Command line tools¶
There are a number of command line tools that can help you troubleshoot various AtoM problems.
See below for Common AtoM database queries.
Find out what version of AtoM you’re running¶
You can always find out what version of AtoM you have installed via the user interface by navigating to Admin > Settings > Global - the application version is the first thing listed on the Settings page. See: Application version for more information.
However, if you’d like to check the application version from the command-line, you can run the following command from AtoM’s root folder:
php symfony tools:get-version
Add a SuperUser (Admin) account¶
You can create a new administrator account from the command-line using the following command:
php symfony tools:add-superuser --email="youremail@example.com" --password="MYSUPERPASSWORD" <username>
The username should not have any spaces in it.
Change a password¶
If you need to change the password on a user account in AtoM, you can do so via the command-line.
php symfony tools:reset-password [--activate] username [password]
The username is a required value, while the password is optional - if no password is entered, AtoM will generate an 8-character temporary password to be used for the user account. AtoM will return the new password in the command-line.
Warning
We strongly recommend that these auto-generated passwords ONLY be used temporarily! They are not strong passwords - users should generate longer passwords that include special characters. For more information, see:
If the user account is currently marked inactive in the system (see
Mark a user “Inactive” for more information), you can also use the option
--activate to mark that account as active again.
See also
You can also manage user passwords through the user interface. For more information, see:
Regenerating derivatives¶
If you are upgrading to AtoM 2 from ICA-AtoM, the digital object derivatives (i.e. the reference display copy and the thumbnail generated by AtoM when a master digital object is uploaded) are set to be a different default size (i.e. they are larger in AtoM) - consequently, after an upgrade, derivatives from ICA-AtoM may appear blurry or pixellated.
As well, sometimes the digitalobject:load task used for importing digital
objects to existing descriptions (see:
Load digital objects via the command line) won’t generate the thumbnail and
reference images properly for digital objects that were loaded (e.g. due to a
crash or absence of convert installed, etc. - see under requirements,
Other dependencies (not required; recommended)). In this case, you can regenerate
these thumbsnail/reference images using the following command:
php symfony digitalobject:regen-derivatives
By typing php symfony help digitalobject:regen-derivatives into the
command-line, you can see the options available for this task:
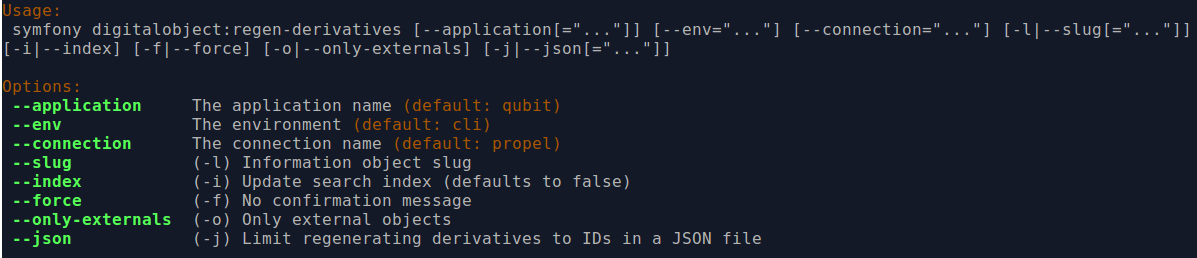
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --index option is used to enable the rebuilding of the search index as
part of the regeneration task. When running this task via the command-line
interface, indexing is disabled by default to allow the task to progress
more quickly - generally, we recommend manually clearing the cache and
rebuilding the search index following the use of this task - to do so,
from AtoM’s root directory, run:
php symfony cc && php symfony search:populate
However, if you would like to re-index as the derivative regeneration progresses,
the --index option can be used to enable this.
The --slug option can be used to target specific derivatives associated with
a description, using the description’s slug as criteria. Any
digital object attached or linked to the description whose slug is
provided as criteria will have its derivatives regenerated. Example use:
php symfony digitalobject:regen-derivatives --slug="the-jane-doe-fonds"
The --force or -f option can be used to skip the warning normally
delivered by the task when the command is entered. Because the task will delete
ALL previous derivatives - including those manually altered by editing the
thumbnail or reference display copy of a digital object via the
user interface (see: Edit digital objects for more information) - the task
will normally ask for confirmation when invoked:

However, experienced developers and system administrators can skip having to
manually confirm the procedure by using the --force (or -f for short)
option as part of the command.
The --only-externals (or -o for short) option can be used if you would
only like to attempt to regenerate the local derivatives for linked digital
objects - that is, those that have been linked via an external URI, rather than
by uploading a master digital object. For more information on linking
digital objects, see: Link a single digital object to an archival description.
The --json or -j option is for advanced users who would like to target
only a specific subset of digital objects for regeneration. With this option, a
user can supply the path to a JSON file that lists the internal
digital_object ID’s associated with the digital objects targeted and stored in
AtoM’s database. These digital_object ID’s will first need to be determined
by crafting an SQL query designed to meet your specific criteria. Help crafting
these queries is not covered here (though you can see below,
Common AtoM database queries, for a BASIC introduction to SQL queries in AtoM) - in
general, we only recommend this task be used by experienced administators.
Once you have determined the IDs of the digital objects you would like to target with the task, you can place them in square brackets in a JSON file, separated by commas, like so:
[372, 366, 423, 117]
(etc)
The criteria for the --json option then becomes the path to your JSON file:
php symfony digitalobject:regen-derivatives --json="path/to/my.json"
Warning
When running the regen-derivatives task, all of your current derivatives
for the targeted digital objects will be deleted - meaning ALL of them if you
provide no criteria such as a slug or a JSON file. They will be replaced
with new derivatives after the task has finished running. If you have
manually changed the thumbnail or reference display copy
of a digital object via the user interface (see:
Edit digital objects), these two will be replaced with digital
object derivatives created from the master digital object.
Re-indexing PDF text¶
php symfony digitalobject:extract-text
In rare situations you may want to to re-index all PDFs to make their text searchable in AtoM without having to re-import them completely. This task will go through each existing PDF imported into AtoM and re-index their contents for searches.
Rebuild the nested set¶
AtoM generally uses a relational database to store its data (we recommend MySQL). However, relational databases, which are comprised of flat tables, are not particularly suited to handling hierarchical data. As developer Mike Hillyer notes, “Hierarchical data has a parent-child relationship that is not naturally represented in a relational database table.” One method of addressing this is to employ a “Nested set model” (Wikipedia). AtoM makes use of a nested set to manage hierarchical relationships, such as between parent and child terms and descriptions.
Sometimes, during operations that involve updates to large hierarchies, the nested set can become corrupted - especially if the server times out during an operation that reaches the execution limit settings. The following task will rebuild all nested sets in AtoM:
php symfony propel:build-nested-set
Generate slugs¶
In some cases, AtoM may time out in the middle of an operation that involves the creation of new records - for example, if a user attempts to import a very large CSV file through the user interface (rather than the command-line - see: CSV import). In such cases, it is possible that AtoM has died after creating an information object, but before having a chance to create a slug for the record. This can cause unexpected errors in the application - most notably, 500 errors when trying to access the records missing slugs through the application interface.
If you want to generate slugs for records in AtoM without them, you can use the following command:
php symfony propel:generate-slugs
Note that existing slugs will not be replaced. If you want to generate new slugs for existing objects, you will need to first delete the existing slugs from the database. This can be useful for records in which a random slug has been automatically assigned, because the default user data used to generate the slug has not been provided (see below for more information on how slugs are generated in AToM).
For information on deleting slugs from AtoM’s database, see below in the section on Common AtoM database queries - particularly, Delete slugs from AtoM.
Notes on slugs in AtoM¶
A slug is a word or sequence of words which make up the last part of a URL in AtoM. It is the part of the URL that uniquely identifies the resource and often is indicative of the name or title of the page (e.g.: in www.yourwebpage.com/about, the slug is about). The slug is meant to provide a unique, human-readable, permanent link to a resource.
In AtoM, all pages based on user data (such as archival descriptions, archival institutions, authority records, terms, etc.) are automatically assigned a slug based on the information entered into the resource:
| Entity type | Slug derived from |
|---|---|
| Archival description | Title |
| Authority record | Authorized form of name |
| Accession | Identifier (accession number) |
| Other entities | Name |
Generated slugs will only allow digits, letters, and dashes. English articles (such as “the,” “a,” “an,” etc) are removed, and any other sequences of unaccepted characters (e.g. accented or special characters, etc.) are replaced with dashes. This conforms to general practice around slug creation - for example, it is “common practice to make the slug all lowercase, accented characters are usually replaced by letters from the English alphabet, punctuation marks are generally removed, and long page titles should also be truncated to keep the final URL to a reasonable length” (Wikipedia). In AtoM, slugs are truncated to a maximum of 250 characters.
If a slug is already in use, AtoM will append a dash and an incremental number (a numeric suffix) to the new slug - for example, if the slug “correspondence” is already in use, the next record with a title of “Correspondence” will receive the slug “correspondence-2”.
If a record is created without data in the field from which the slug is normally derived (e.g. an archival description created without a title), AtoM will assign it a randomly generated alpha-numeric slug. Once assigned, slugs cannot be changed through the user interface - either the record must be deleted and a new record created, or you must manipulate the database directly.
Finally, static pages, or permanent links, include a slug field option, but only slugs for new static pages can be edited by users; the slugs for the default Home page and About page in AtoM cannot be edited. New static page slugs can either be customized by users or automatically generated by AtoM if the field is left blank; AtoM will automatically generate a slug that is based on the “Title” you have indicated for the new static page. For more information on static pages in AtoM, see: Manage static pages.
Tip
For developers interested in seeing the code where slugs are handled in
AtoM, see /lib/model/QubitSlug.php
Taxonomy normalization¶
A command-line tool will run through taxonomy terms, consolidating duplicate terms. If you’ve got two terms named “Vancouver” in the “Places” taxonomy, for example, it will update term references to point to one of the terms and will delete the others.
php symfony taxonomy:normalize [--culture=<culture>] <taxonomy name>
Task options
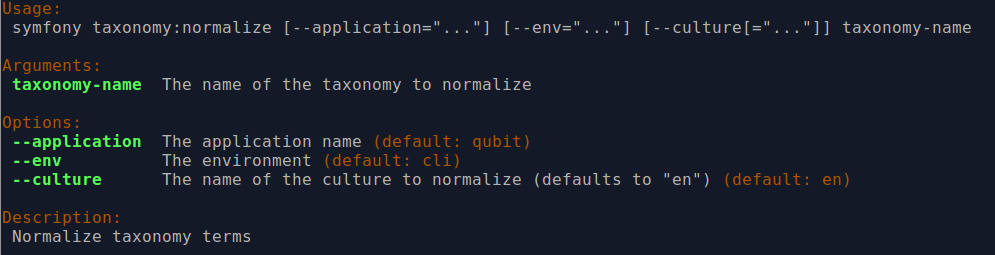
By entering php symfony help taxonomy:normalize into the command-line, you
see the options and descriptions available on this tool, as pictured above.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --culture option on this command-line tool is optional - the default
value, if none is entered is en (English). The value you
enter for <culture> should be the default culture of the terms you wish to
normalize - in most cases this will be the default culture you set up when
installing AtoM (though depending on your imports and multi-lingual use of the
application, this may not always be true) The value, if needed, should be
entered using two-letter ISO 639-1 language code values - for example,
“en” for English; “fr” for French, “it” for Italian, etc.
See Wikipedia for a
full list of ISO 639-1 language codes.
The taxonomy name value should be entered as it is seen in the user interface in Manage > Taxonomies. This value is case sensitive. If the taxonomy name has spaces (i.e. if it is more than one word), you will want to use quotation marks.
Below is an example of running this command on French terms in the Physical object type taxonomy:
php symfony taxonomy:normalize --culture="fr" "Physical object type"
You might also run this command on English terms in the Places taxonomy like so:
php symfony taxonomy:normalize Places
Update the publication status of a description¶
In AtoM, an archival description can have publication status of either “Draft” or “Published”. The publication status of a record, which can be set to either draft or published, determines whether or not the associated description is visible to unauthenticated (i.e., not logged in) users, such as researchers. It can be changed via the user interface in the administration area of a description’s edit page by a user with edit permissions. See Publish an archival description for instructions on changing this via the user interface.
If you would like to change the publication status of a record via the command-line, you can use the following command-line tool, run from the root directory of AtoM. You will need to know the slug of the description whose publication status you wish to update:
php symfony tools:update-publication-status [-f|--force] [-i|--ignore-descendants] [-y|--no-confirm] [-r|--repo] publicationStatusId slug
Notes on use¶
To update a record to Draft or Published, you must supply a publicationStatusID - that is, a fixed ID value in AtoM that represents either Draft or Published. Entering the terms “draft” or “published” will not work. Instead use the following values for the publicationStatusID:
| Publication status | statusID |
|---|---|
| Draft | 159 |
| Published | 160 |
Example use (no options) - update a description with a slug of “example-description” to published:
php symfony tools:update-publication-status 160 example-description
Task options:
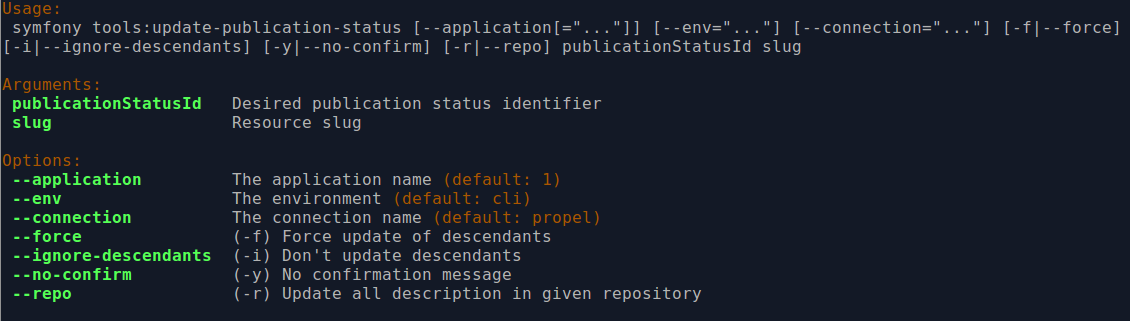
By entering php symfony help tools:update-publication-status into the
command-line, you see the options available on this tool, as pictured above.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
In general and as in the user interface, if a parent description is updated,
it will also update the publication status of its children. In some rare
cases however, there may be legacy records in the system with a publication
status of NULL. The command-line option --force, or -f for short, will
force the update of the target information object and all of its
children, including legacy records that might have a
publication status of NULL. We recommend using this option any time you want
a publication status update to affect children as well.
The --ignore-descendents, or -i, option can be used to leave the
publication status of all children unchanged. This is
useful if you have a mixture of publication statuses at lower levels - some
draft, and some published.
Normally when the command is run, AtoM will ask for a y/N confirmation before
proceeding. The --no-confirm or -y option was introduced so that
developers who are interested in using this task in a larger scripted action
can override the confirmation step.
If the --repo or -r option is used, AtoM will update the publication
status for ALL descriptions belonging to the associated
repository (e.g. archival institution). To use this option,
you must supply the slug of the repository. An information object
slug must still be present for the task to execute, but it will be ignored,
and ALL descriptions belonging to the repository will be updated instead.
Example use - updating all the descriptions associated with “My archival institution” (slug = “my-archival-institution”) to published. Note I must still provide a description slug (“my-description”) for it to execute:
php symfony tools:update-publication-status --force --repo="my-archival-institution" 160 my-description
Warning
This task is NOT designed for scalability. If you are planning on updating the publication status of thousands of records, we recommend using SQL to do so instead. We have included instructions on how to do so below - see:
Delete a description¶
You can delete a description from the command-line if you know the description’s slug. A slug is a word or sequence of words which make up a part of a URL that identifies a page in AtoM. It is the part of the URL located at the end of the URL path and often is indicative of the name or title of the page (e.g.: in www.youratom.com/this-description, the slug is this-description). When a new information object is created in AtoM, the slug for that page is generated based on the title, with spaces, stopwords, and special characters stripped out.
If you know the slug of a description you’d like to delete, use the following command to delete it from the command-line:
php symfony tools:delete-description <slug>
Delete all draft descriptions¶
If you want to remove all draft information object (e.g. archival description) records from AtoM, you can use the following command-line tool to delete all records with a publication status of “Draft”:
php symfony tools:delete-drafts
The task will ask you to confirm the operation:
>> delete-drafts Deleting all information objects marked as draft...
Are you SURE you want to do this (y/n)?
Enter “y” if you are certain you would like to delete all draft records.
Purging all data¶
If you’re working with an AtoM installation and want to, for whatever reason, purge all data you can do this with a command-line tool:
php symfony tools:purge
Warning
This will delete ALL DATA in your AtoM instance! Be sure this is what you want to do before you proceed. You may want to back up your database first - see below
The tool will prompt you for the title and description of your site as well as
for details needed to create a new admin user. If a .gitconfig file is present
in your home directory purge will use your name and email, from that file, to
provide default values.
Backing up the database¶
See also
To back up a MySQL database, use the following command:
mysqldump -u myusername -p mydbname > ./mybackupfile.sql
Be sure to use your username / password / database name. To restore the database as it was during the dump command, you can suck it back in with this command:
mysql -u myusername -p mydbname < ./mybackupfile.sql
The database is now restored to the point when you dumped it.
Bulk import of XML files¶
While XML files can be imported individually via the user interface (see: Import descriptions and terms), it may be desireable to import multiple XML files, or large files (typically larger than 1 MB) through the command line.
php symfony import:bulk /path/to/my/xmlFolder
Using the import:bulk command¶
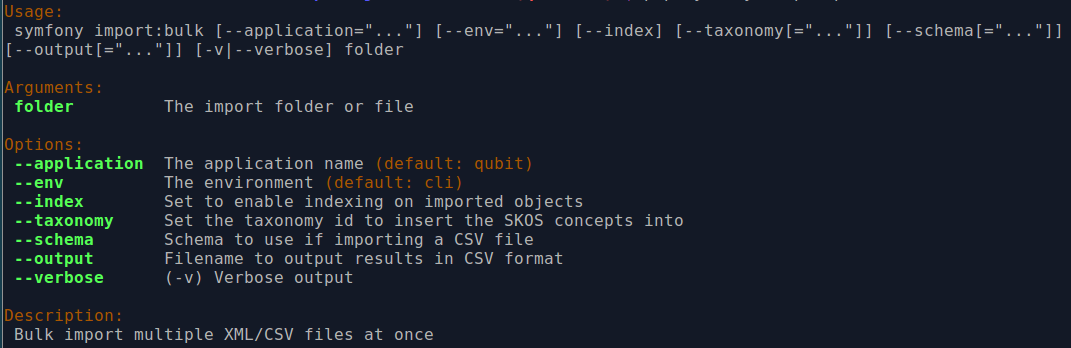
By typing php symfony help import:bulk into the command-line without
specifying the path to a directory of XML files, you can see the options
available on the import:bulk command, as pictured above.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --index option is used to enable the rebuilding of the search index as
part of the import task. When using the user interface to
import XML files, the import is indexed automatically - but when running
an import via the command-line interface, indexing is disabled by default.
This is because indexing during import can be incredibly slow, and the
command-line is generally used for larger imports. Generally, we recommend a
user simply clear the cache and rebuild the search index following an import -
from AtoM’s root directory, run:
php symfony cc & php symfony search:populate
However, if you would like to index the import as it progresses, the
--index option can be used to enable this.
The --taxonomy option is used to assist in the import of SKOS xml files,
such as places and subjects, ensuring that
the terms are imported to the correct taxonomy. As
input, the --taxonomy option takes a taxonomy ID - these are permanent
identifiers used internally in AtoM to manage the various taxonomies, which
can be found in AtoM in /lib/model/QubitTaxonomy.php (see on GitHub
here).
Example use: Importing terms to the Places taxonomy
php symfony import:bulk --taxonomy="42" /path/to/mySKOSfiles
Example use: Importing terms to the Subjects taxonomy
php symfony import:bulk --taxonomy="35" /path/to/mySKOSfiles
Below is a list of some of the more commonly used taxonomies in AtoM, and
their IDs. This list is NOT comprehensive - to see the full list, navigate to
/lib/model/QubitTaxonomy.php, or visit the Github link above.
| Taxonomy name | ID |
|---|---|
| Places | 42 |
| Subjects | 35 |
| Level of description | 34 |
| Actor entity type (ISAAR) | 32 |
| Thematic area (repository) | 72 |
| Geographic subregion (repository) | 73 |
The --output option will generate a simple CSV file containing details of
the import process, including the time elapsed and memory used during each
import. To use the option, you mush specify both a path and a filename for the
CSV file to output. For example:
php symfony import:bulk --output="/path/to/output-results.csv" /path/to/my/xmlFolder
The CSV contains 3 columns. The first (titled “File” in the first row) will list the path and filename of each imported file. The second column (titled “Time elapsed (secs)” in the first row) indicates the time elapsed during the import of that XML file, in seconds, while the third column (titled “Memory used”) indicates the memory used during the XML import of that file, in bytes. Also included, at the bottom of the CSV, are two summary rows: Total time elapsed (in seconds), and Peak memory usage (in megabytes).
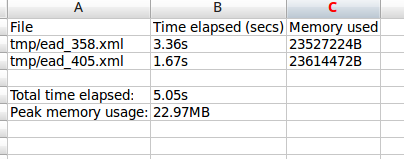
The --verbose option will return a more verbose output as each import is
completed. Normally, after the import completes, a summary of the number of
files imported, the time elapsed, and the memory used:
Successfully imported [x] XML/CSV files in [y] s. [z] bytes used."
… where [x] is the number of files imported, [y] is a count of the time elapsed in seconds, and [z] is the memory used in bytes.

If the --verbose command-line option is used (or just -v for short),
the task will output summary information for each XML file imported, rather
than a total summary. The summary information per file includes file name,
time elapsed during import ( in seconds), and its position in the total count
of documents to import. For example:
[filename] imported. [x]s [y]/[z] total
… where [x] is the time elapsed in seconds, [y] is the current file’s number and [z] is the total number of files to be imported.

Bulk export of XML files¶
While XML files can be exported individually via the user interface (see: Export descriptions and terms), it may be desireable to export multiple XML files, or large files (typically larger than 1 MB) through the command line. This can avoid browser-timeout issues when trying to export large files, and it can be useful for extracting several descriptions at the same time. XML files will be exported to a directory; you must first create the target directory, and then you will specify the path to it when invoking the export command:
php symfony export:bulk /path/to/my/xmlExportFolder
Using the export:bulk command¶
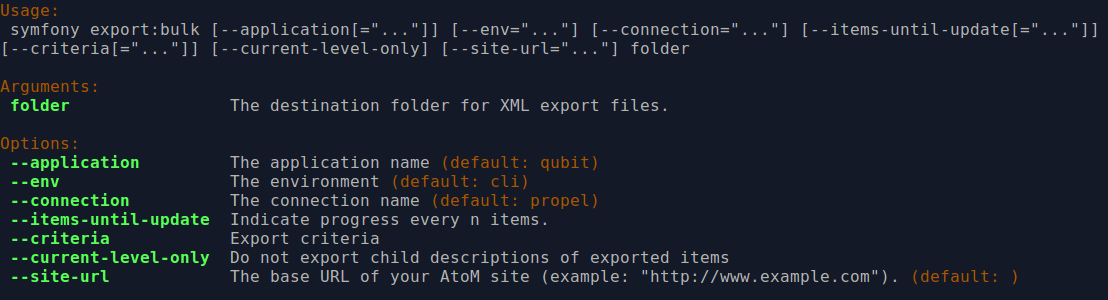
By typing php symfony help export:bulk into the command-line without
specifying the path to the target directory of exported XML files, you can see
the options available on the export:bulk command, as pictured above.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --site-url option should be used to ensure that any links included
in the resulting XML file are formed correctly. When using the
user interface, AtoM is able to receive routing information via the
web server (e.g. Nginx, Apache), but in the command-line environment, AtoM has
no way of knowing the URL to your assets. Because of this, links
included in your XML files may be incorrect. The --site-url option allows
you to specify the base URL of your site - for example, if your AtoM instance
is hosted at http://www.example.com, you can enter this as your base site
url to ensure proper routing of links in the XML output:
php symfony export:bulk --site-url="http://www.example.com" /path/to/my/xmlExportFolder
The --items-until-update option can be used for a simple visual
representation of progress in the command-line. Enter a whole integer, to
represent the number of XML files that should be exported before the
command-line prints a period (e.g. . ) in the console, as a sort of
crude progress bar. For example, entering --items-until-update=5 would
mean that the import progresses, another period will be printed every 5 XML
exports. This is a simple way to allow the command-line to provide a visual
output of progress.
Example use reporting progress every 5 rows:
php symfony export:bulk --items-until-update=5 /path/to/my/exportFolder
This can be useful for large bulk exports, to ensure the export is still progressing, and to try to roughly determine how far the task has progressed and how long it will take to complete.
The --criteria option can be added if you would like to use raw SQL to
target specific descriptions.
Example 1: exporting all draft descriptions
php symfony export:bulk --criteria="i.id IN (SELECT object_id FROM status WHERE status_id = 159 AND type_id = 158)" /path/to/my/exportFolder
If you wanted to export all published descriptions instead, you could simply
change the value of the status_id in the query from 159 (draft) to 160
(published).
Example 2: exporting all descriptions from a specific repository
To export all descriptions associated with a particular archival institution, you simply need to know the slug of the institution’s record in AtoM. In this example, the slug is “example-repo-slug”:
php symfony export:bulk --criteria="i.repository_id = (SELECT object_id FROM slug WHERE slug='example-repo-slug')" /path/to/my/exportFolder
Example 3: exporting specific descriptions by title
To export 3 fonds titled: “779 King Street, Fredericton deeds,” “1991 Canada Winter Games fonds,” and “A history of Kincardine,” You can issue the following command:
sudo php symfony export:bulk --criteria="i18n.title in ('779 King Street, Fredericton deeds', '1991 Canada Winter Games fonds', 'A history of Kincardine')" path/to/my/exportFolder
You could add additional archival descriptions of any level of description into the query by adding a comma then another title in quotes within the ()s.
The --current-level-only option can be used to prevent AtoM from exporting
any children associated with the target descriptions.
If you are exporting fonds, then only the fonds-level description
would be exported, and no lower-level records such as series, sub-series,
files, etc. This might be useful for bulk exports when the intent is to submit
the exported descriptions to a union catalogue or regional portal that only
accepts collection/fonds-level descriptions. If a lower-level description
(e.g. a series, file, or item) is the target of the export, it’s
parents will not be exported either.
See also
Common AtoM database queries¶
Occasionally manually modifying the AtoM database is required, such as when data gets corrupted from timeouts or other bugs. Here we will include a few useful queries based on common actions users wish to perform on their databases, which are not accommodated from the user interface. For all of these, you will need to execute them from inside MySQL, using the username and password you created during installation.
Assuming your username and pass are both set to “root”, here is an example of what you would type into the command-line:
$ mysql -u root -p root
Once you’ve accessed the database, you can run SQL queries to manually modify the AtoM database.
Important
We strongly recommend that you back-up all of your data prior to manipulating the database! If possible, you should test the outcome on a cloned development instance of AtoM, rather than performing these actions on a production site without testing them in advance.
Update all draft archival descriptions to published¶
Use this command to publish all draft descriptions in AtoM:
UPDATE status SET status_id=160 WHERE type_id=158 AND object_id <> 1;
Update all draft archival descriptions from a particular repository to published¶
First, retrieve the id of the repository from the slug. In this example, the repository is at http://myatomsite.com/atom/index.php/my-test-repo
SELECT object_id FROM slug WHERE slug='my-test-repo';
Assuming in this example the id returned is 123, you would then execute the following query to perform the publication status updates:
UPDATE status
SET status_id=160
WHERE type_id=158 AND status_id=159
AND object_id IN (
SELECT id FROM information_object
WHERE repository_id=123
);
Don’t forget to rebuild the search index!
php symfony search:populate
Truncate slugs to maximum character length¶
This command will truncate all slugs to a specified maximum character length. In the example below, the character length is 245.
UPDATE slug SET slug = LEFT(slug, 245) WHERE LENGTH(slug) > 245;
Delete slugs from AtoM¶
In some cases, you may wish to replace the existing slugs in AtoM - particularly if they have been randomly generated because the user-supplied data from which the slug is normally derived (e.g. the “Title” field for an archival description) was not entered when the record was created. For more information on how slugs are generated by AtoM, see above, Notes on slugs in AtoM. If you have since supplied the relevant information (e.g. added a title to your archival description), you may want to generate a new slug for it that is more meaningful.
In such a case, you will need to delete the slug in AtoM’s database first - after which you can run the command-line task to generate slugs for those without them (see above, Generate slugs). AtoM slugs are conveniently stored in a table named “slug” - if you know the slug you’d like to delete, you can use the following command to delete it from AtoM’s database (replacing your-slug-here with the slug you’d like to delete):
DELETE FROM slug WHERE slug='your-slug-here';
Important
Remember, you will run into problems if you don’t replace the slug! You can use the generate-slug task to do so; see Generate slugs, above. Remember as well: if you are trying to replace a randomnly generated slug, but you haven’t filled in the data field from which the slug is normally derived prior to deleting the old slug (see above for more on how slugs are generated in AtoM), you will end up with another randomly generated slug!
If you wanted to delete all slugs associated with descriptions (e.g. information objects) and terms, you could use the following example SQL query to delete them:
Important
Make sure you back up your data before proceeding! See: Backing up the database.
DELETE
FROM slug
WHERE (object_id IN
(SELECT id
FROM term)
OR object_id IN
(SELECT id
FROM information_object))
AND object_id <> 1;
You can then use the generate-slugs task to generate new slugs:
php symfony propel:generate-slugs
See above for further documentation on this command-line tool.
If you wanted to delete all slugs currently stored in AtoM, you could do so with the following query:
DELETE FROM slug;
Warning
This is an extreme action, and it will delete ALL slugs, including custom slugs for your static pages - and may break your application. The generate-slugs task will not replace fixtures slugs - e.g. those that come installed with AtoM, such as for settings pages, browse pages, menus, etc - or any static pages! We strongly recommend backing up your database before attempting this - see above, Backing up the database - and we recommend using SQL queries to selectively delete slugs!