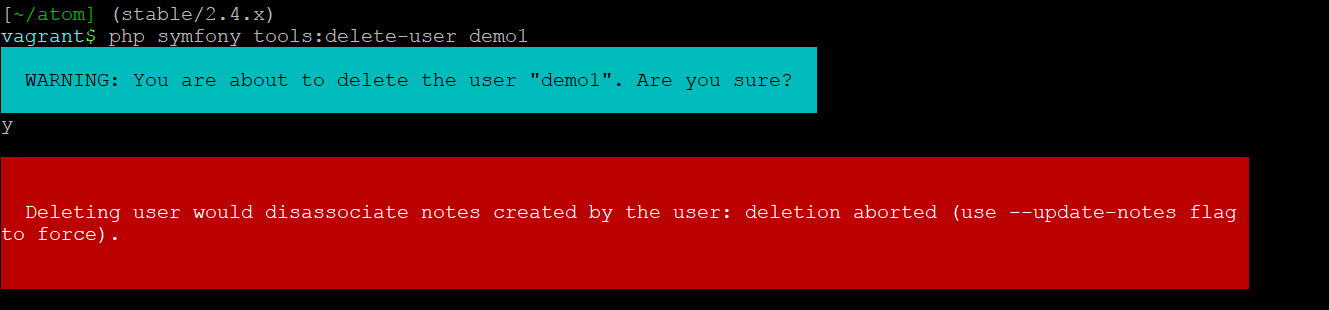
To remove the user association with the notes so the task can proceed, you can use
the --update-notes (or -n for short) option. When this is used, any notes
associated with the user in the database will be updated so the user field is
NULL, and the user account can now be deleted. Any notes created by the user
will remain in the system, unaffected by the deletion.
Important
The task will not allow you to delete a user account if it is the only administrator account in the system. If you wish to do so, you can use the other available tasks to create a new user and/or promote an existing user to the administrator group. See:
Here is an example of running the task with both options (force and update-notes)
used together, where the user being deleted has a username of demo:
php symfony tools:delete-user -f -n demo
Regenerating derivatives¶
If you are upgrading to AtoM 2 from ICA-AtoM, the digital object derivatives (i.e. the reference display copy and the thumbnail generated by AtoM when a master digital object is uploaded) are set to be a different default size (i.e. they are larger in AtoM) - consequently, after an upgrade, derivatives from ICA-AtoM may appear blurry or pixellated. Alternatively, if you have changed the Digital object derivatives settings, you might want to regenerate your derivatives so that the new setting is used for multi-page content such as PDF derivatives.
As well, sometimes the digitalobject:load task used for importing digital
objects to existing descriptions (see:
Load digital objects via the command line) won’t generate the thumbnail and
reference images properly for digital objects that were loaded (e.g. due to a
crash or absence of convert installed, etc. - see under requirements,
Other dependencies). In this case, you can regenerate
these thumbsnail/reference images using the following command:
php symfony digitalobject:regen-derivatives
By typing php symfony help digitalobject:regen-derivatives into the
command-line, you can see the options available for this task:
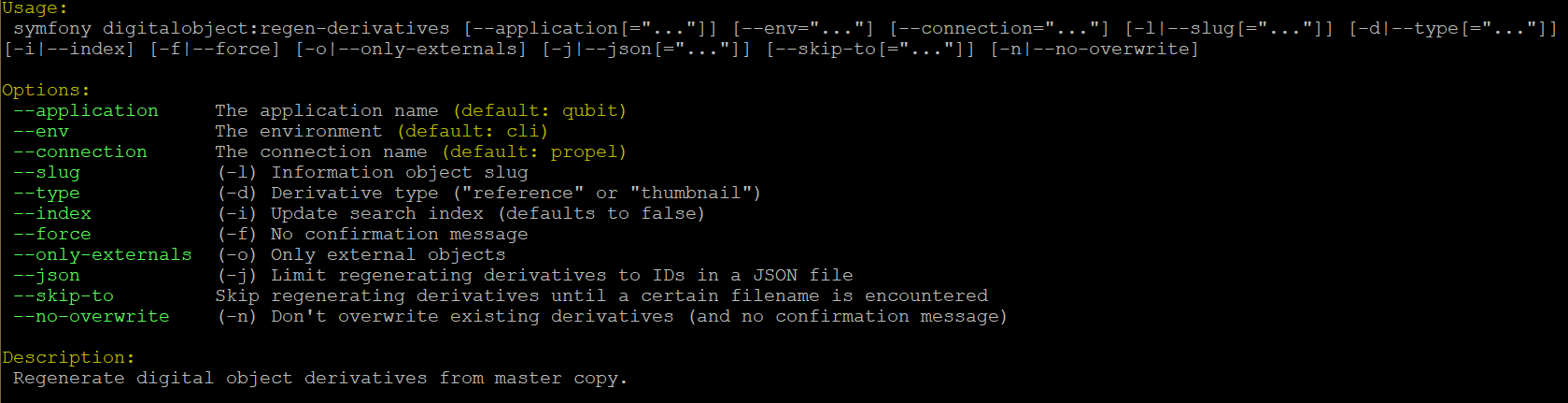
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the task.
The --index option is used to enable the rebuilding of the search index as
part of the regeneration task. When running this task via the command-line
interface, indexing is disabled by default to allow the task to progress
more quickly - generally, we recommend manually clearing the cache and
rebuilding the search index following the use of this task - to do so,
from AtoM’s root directory, run:
php symfony cc && php symfony search:populate
However, if you would like to re-index as the derivative regeneration progresses,
the --index option can be used to enable this. For more information on
populating the search index, see: Populate search index.
The --slug option can be used to target specific derivatives associated with
a description, using the description’s slug as criteria. Any
digital object attached or linked to the description whose slug is
provided as criteria will have its derivatives regenerated. Example use:
php symfony digitalobject:regen-derivatives --slug="the-jane-doe-fonds"
The --type option (or -d for derivative type) can be used if you only
want to regenerate one type of digital object derivative - either the
reference display copy used on the view page of related archival
descriptions, or the thumbnail used in search and browse results. Supported
parameters are:
- reference
- thumbnail
So, for example, if you only wanted to regenerate your thumbnails, you could execute the command like so:
php symfony digitalobject:regen-derivatives --type="thumbnail"
The --force or -f option can be used to skip the warning normally
delivered by the task when the command is entered. Because the task will delete
ALL previous derivatives - including those manually altered by editing the
thumbnail or reference display copy of a digital object via the
user interface (see: Edit digital objects for more information) - the task
will normally ask for confirmation when invoked:

However, experienced developers and system administrators can skip having to
manually confirm the procedure by using the --force (or -f for short)
option as part of the command.
The --only-externals (or -o for short) option can be used if you would
only like to attempt to regenerate the local derivatives for linked digital
objects - that is, those that have been linked via an external URI, rather than
by uploading a master digital object. For more information on linking
digital objects, see: Link a single digital object to an archival description.
The --skip-to option is useful when the task is interrupted, such as when
an error is encountered mid-process that ends the task. As the task
progresses during normal execution, it will output information about the
current digital object filename it is working on. If the task interrupts
(for example, trying to fetch a large external digital object, the task might
time out), a system administrator can use this option to resume the task
where it interrupts. Example:
$ php symfony digitalobject:regen-derivatives
Regenerating derivatives for file1.jpg...
Regenerating derivatives for file2.jpg...
Regenerating derivatives for file3.jpg...
<timeout error occurs>
$ php symfony digitalobject:regen-derivatives --skip-to='file3.jpg'
Regenerating derivatives for file3.jpg...
<task continues where it left off>
The --json or -j option is for advanced users who would like to target
only a specific subset of digital objects for regeneration. With this option, a
user can supply the path to a JSON file that lists the internal
digital_object ID’s associated with the digital objects targeted and stored in
AtoM’s database. These digital_object ID’s will first need to be determined
by crafting an SQL query designed to meet your specific criteria. Help crafting
these queries is not covered here (though you can see below,
Common AtoM database queries, for a BASIC introduction to SQL queries in AtoM) - in
general, we only recommend this task be used by experienced administators.
Once you have determined the IDs of the digital objects you would like to target with the task, you can place them in square brackets in a JSON file, separated by commas, like so:
[372, 366, 423, 117]
(etc)
The criteria for the --json option then becomes the path to your JSON file:
php symfony digitalobject:regen-derivatives --json="path/to/my.json"
Warning
When running the regen-derivatives task, all of your current derivatives
for the targeted digital objects will be deleted - meaning ALL of them if you
provide no criteria such as a slug or a JSON file. They will be replaced
with new derivatives after the task has finished running. If you have
manually changed the thumbnail or reference display copy
of a digital object via the user interface (see:
Edit digital objects), these two will be replaced with digital
object derivatives created from the master digital object.
Finally, the --no-overwrite or -n option can be used if you only want to
generate derivatives where they are currently missing. All existing derivatives
will be left as-is in AtoM. When this option is used, no confirmation prompt is
given: the task will begin generating missing derivatives as soon as you enter
it in the console.
Re-indexing PDF text¶
php symfony digitalobject:extract-text
In rare situations you may want to to re-index all PDFs to make their text searchable in AtoM without having to re-import them completely. This task will go through each existing PDF imported into AtoM and re-index their contents for searches.
For linked digital objects (e.g. PDFs that are linked from a publicly accessible URI, instead of uploaded locally - see for example: Link a single digital object to an archival description), this task will re-fetch a version of the external PDF and store it in a temporary file, re-index the contents, and then purge the local master after the indexing is complete.
Tip
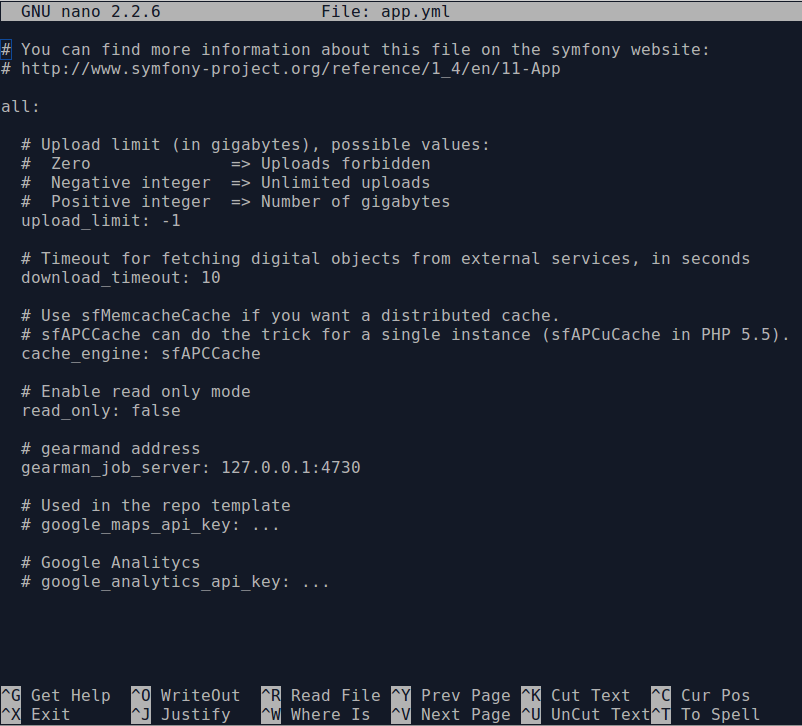
Large PDFs may cause 500 errors if you do not first adjust the download
timeout limit. You can do this by changing the value in the app.yml file
located in /config/app.yml. The default timeout value in AtoM is 10s. You
should also clear the cache after making changes to the app.yml file:
php symfony cc
Rebuild the nested set¶
AtoM generally uses a relational database to store its data (we recommend MySQL). However, relational databases, which are comprised of flat tables, are not particularly suited to handling hierarchical data. As developer Mike Hillyer notes, “Hierarchical data has a parent-child relationship that is not naturally represented in a relational database table.” One method of addressing this is to employ a “Nested set model” (Wikipedia). AtoM makes use of a nested set to manage hierarchical relationships, such as between parent and child terms and descriptions.
Sometimes, during operations that involve updates to large hierarchies, the nested set can become corrupted - especially if the server times out during an operation that reaches the execution limit settings. The following task will rebuild all nested sets in AtoM:
php symfony propel:build-nested-set
Generate slugs¶
In some cases, AtoM may time out in the middle of an operation that involves the creation of new records - for example, if a user attempts to import a very large CSV file through the user interface (rather than the command-line - see: CSV import). In such cases, it is possible that AtoM has died after creating an information object, but before having a chance to create a slug for the record. This can cause unexpected errors in the application - most notably, 500 errors when trying to access the records missing slugs through the application interface.
If you want to generate slugs for records in AtoM without them, you can use the following command:
php symfony propel:generate-slugs
This task will work for the following entities:
- information objects (e.g. archival descriptions)
- actors (e.g. authority records)
- terms
- taxonomies
- physical objects (e.g. storage locations, etc)
- events (e.g. creation events, etc - usually the relationship between actors and information objects)
- accession records
- deaccession records
- digital objects
- functions
- rights records
- static pages
- relations (e.g. relations between objects - i.e. relating two descriptions, relating an information object to a digital object, relating an information object to a physical storage location, relating two actors, etc)
If an error has left other areas in AtoM without slugs (for example, a donor record, etc), this task will not resolve the issue - you will likely have to manually insert a slug into the database for that entity.
For information objects, the generate slugs task will respect the global settings for the source from which description permalinks are created. These settings can be controlled by an administrator via the user interface - for more information, see: Generate description permalinks from.
Note that by default, existing slugs will not be replaced. If you want to generate new slugs for existing objects, you will need to first delete the existing slugs from the database. This can be useful for records in which a random slug has been automatically assigned, because the default user data used to generate the slug has not been provided (see below for more information on how slugs are generated in AtoM).
However, if you would like to replace all existing slugs with newly
generated slugs, you can use the --delete option, like so:
php symfony propel:generate-slugs --delete
Important
This will replace all custom slugs you may have created with the Rename module! For more information on the Rename module, see: Rename the title or slug of an archival description
Slugs can also be manually deleted via SQL queries. For further information on deleting slugs from AtoM’s database via SQL, see below in the section on Common AtoM database queries - particularly, Delete slugs from AtoM.
Notes on slugs in AtoM¶
A slug is a word or sequence of words which make up the last part of a URL in AtoM. It is the part of the URL that uniquely identifies the resource and often is indicative of the name or title of the page (e.g.: in www.yourwebpage.com/about, the slug is about). The slug is meant to provide a unique, human-readable, permanent link to a resource.
In AtoM, all pages based on user data (such as archival descriptions, archival institutions, authority records, terms, etc.) are automatically assigned a slug based on the information entered into the resource:
| Entity type | Slug derived from |
|---|---|
| Archival description | Title or Reference code |
| Authority record | Authorized form of name |
| Accession | Identifier (accession number) |
| Users, Groups | Automatically generated |
| Other entities | Name |
Generated slugs will only allow digits, letters, and dashes. Sequences of unaccepted characters (e.g. accented or special characters, etc.) are replaced with valid characters such as English alphabet equivalents or dashes. This conforms to general practice around slug creation - for example, it is “common practice to make the slug all lowercase, accented characters are usually replaced by letters from the English alphabet, punctuation marks are generally removed, and long page titles should also be truncated to keep the final URL to a reasonable length” (Wikipedia). In AtoM, slugs are truncated to a maximum of 250 characters.
If a slug is already in use, AtoM will append a dash and an incremental number (a numeric suffix) to the new slug - for example, if the slug “correspondence” is already in use, the next record with a title of “Correspondence” will receive the slug “correspondence-2”.
If a record is created without data in the field from which the slug is normally derived (e.g. an archival description created without a title), AtoM will assign it a randomly generated alpha-numeric slug. Once assigned, slugs for archival descriptions can be changed through the user interface. Slugs for other entity types cannot be changed through the user interface - either the record must be deleted and a new record created, or you must manipulate the database directly.
Tip
Users can also edit the slug associated with an archival description via the user interface. For more information, see:
Finally, static pages, or permanent links, include a slug field option, but only slugs for new static pages can be edited by users; the slugs for the default Home page and About page in AtoM cannot be edited. New static page slugs can either be customized by users or automatically generated by AtoM if the field is left blank; AtoM will automatically generate a slug that is based on the “Title” you have indicated for the new static page. For more information on static pages in AtoM, see: Manage static pages.
Note
Slugs such as “search” and “browse” are reserved for use in AtoM by the Search and Browse modules - if you create a static page, or even a description, with the slug “search”, it may interfere with your search results, redirecting to this new page instead of display your results! A simple workaround would be to iterate the slug (e.g. “search-1”) or alter it in some meaningful way (e.g. for a static page with tips on searching, changing the slug to “search-help”).
Tip
For developers interested in seeing the code where slugs are handled in
AtoM, see /lib/model/QubitSlug.php
Taxonomy normalization¶
A command-line tool will run through taxonomy terms, consolidating duplicate terms. If you’ve got two terms named “Vancouver” in the “Places” taxonomy, for example, it will update term references to point to one of the terms and will delete the others.
php symfony taxonomy:normalize [--culture=<culture>] <taxonomy name>
Task options
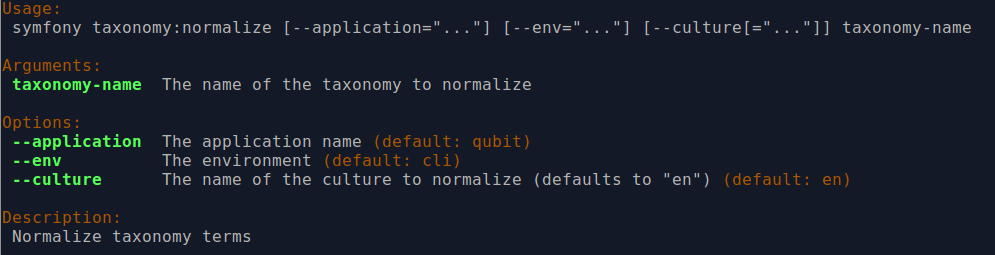
By entering php symfony help taxonomy:normalize into the command-line, you
see the options and descriptions available on this tool, as pictured above.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --culture option on this command-line tool is optional - the default
value, if none is entered is en (English). The value you
enter for <culture> should be the default culture of the terms you wish to
normalize - in most cases this will be the default culture you set up when
installing AtoM (though depending on your imports and multi-lingual use of the
application, this may not always be true) The value, if needed, should be
entered using two-letter ISO 639-1 language code values - for example,
“en” for English; “fr” for French, “it” for Italian, etc.
See Wikipedia for a
full list of ISO 639-1 language codes.
The taxonomy name value should be entered as it is seen in the user interface in Manage > Taxonomies. This value is case sensitive. If the taxonomy name has spaces (i.e. if it is more than one word), you will want to use quotation marks.
Below is an example of running this command on French terms in the Physical object type taxonomy:
php symfony taxonomy:normalize --culture="fr" "Physical object type"
You might also run this command on English terms in the Places taxonomy like so:
php symfony taxonomy:normalize Places
Update the publication status of descriptions¶
In AtoM, an archival description can have publication status of either “Draft” or “Published”. The publication status of a record, which can be set to either draft or published, determines whether or not the associated description is visible to unauthenticated (i.e., not logged in) users, such as researchers. It can be changed via the user interface in the administration area of a description’s edit page by a user with edit permissions. See Publish an archival description for instructions on changing this via the user interface.
If you would like to change the publication status of a record via the command-line, you can use the following command-line tool, run from the root directory of AtoM. You will need to know the slug of the description whose publication status you wish to update.
You can also update the publication status of all descriptions associated with
an archival institution by using the --repo option and providing a
repository slug instead - details are included below. Here is the basic
syntax of the command with all options shown:
php symfony tools:update-publication-status [--application[="..."]] [--env="..."] [--connection="..."] [-f|--force] [-i|--ignore-descendants] [-y|--no-confirm] [-r|--repo] publicationStatus slug
Notes on use¶
AtoM requires two parameters to be able to execute the task: the publication status you wish to use, and the slug of a resource on which to perform the task. For the publication status, you can use any term you have added to the Publication status taxonomy in AtoM - the default terms are Draft, and Published. You cannot create a new publication status term by using this task - the term must already exist in AtoM, or the task will fail.
Example use (no options) - update a description with a slug of
example-description to published:
php symfony tools:update-publication-status published example-description
Task options:
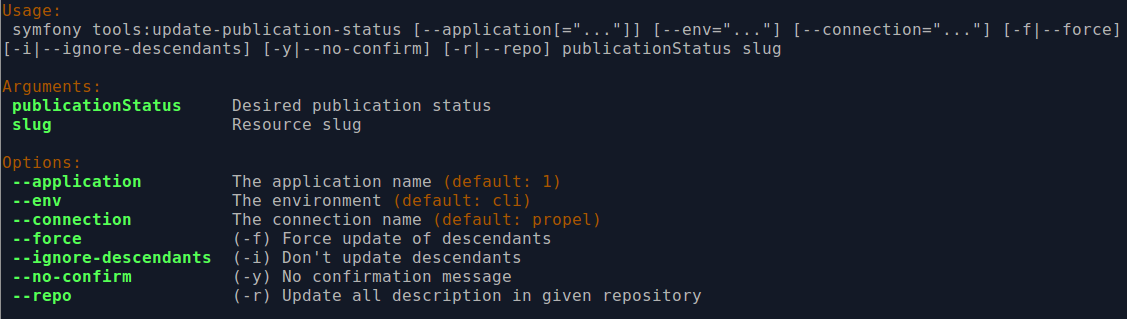
By entering php symfony help tools:update-publication-status into the
command-line, you see the options available on this tool, as pictured above.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the task.
In general and as in the user interface, if a parent
description is updated, it will also update the publication status of its
children. In some rare cases however, there may be legacy records in the
system with a publication status of NULL. The command-line option --force,
or -f for short, will force the update of the target information object
and all of its children, including legacy records that
might have a publication status of NULL. We recommend using this option any
time you want a publication status update to affect children as well.
The --ignore-descendents, or -i, option can be used to leave the
publication status of all children unchanged. This is
useful if you have a mixture of publication statuses at lower levels - some
draft, and some published.
Normally when the command is run, AtoM will ask for a y/N confirmation before
proceeding. The --no-confirm or -y option was introduced so that
developers who are interested in using this task in a larger scripted action
can override the confirmation step.
If the --repo or -r option is used, AtoM will update the publication
status for ALL descriptions belonging to the associated
repository (i.e. archival institution). To use this option,
you must supply the slug of the repository.
Example use - updating all the descriptions associated with “My archival
institution” (slug = my-archival-institution) to published.
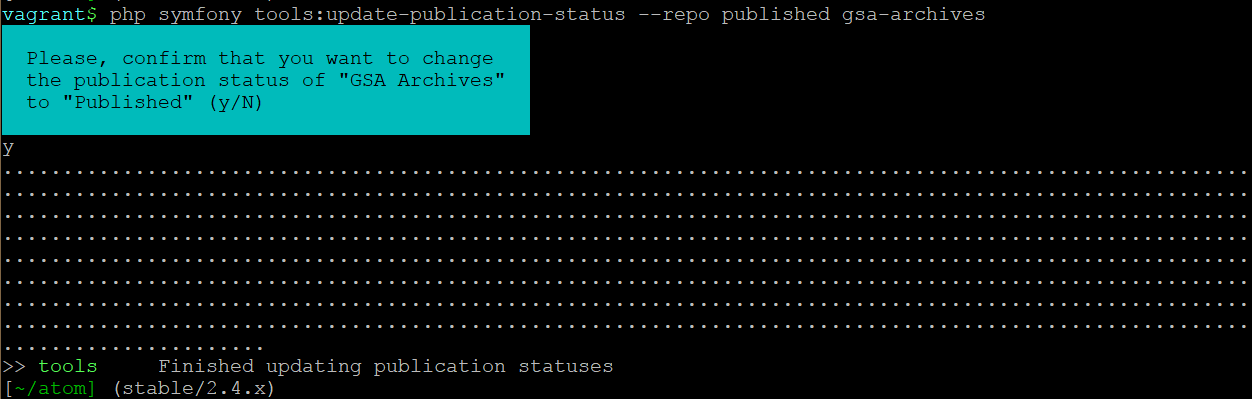
php symfony tools:update-publication-status --repo published my-archival-institution
As the task proceeds, it will print a . period in the command-line for each
record that is updated, providing a visual indication of progress.
Warning
This task is NOT designed for scalability. If you are planning on updating the publication status of thousands of records, we recommend using SQL to do so instead. We have included instructions on how to do so below - see:
Delete a description¶
You can delete a description from the command-line if you know the description’s slug. A slug is a word or sequence of words which make up a part of a URL that identifies a page in AtoM. It is the part of the URL located at the end of the URL path and often is indicative of the name or title of the page (e.g.: in www.youratom.com/this-description, the slug is this-description). When a new information object is created in AtoM, the slug for that page is generated based on the title, with spaces, stopwords, and special characters stripped out.
If you know the slug of a description you’d like to delete, use the following command to delete it from the command-line:
php symfony tools:delete-description <slug>
AtoM will ask you for confirmation before you proceed giving you a count of descriptions affected (e.g. the target description and its descendants):

Tip
If you would like to proceed without having to confirm your actions, you
can use the --no-confirmation option - or its shorthand, -B, like
so:
php symfony tools:delete-description -B <slug>
You can also delete all descriptions that are associated with a particular
repository, by using the --repository option, and supplying the
slug of the linked repository instead of the slug of a description. For
example, if your repository is called “Example Archives,” with a slug in AtoM of
example-archives, then you could delete all archival description
records linked to this repository with the following command:
php symfony tools:delete-description --repository example-archives
Delete all draft descriptions¶
If you want to remove all draft information object (e.g. archival description) records from AtoM, you can use the following command-line tool to delete all records with a publication status of “Draft”:
php symfony tools:delete-drafts
The task will ask you to confirm the operation:
>> delete-drafts Deleting all information objects marked as draft...
Are you SURE you want to do this (y/n)?
Enter “y” if you are certain you would like to delete all draft records.
Generate and cache XML for all archival descriptions¶
AtoM includes several options for exporting archival description metadata in XML format - for more information, see: Export XML.
Additionally, users can enable the OAI plugin to allow harvesters to collect archival description metadata via the OAI-PMH protocol, in EAD 2002 or Dublin Core XML - for more information, see: OAI Repository.
Normally, when exporting or exposing archival description metadata, the XML is generated synchronously - that is, on request via the web browser. However, many web browsers have a built-in timeout limit of approximately 1 minute, to prevent long-running tasks and requests from exhausting system resources. Because of this, attempts to export or harvest EAD 2002 XML for large descriptive hierarchies can fail, as the browser times out before the document can be fully generated and served to the end user.
To avoid this, AtoM includes a setting that allows users to pre-generate
XML exports via AtoM’s job scheduler, and then cache them in the downloads
directory. This way, when users attempt to download large XML files, they can
be served directly, instead of having to generate before the browser timeout
limit is reached. For more information, see: Cache description XML exports upon creation/modification.
The XML generated will be cached in AtoM’s downloads directory - 2
subdirectories named ead and dc will automatically be created, and the
XML will be stored by type in these two subdirectories.
When users attempt to download XML from the view page of an archival description, AtoM will check if there is a cached copy of the requested XML and if so, it will serve it. If there is no cached version available, then AtoM will fall back to the default behavior of generating the XML on request.
In an OAI-PMH request, if a cached version of the EAD 2002 XML is available,
AtoM will serve it in response to oai_ead requests - if there is not a
cached version, then AtoM will return a “Metadata format unavailable” reponse.
In contrast, if no cached DC XML exists, the OAI Repository module will
generate DC XML on the fly to respond to the request. For further information,
see: OAI Repository.
By default, cached XML files are generated for public users, meaning that draft descriptions are not included in the XML.
When engaged, this setting will not retroactively generate and cache XML for existing descriptions. Howeveer, this command-line task can be used to generate and cache EAD 2002 and DC XML for all existing descriptions.
The basic syntax for the task is:
php symfony cache:xml-representations
By running php symfony help cache:xml-representations we can see the
command-line’s help output for the task:
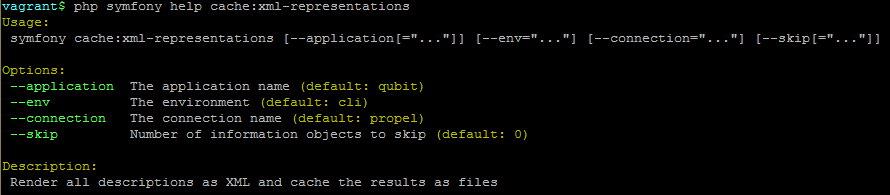
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for Symfony to be
able to execute the task.
As the task progresses, the console will output the related ID of the current information object, followed by the number of the current information object (aka archival description) and the total count:
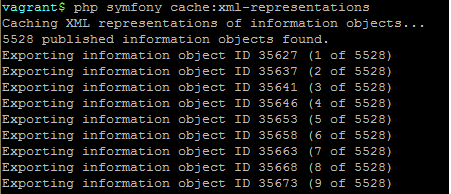
In some cases with very large hierarchies (for example, an
archival unit with thousands or tens of thousands of descendants),
available system memory may be exhausted during this process, and the task may
crash before all XML can be generated. In that case, the --skip option can
be useful for restarting the task exactly where it left off.
The --skip option accepts as a parameter the number of information objects
to be skipped - so for example, if the task crashed while trying to generate
the XML for infomation object 2445 of 5528, then you could restart it on
information object 2445 again by skipping the first 2444, like so:
php symfony cache:xml-representations --skip="2444"
Note
By default, cached XML files are generated for public users, meaning that draft descriptions are not included in the XML, and cached XML is not generated for any unpublished archival units.
The XML generated will be cached in AtoM’s downloads directory - 2
subdirectories named ead and dc will automatically be created, and the
XML will be stored by type in these two subdirectories.
Remove HTML content from archival description fields¶
As of the 2.2 release, HTML added to atom’s descriptive templates will be automatically escaped for security purposes. This means that if you were previously using HTML to style content added to an edit template, it may no longer display correctly:
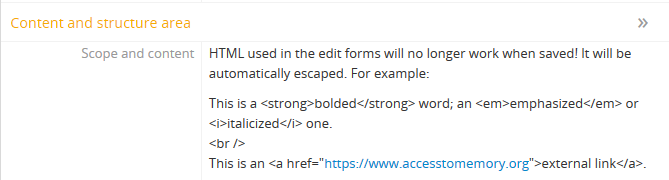
To assist legacy users who have added HTML to records in AtoM, a command-line task to strip the HTML from descriptions and other entities has been added. At present, it will only remove HTML from the following entity types:
- archival description
- authority record
- Notes (however, General notes are not affected currently)
- archival institution (aka repository records)
- rights record
Other entities in AtoM (such as accessions, user and goup records, terms, etc.) will not be affected.
Important
There are also some fields in the information object (e.g. archival description) that do not currently support this task - meaning HTML will not be removed from these fields by running this CLI task:
- RAD title note (e.g. Source of title proper, Attributions and conjectures, etc)
- General notes fields in any template
To run the HTML scrub task:
From the root directory of your AtoM installation, run the following command:
php symfony i18n:remove-html-tags
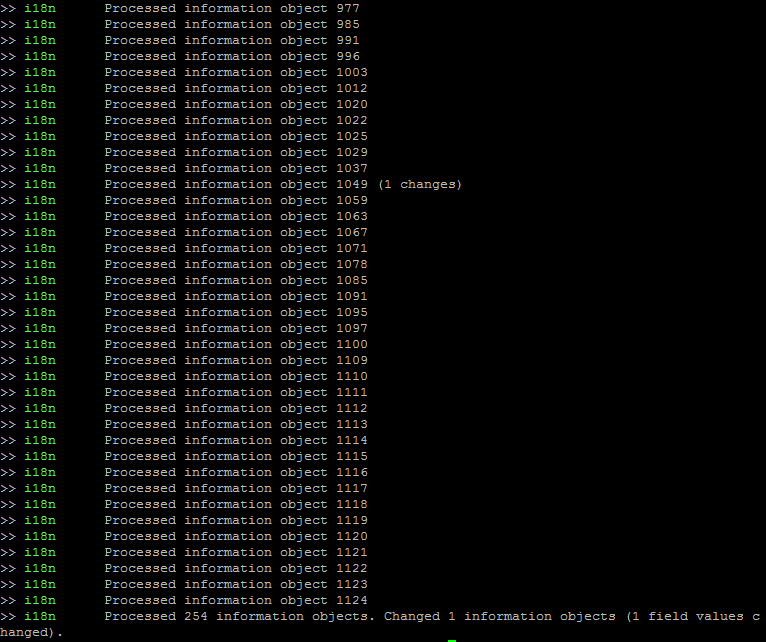
The command-line interface will output information on how many fields within each information object were scrubbed, as well as a summary when the task terminates:
The task will have the following effects on HTML elements:
- Links, including email
mailto:links, will be replaced with AtoM’s custom formatting for links - for more information, see: Add custom hyperlinks to text fields. This means that after being run, links will now appear in AtoM’s view pages as they were intended to when the HTML was added. - Styling elements, such as
<em>,<b>,<strong>,<i>, etc. will be removed with no substitutions (the text they wrap will be preserved). - List elements (
<li>) will be replaced with an asterix and a space - AtoM’s edit templates already include a helper that will transform asterixes used this way into bullets. So,<ul><li>This item</li></ul>will become* This item - Definition list elements such as
<dd>,<dt>, etc (which were briefly used in earlier versions of AtoM to structure physical description EAD import data) will be removed (the text they wrap will be preserved). - Paragraph tags (
<p>) will be removed, and substituted with 2 line breaks to preserve spacing (i.e./n/n) - HTML escape characters (for example,
",&,<) will will be replaced with the character they represent (e.g.",&,<)
Export a list of terms linked to one or more descriptions from a taxonomy¶
This task is useful when performing an administrative review of your AtoM installation. If you have imported a large controlled vocabulary to one of AtoM’s taxonomies (such as subject, place, or genre access point terms), you might want to be able to determine which terms are actually in use (i.e. linked to descriptions) versus those which are currently not linked to any descriptions.
This task, when run against a specific taxonomy, will generate a CSV with a list of terms that are linked to one or more archival descriptions (information objects). The CSV includes a count of how many times a specific term is used (e.g. a count of direct links to information objects - inherited links from a hierarchy are not counted). It does not list terms that are in the taxonomy but currently not used.
The CSV output for the task includes the following columns:
id: the internal object ID of the term
parentId: the object ID of the the parent to which the term is linked.
- Even in a taxonomy that is not organized hierarchically, terms are linked
to a root term object. If the terms are organized heirarchically, then the
parentIDvalue will be the objectID of the parent term.
- Even in a taxonomy that is not organized hierarchically, terms are linked
to a root term object. If the terms are organized heirarchically, then the
taxonomy: the ID of the taxonomy to which the terms belong. In AtoM, typically the Subjects taxonomy ID is 35; Places is 42, etc.
- name: the authorized/preferred form of name for the term in the
current culture
sourceCulture: the culture in which the term was created - generally a 2 letter ISO language code value (e.g. en, fr, es, etc)
culture: Generally the value of the default installation culture of your AtoM instance, returned as a 2 letter ISO language code value (e.g. en, fr, es, etc)
use_count: a simple count of the number of times the term has been directly linked to an information object (archival description). Inherited relationships are not counted - e.g. in a hierarchy of
Canada > Ontario > Toronto, when Toronto is linked to an information object, Canada and Ontario do not also receive a count.
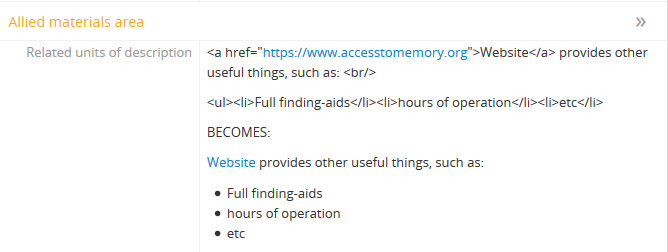
To see the help for the task:
php symfony help csv:export-term-usage
You must specify a target destination for the export as a file path, including
the name of the csv, and ending in the .csv extension, for the command to
work as expected. See the examples below.
Options
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the export.
The --items-until-update option accepts a whole integer value, and will
indicate the progress of the task every n items by printing a dot in the
console.
you can use either the --taxonomy-name or the --taxonomy-id options to
tell the command which taxonomy terms you wish to count in the resulting CSV.
By default, the --taxonomy-name option expects the English name of the
target taxonomy; however, you can use the --taxonomy-name-culture option
to give the name of a taxonomy in another culture - this option expects a
2-letter ISO language code (e.g. “en”, “fr”, “es”, etc) as its value.
The --taxonomy-id option expects as its value the internal ID of the
target taxonomy. Below is a list of some of the more commonly used taxonomies
in AtoM, and their IDs. This list is NOT comprehensive - to see the full list,
navigate to /lib/model/QubitTaxonomy.php, or see a full list in AtoM’s
code on GitHub here.
| Taxonomy name | ID |
|---|---|
| Places | 42 |
| Subjects | 35 |
| Genres | 78 |
| Levels of description | 34 |
Examples
Sample command to return terms currently used in the Subjects taxonomy, using
the taxonomy-name option:
php symfony csv:export-term-usage --taxonomy-name="Subjects" /path/to/my-subjects.csv
The same command, but using the French name of the taxonomy:
php symfony csv:export-term-usage --taxonomy-name-culture="fr" --taxonomy-name="Sujets" /path/to/mes-sujets.csv
An example of using the taxonomy-id option to specify the Places taxonomy:
php symfony csv:export-term-usage --taxonomy-id="42" /path/to/my-places.csv
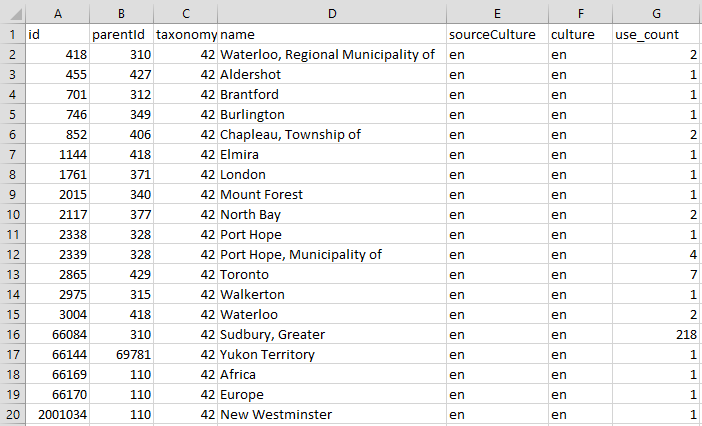
Here is the sample CSV output of a command run against the Places taxonomy in an English installation:
Auto-populate repository latitude and longitude values¶
AtoM includes the ability for users to add dynamic Google maps to the view page of a repository. To do so, a user must first have a Google API Key, and the Google Maps Javascript API key setting in Admin > Settings must be populated - see:
Once the key is added, then any time a user adds valid latitude and longitude values to the Contact area of an archival institution, AtoM will add a Dynamic Google map to the top of the repository’s view page. See:
However, you can also attempt to automatically populate existing latitude and longitude fields, based on previously entered Contact area address data (e.g. street address, city, region, postal or zip code, country, etc).
To do so, run the following command:
php symfony tools:find-repository-latlng
AtoM will begin reviewing all available repository contact information, and where possible, it will populate the latitude and longitude fields based on the address data. If any issues are encountered (such as incorrect or insufficient contact information for a lookup), the console will print an error message and move on to the next repository for lookup.
By default, the task will not overwrite existing latitude and longitude
information. However, if you would like to replace existing data with updated
values based on the task’s lookup, you can use the --overwrite option like
so:
php symfony tools:find-repository-latlng --overwrite
You may want to clear the application cache and repopulate the search index after. See:
See also
Purging all data¶
If you’re working with an AtoM installation and want to, for whatever reason, purge all data you can do this with a command-line tool:
php symfony tools:purge
Warning
This will delete ALL DATA in your AtoM instance! Be sure this is what you want to do before you proceed. You may want to back up your database first - see below
The tool will prompt you for the title and description of your site as well as
for details needed to create a new admin user. If a .gitconfig file is present
in your home directory purge will use your name and email, from that file, to
provide default values.
If you are a developer or system administrator using this task for testing purposes,
there is also a --demo option available:
php symfony tools:purge --demo
Important
Using the --demo option with the purge task will have the following
consequences:
- The task will NOT ask for confirmation before purging all data (the warning is skipped)
- It will repopulate the database with a default demo user
- Username: demo
- Email: demo@example.com
- Pass: demo
- It will add a site title to the installation - “Demo site”.
- It will NOT clear the application cache. We recommend clearing the cache and restarting all services after running this task - e.g.
php symfony cc
sudo service php5-fpm restart
Optionally, if you’re using Memcached as cache engine:
sudo service memcached restart
See Manage user accounts and user groups for information on how to edit or delete the demo user account via the user interface. See: Site information for instructions on how to edit the site title via the user interface. See Clear cache for more information on clearing the cache.
Backing up the database¶
See also
To back up a MySQL database, use the following command:
mysqldump -u myusername -p mydbname > ./mybackupfile.sql
Be sure to use your username / password / database name. To restore the database as it was during the dump command, you can suck it back in with this command:
mysql -u myusername -p mydbname < ./mybackupfile.sql
The database is now restored to the point when you dumped it.
Generate an XML sitemap for search engine optimization¶
This task will allow a system administrator with to generate an XML sitemap of your AtoM instance, to enhance search engine optimization. It uses the sitemap protocol, as described on sitemaps.org. From the site’s home page:
Sitemaps are an easy way for webmasters to inform search engines about pages on their sites that are available for crawling. In its simplest form, a Sitemap is an XML file that lists URLs for a site along with additional metadata about each URL (when it was last updated, how often it usually changes, and how important it is, relative to other URLs in the site) so that search engines can more intelligently crawl the site.
Web crawlers usually discover pages from links within the site and from other sites. Sitemaps supplement this data to allow crawlers that support Sitemaps to pick up all URLs in the Sitemap and learn about those URLs using the associated metadata. Using the Sitemap protocol does not guarantee that web pages are included in search engines, but provides hints for web crawlers to do a better job of crawling your site.
source: http://www.sitemaps.org/
This XML sitemap can then be passed to search index providers such as Google, for better indexing of your AtoM instance. Multiple sitemaps can be generated by the task to account for Google’s limits on size and/or number of nodes. If the sitemap file has more than 50,000 nodes, it will automatically be broken into multiple sitemaps.
More information:
- On the protocol: http://www.sitemaps.org/protocol.html
- Google support: https://support.google.com/webmasters/answer/183668?hl=en&ref_topic=6080646&rd=1
The task will draw the default weighting for each level of description
used in archival descriptions from a
configuration file found in config/sitemap.yml. Here are the default
weightings (or priorities) for each level included:
| Level of description | Default weight |
|---|---|
| Collection | 0.9 |
| Fonds | 0.9 |
| Subfonds | 0.8 |
| Series | 0.7 |
| Subseries | 0.6 |
| File | 0.5 |
| Item | 0.4 |
If a user adds a custom level of description to the Level of description
taxonomy (see: Terms), or if you wish to change the default
priorities, you can edit the sitemap.yml file found in the config directory.
see: config/sitemap.yml for more information.
Important
There is currently no way to add custom weights for other entities in AtoM such as authority records, archival institutions, functions, or static pages, etc.
The default weighting for new archival description levels of
description added, without a custom entry into the config/sitemap.yml
file is 0.9.
By default, authority records receive a weight of 0.5 and static pages a weight of 1.0.
When the command is run, at least 2 files are generated - by default they are
added to the root AtoM directory (though a specific location can be specified
using the task’s options - see below). A sitemap.xml file acts as a
pointer file when multiple sitemaps are produced (e.g. if there are more than
50,000 nodes, the task will automatically break this up into 2 or more XML
files, as per Google’s recommendations). If only 1 sitemap file is produced,
this pointer will still be generated, but will not be needed and can be
discarded if desired. The other file (or files) is the actual sitemap for your
AtoM instance - by default it is compressed using
Gzip, although again there is also an
option to disable this if desired.
Using the sitemap generation command-line task:
Example use:
php symfony tools:sitemap
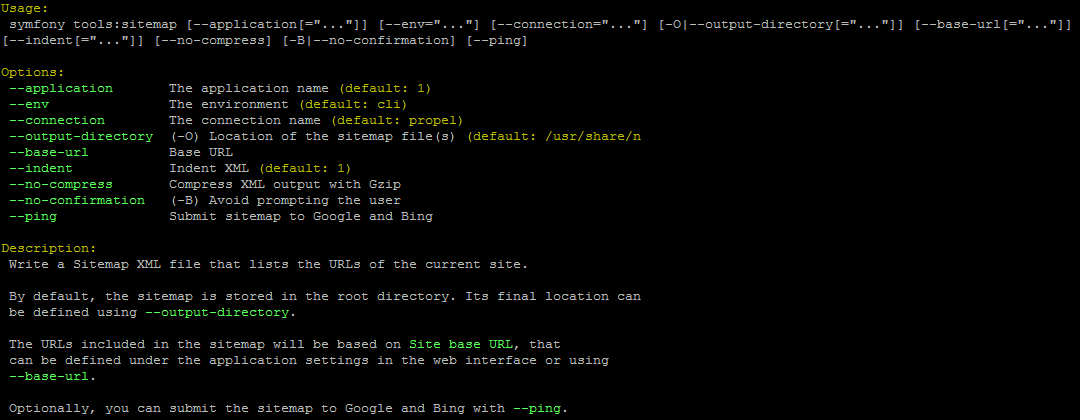
By typing php symfony help tools:sitemap into the command-line, you can
see the options available on the export:bulk command, as pictured above.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the task.
the --output-directory (or -O for short) option is used to specify a
specific location for the sitemap XML files on output - by default, they are
added to AtoM’s root directory.
The --base-url option can be used to specify a base URL for the AtoM
instance, used in the sitmap XML files generated. Note that AtoM will use the
value entered in the Admin > Settings > Site information page for the Base
URL by default, so if you’ve added the correct value there, you shouldn’t need
this option. See: Site information for more on Base URLs.
The --indent is a boolean value - by default, the XML generated will be
indented and formatted to assist human readability (e.g. --indent=1).
However, if desired, linebreaks and indentation can be removed, but adding
--indent=0 to the command
Also by default, the XML sitemap generated will be compressed using
Gzip - however, if desired, you can
prevent the compression by using the --no-compress option.
If an older sitemap already exists in the target directory when the task is
run, AtoM will ask you to confirm if you want the older versions to be
overwritten or not. If you don’t want this interruption (e.g. if you are using
this task as part of an automated deployment, etc), you can skip the
confirmation step with --no-confirmation, or -B for short.
Finally, if you would like the sitemap(s) to be submitted to Bing and Google
after generation, you can add the --ping option to the command.
See also
Manually upload Archivematica DIP objects¶
AtoM includes integration with the open source digital preservation system, Archivematica. Using Archivematica, you can generate Archival Information Packages (AIPs) for preservation, as well as Dissemination Information Packages (DIPs) for use in an access system such as AtoM. For more information, see:
- What is Archivematica?
- Upload a DIP to AtoM
- Store DIP
- Archivematica configuration for AtoM DIP upload
While a workflow that will automatically upload DIPs from Archivematica to AtoM is supported (see the links above), there may be cases where an archivist chooses to store a DIP, and then wishes to upload it later without having to run it through the re-ingest process. In that case, a system administrator can use this task to manually attach DIP objects to existing archival descriptions in AtoM.
To execute the task requires several things. First, the task expects to find DIP digital objects that have been modified by Archivematica in 2 key ways:
- The original object file has been converted to a derivative with a corresponding
file extension (e.g.
.jpg,.mp3, etc) - A Unique Universal Identifier (UUID) as been pre-pended to the file name (for
example,
815da5cf-f49f-41f5-aa5d-c40d9d4dec3c-MARBLES.jpg)
Additionally, the object names without the UUID must be unique for the
upload to succeed. If you have a number of files with the same name, we
suggest appending an incrementing number (e.g. correspondence-01,
correspondence-02, etc).
For AtoM to know where to upload the objects, you will also need to prepare a
simple CSV file. The CSV can be named anything, but must have the
extension .csv for the upload to work. The CSV must include a filename
column, which specifies the full name of each object. Additionally, include
either an identifier column (if your identifier values in AtoM are
unique) or, preferrably, a slug column, so AtoM knows the description to
which each object will be attached.

Important
Do not include both an identifier and a slug column in your CSV, or the upload may fail. You must choose one or the other - the final CSV should only have 2 columns.
The CSV should be placed in the objects directory of the DIP, with the
digital objects that will be imported. The basic syntax for the task is as
follows:
php symfony import:dip-objects /path/to/my/dip
By running php symfony help import:dip-objects we can see the help page and
options included with the task:
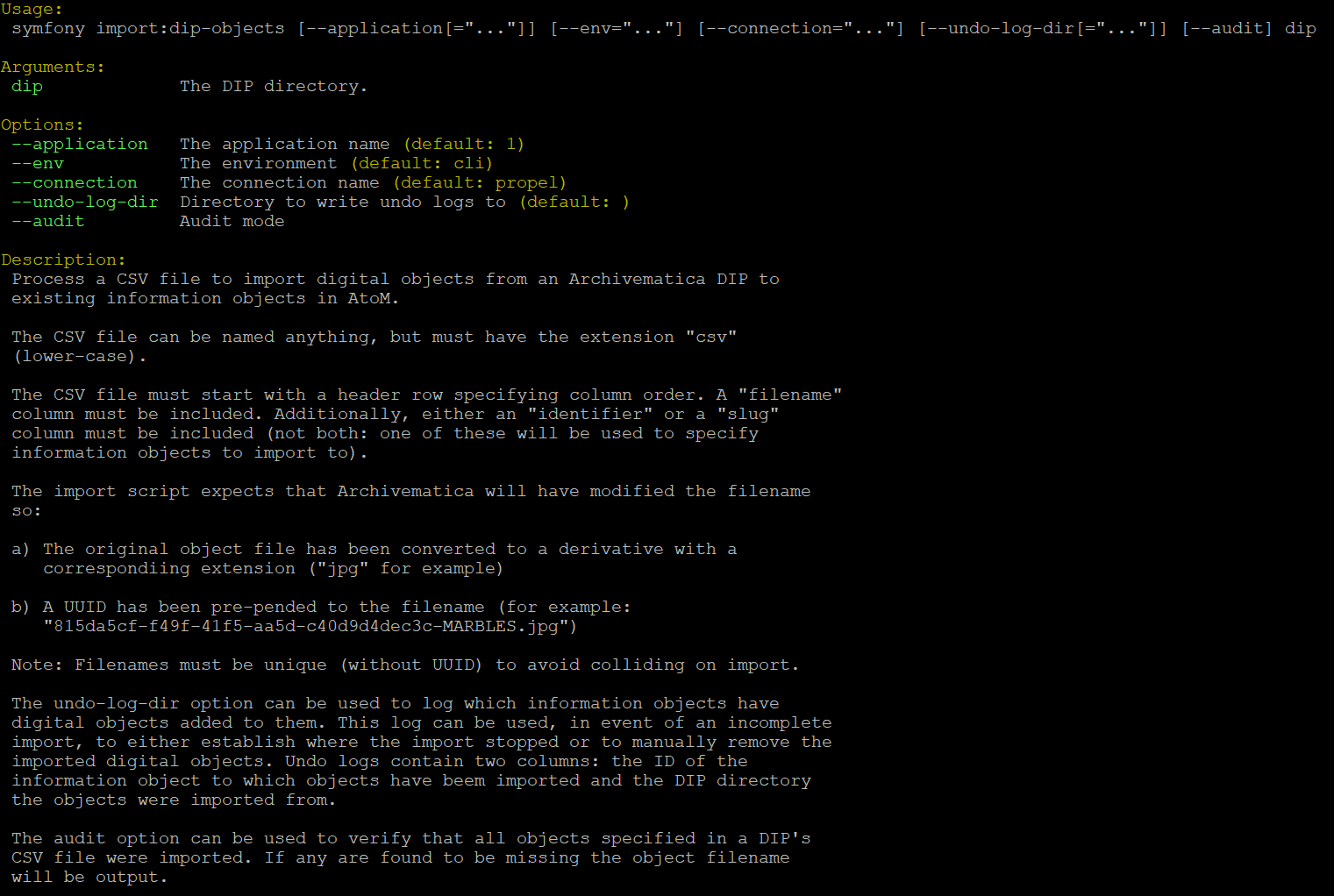
As a parameter, the task requires a file path. The path should point to the top-level directory where you have added the DIP.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for Symfony to be
able to execute the task.
The --undo-log-dir option can be used to log which information objects (aka
descriptions) have digital objects added to them as a result of running the task.
This log can be used, in event of an incomplete import, to either establish
where the import stopped or to manually remove the imported digital objects.
Undo logs contain two columns: the object ID of the information object
to which objects have beem imported, and the DIP directory from which the objects
were imported. For more information on using the object ID, you might want to
review the section below, Common AtoM database queries.
Similarly, the --audit option can be used to verify that all objects
specified in the CSV file were imported. If any are found to be missing, then the
object’s filename will be output in the console.
Common AtoM database queries¶
Occasionally manually modifying the AtoM database is required, such as when data gets corrupted from timeouts or other bugs. Here we will include a few useful queries based on common actions users wish to perform on their databases, which are not accommodated from the user interface. For all of these, you will need to execute them from inside MySQL, using the username and password you created during installation.
Assuming your username and pass are both set to “root”, here is an example of what you would type into the command-line:
$ mysql -u root -p root
Once you’ve accessed the database, you can run SQL queries to manually modify the AtoM database.
Important
We strongly recommend that you back-up all of your data prior to manipulating the database! If possible, you should test the outcome on a cloned development instance of AtoM, rather than performing these actions on a production site without testing them in advance.
Update all draft archival descriptions to published¶
Use this command to publish all draft descriptions in AtoM:
UPDATE status SET status_id=160 WHERE type_id=158 AND object_id <> 1;
Update all draft archival descriptions from a particular repository to published¶
First, retrieve the id of the repository from the slug. In this example, the repository is at http://myatomsite.com/atom/index.php/my-test-repo
SELECT object_id FROM slug WHERE slug='my-test-repo';
Assuming in this example the id returned is 123, you would then execute the following query to perform the publication status updates:
UPDATE status
SET status_id=160
WHERE type_id=158 AND status_id=159
AND object_id IN (
SELECT id FROM information_object
WHERE repository_id=123
);
Don’t forget to rebuild the search index!
php symfony search:populate
Truncate slugs to maximum character length¶
This command will truncate all slugs to a specified maximum character length. In the example below, the character length is 245.
UPDATE slug SET slug = LEFT(slug, 245) WHERE LENGTH(slug) > 245;
Delete slugs from AtoM¶
In some cases, you may wish to replace the existing slugs in AtoM - particularly if they have been randomly generated because the user-supplied data from which the slug is normally derived (e.g. the “Title” field for an archival description) was not entered when the record was created. For more information on how slugs are generated by AtoM, see above, Notes on slugs in AtoM. If you have since supplied the relevant information (e.g. added a title to your archival description), you may want to generate a new slug for it that is more meaningful.
In such a case, you will need to delete the slug in AtoM’s database first - after which you can run the command-line task to generate slugs for those without them (see above, Generate slugs). AtoM slugs are conveniently stored in a table named “slug” - if you know the slug you’d like to delete, you can use the following command to delete it from AtoM’s database (replacing your-slug-here with the slug you’d like to delete):
DELETE FROM slug WHERE slug='your-slug-here';
Important
Remember, you will run into problems if you don’t replace the slug! You can use the generate-slug task to do so; see Generate slugs, above. Remember as well: if you are trying to replace a randomnly generated slug, but you haven’t filled in the data field from which the slug is normally derived prior to deleting the old slug (see above for more on how slugs are generated in AtoM), you will end up with another randomly generated slug!
If you wanted to delete all slugs associated with descriptions (e.g. information objects) and terms, you could use the following example SQL query to delete them:
Important
Make sure you back up your data before proceeding! See: Backing up the database.
DELETE
FROM slug
WHERE (object_id IN
(SELECT id
FROM term)
OR object_id IN
(SELECT id
FROM information_object))
AND object_id <> 1;
You can then use the generate-slugs task to generate new slugs:
php symfony propel:generate-slugs
See above for further documentation on this command-line tool.
If you wanted to delete all slugs currently stored in AtoM, you could do so with the following query:
DELETE FROM slug;
Warning
This is an extreme action, and it will delete ALL slugs, including custom slugs for your static pages - and may break your application. The generate-slugs task will not replace fixtures slugs - e.g. those that come installed with AtoM, such as for settings pages, browse pages, menus, etc - or any static pages! We strongly recommend backing up your database before attempting this - see above, Backing up the database - and we recommend using SQL queries to selectively delete slugs!