Import and export from the command-line¶
AtoM supports import and export via the user interface, and these tasks are executed as jobs and performed asynchronously in the background to avoid timeouts in the browser. Jobs in AtoM are handled by Gearman, and the status of AtoM jobs can be seen in the user interface via the Manage > Jobs page. For more information, see: Manage jobs and Asynchronous jobs and worker management.
However, there may be occasions where it is more efficient to import directly from the command-line. For example, XML files can only be imported one at a time via the user interface, but the command-line task supports bulk XML import. Also the Digital object load task (described below) is only available via the command-line.
The following will outline the options available for command-line imports and exports in AtoM.
Jump to:
- Bulk import of XML files
- Bulk export of XML files
- Validate CSV files via the command-line before import
- Import CSV files via the command-line
- Audit a CSV import
- Delete descriptions created by a CSV import
- Load digital objects via the command line
- Export CSV files from the command-line
See also
The following pages in the User Manual relate to import and export. We strongly recommend reviewing the CSV preparation recommendations found on the CSV import page prior to importing CSV data.
Bulk import of XML files¶
While XML files can be imported individually via the user interface
(see: Import XML), it may be desirable to import multiple
XML files through the command line. The import:bulk command-line task can
be used to import the following types of XML data:
- MODS and EAD 2002 (for archival description data)
- SKOS RDF XML (for term data import into a taxonomy)
- EAC-CPF XML (for authority record data)
The primary documentation on preparing for XML imports, and on how matching behavior is handled for some of the import options, is maintained in the User Manual. See:
Warning
You can only import one type of XML at a time with this task. For example,
do not attempt to import EAC CPF and EAD 2002 XML at the same time.
Instead, you should import one entity type first, and then the
other with a separate import:bulk command
Below is the basic syntax for the bulk XML import task:
php symfony import:bulk /path/to/my/xmlFolder
Using the import:bulk command¶
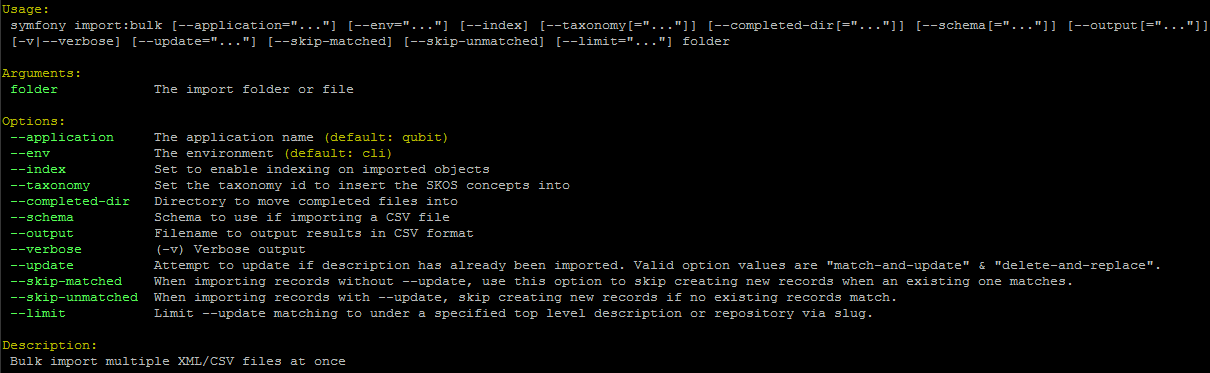
By typing php symfony help import:bulk into the command-line without
specifying the path to a directory of XML files, you can see the options
available on the import:bulk command, as pictured above.
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --index option is used to enable the rebuilding of the search index as
part of the import task. When using the user interface to
import XML files, the import is indexed automatically - but when running
an import via the command-line interface, indexing is disabled by default.
This is because indexing during import can be incredibly slow, and the
command-line is generally used for larger imports. Generally, we recommend a
user simply clear the cache and rebuild the search index following an import -
from AtoM’s root directory, run:
php symfony cc & php symfony search:populate
However, if you would like to index the import as it progresses, the
--index option can be used to enable this.
The --taxonomy option is used to assist in the import of SKOS xml files,
such as places and subjects, ensuring that
the terms are imported to the correct taxonomy. As
input, the --taxonomy option takes a taxonomy ID - these are permanent
identifiers used internally in AtoM to manage the various taxonomies, which
can be found in AtoM in /lib/model/QubitTaxonomy.php (see on GitHub
here).
Tip
SKOS imports can also be completed via the user interface from a remote URL or a local file. In the user interface, multiple SKOS serializations can be used, while only SKOS XML can be imported with this task. See the primary SKOS import documentation in the User Manual:
Example use: Importing terms to the Places taxonomy
php symfony import:bulk --taxonomy="42" /path/to/mySKOSfiles
Example use: Importing terms to the Subjects taxonomy
php symfony import:bulk --taxonomy="35" /path/to/mySKOSfiles
Below is a list of some of the more commonly used taxonomies in AtoM, and
their IDs. This list is NOT comprehensive - to see the full list, navigate to
/lib/model/QubitTaxonomy.php, or visit the GitHub link above.
| Taxonomy name | ID |
|---|---|
| Places | 42 |
| Subjects | 35 |
| Genres | 78 |
| Level of description | 34 |
| Actor entity type (ISAAR) | 32 |
| Thematic area (repository) | 72 |
| Geographic subregion (repository) | 73 |
The --completed-dir option is used to automatically move files (e.g. XML
files during an import) into a completed directory after they have imported.
This can be useful during troubleshooting, to determine which files have
imported and which have failed. The option takes a file path to the chosen
directory as its parameter. You must manually create the directory first - the
task will not automatically generate one at the specified location. Example
use:
php symfony import:bulk --completed-dir="/path/to/my/completed-directory"
/path/to/my/importFolder
The --schema option is deprecated and should not be used.
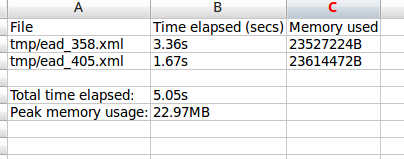
The --output option will generate a simple CSV file containing details of
the import process, including the time elapsed and memory used during each
import. To use the option, you mush specify both a path and a filename for the
CSV file to output. For example:
php symfony import:bulk --output="/path/to/output-results.csv"
/path/to/my/importFolder
The CSV contains 3 columns. The first (titled “File” in the first row) will list the path and filename of each imported file. The second column (titled “Time elapsed (secs)” in the first row) indicates the time elapsed during the import of that XML file, in seconds, while the third column (titled “Memory used”) indicates the memory used during the XML import of that file, in bytes. Also included, at the bottom of the CSV, are two summary rows: Total time elapsed (in seconds), and Peak memory usage (in megabytes).
The --verbose option will return a more verbose output as each import is
completed. Normally, after the import completes, a summary of the number of
files imported, the time elapsed, and the memory used:
Successfully imported [x] XML/CSV files in [y] s. [z] bytes used."
… where [x] is the number of files imported, [y] is a count of the time elapsed in seconds, and [z] is the memory used in bytes.

If the --verbose command-line option is used (or just -v for short),
the task will output summary information for each XML file imported, rather
than a total summary. The summary information per file includes file name,
time elapsed during import ( in seconds), and its position in the total count
of documents to import. For example:
[filename] imported. [x]s [y]/[z] total
… where [x] is the time elapsed in seconds, [y] is the current file’s number and [z] is the total number of files to be imported.

The --update option can be used when you want to use an XML import to
update existing archival descriptions, instead of creating new records. There
are 2 modes, but only the --update="delete-and-replace mode is supported
for XML imports. When used, AtoM will attempt to identify matching records,
and then delete the match before proceeding with the XML import as a new
record. For more information on how AtoM attempts to match incoming XML
imports to existing records, see:
Important
The --update option will only work with EAC-CPF and EAD 2002 XML
imports. It cannot be used for MODS or SKOS XML imports via the
command-line. Only the “Delete and replace” mode will work with the update
option.
Related enities that were linked to the matched and deleted records are not also deleted - if you want them removed, they must be manually deleted separately. Similarly, on import of the replacement record(s), recreating the previous links to other related entities is not guaranteed - AtoM proceeds with the replacement import as if it were new, and uses the matching and linking criteria described in the links above to determine if it should link to existing related entities or create new ones.
We strongly recommend you review the User Manual documentation, as it contains further details:
The --limit option can be used with --update to increase the
likelihood of a successful match by limiting the match criteria to either
records belonging to a specific repository, or matching a specific existing
top-level description (for archival description imports). For more
information on how entities can be linked to a repository, see:
- Link an archival description to an archival institution
- Link an authority record to a repository as its maintainer
The --limit option takes the slug of the related repository
or top-level archival description as its value. For example, to
import a folder of EAD 2002 XML descriptions called “my-updates”, deleting
any existing matches but limit the matching criteria to those descriptions
linked to a repository with the slug “my-repository”, your command might
look like this:
php symfony import:bulk --update="delete-and-replace" --limit="my-repository"
/path/to/my-updates
Important
The --limit option can only be used in conjunction with the
--update="delete-and-replace" option. This means it can only be used
for EAD 2002 and EAC-CPF XML. When importing EAC-CPF
authority record data, you can only use a repository slug as the
limiter. See the links above to the primary User Manual documentation for
more information.
Normally, when attempting to match records, if AtoM fails to find a match
candidate, it will proceed to import the row as a new record. However, you can
use the --skip-unmatched option with --update to change this default
behavior. When --skip-unmatched is used, then any records that do not
match will be ignored during the import, and reported in the console log shown
on the Job details page of the related import job (see:
Manage jobs for more information). This is recommended if you are
intending to only import updates to existing records. Note that
--skip-unmatched will not work if it is not used in conjunction with the
--update option.
Similarly, with new imports, you can use the --skip-matched option to skip
any records that AtoM identifies as matching those you have already imported.
This can be useful if you are uncertain if some of the XML records
have been previously imported - such as when passing records to a portal site
or union catalogue. Any XML data that appear to match records will be ignored
during the import, and reported in the console log shown on the
Job details page of the related import job. For more
information on how AtoM attempts to match incoming imports to
existing records, see:
Bulk export of XML files¶
While XML files can be exported individually via the user interface (see: Export XML), it may be desirable to export multiple XML files, or large files (typically larger than 1 MB) through the command line. This can avoid browser-timeout issues when trying to export large files, and it can be useful for extracting several descriptions at the same time. XML files will be exported to a directory; you must first create the target directory, and then you will specify the path to it when invoking the export command:
php symfony export:bulk /path/to/my/xmlExportFolder
Note
There is also a separate bulk export command for EAC-CPF XML files (e.g. for exporting authority records via the command-line. It uses the same CLI options as the EAD XML export task. See below below for syntax; see the EAD usage guidelines for how to use the available options.
Important
The Inherit reference code (information object) setting also determines how the
<unitid> element in the EAD XML is populated. If the inheritance is
turned on, then AtoM will populate all descendant records in the EAD XML
with the full inherited reference code. If inheritance is turned off, AtoM
will only add the identifier for that record in the <unitid> on export.
This allows users exporting to a different source system that does not have
a reference code inheritance setting to maintain a full reference code at
all levels in the target system. However, if you are exporting from one
AtoM instance to another (for example, from a local institution to a
portal site), you might want to consider how this will impact your record
display in the target system - if you have reference code inheritance
turned on when you export, and the target AtoM instance also has the
setting turned on, you may end up with duplication in the display!
Using the export:bulk command¶
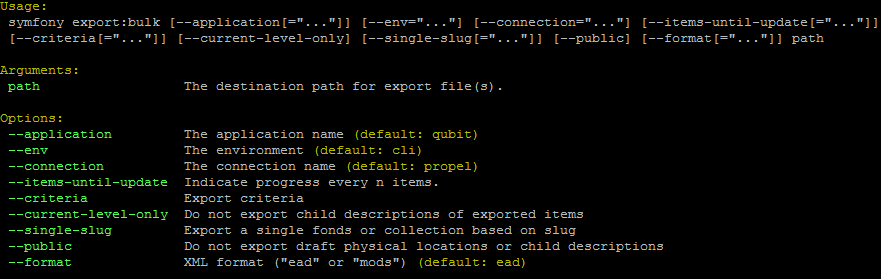
By typing php symfony help export:bulk into the command-line without
specifying the path to the target directory of exported XML files, you can see
the options available on the export:bulk command, as pictured above.
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --items-until-update option can be used for a simple visual
representation of progress in the command-line. Enter a whole integer, to
represent the number of XML files that should be exported before the
command-line prints a period (e.g. . ) in the console, as a sort of
crude progress bar. For example, entering --items-until-update=5 would
mean that the import progresses, another period will be printed every 5 XML
exports. This is a simple way to allow the command-line to provide a visual
output of progress.
Example use reporting progress every 5 rows:
php symfony export:bulk --items-until-update=5 /path/to/my/exportFolder
This can be useful for large bulk exports, to ensure the export is still progressing, and to try to roughly determine how far the task has progressed and how long it will take to complete.
The --format option will determine whether the target export uses EAD XML,
or MODS XML. When not set, the default is to export using EAD. Example use:
php symfony export:bulk --format="mods" /path/to/my/exportFolder
The --criteria option can be added if you would like to use raw SQL to
target specific descriptions.
Example 1: exporting all draft descriptions
php symfony export:bulk --criteria="i.id IN (SELECT object_id FROM status
WHERE status_id = 159 AND type_id = 158)" /path/to/my/exportFolder
If you wanted to export all published descriptions instead, you could simply
change the value of the status_id in the query from 159 (draft) to 160
(published).
Example 2: exporting all descriptions from a specific repository
To export all descriptions associated with a particular archival institution, you simply need to know the slug of the institution’s record in AtoM. In this example, the slug is “example-repo-slug”:
php symfony export:bulk --criteria="i.repository_id = (SELECT object_id FROM
slug WHERE slug='example-repo-slug')" /path/to/my/exportFolder
Example 3: exporting specific descriptions by title
To export 3 fonds titled: “779 King Street, Fredericton deeds,” “1991 Canada Winter Games fonds,” and “A history of Kincardine,” You can issue the following command:
sudo php symfony export:bulk --criteria="i18n.title in ('779 King Street,
Fredericton deeds', '1991 Canada Winter Games fonds', 'A history of
Kincardine')" path/to/my/exportFolder
You could add additional archival descriptions of any level of description into the query by adding a comma then another title in quotes within the ()s.
The --current-level-only option can be used to prevent AtoM from exporting
any children associated with the target descriptions.
If you are exporting fonds, then only the fonds-level description
would be exported, and no lower-level records such as series, sub-series,
files, etc. This might be useful for bulk exports when the intent is to submit
the exported descriptions to a union catalogue or regional portal that only
accepts collection/fonds-level descriptions. If a lower-level description
(e.g. a series, file, or item) is the target of the export, it’s
parents will not be exported either.
The --single-slug option can be used to to target a single archival
unit (e.g. fonds, collection, etc) for export, if you know the slug of
the target description.
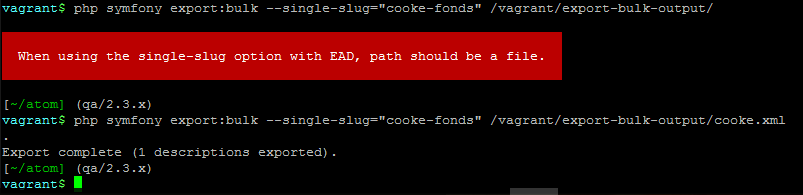
Example use
php symfony export:bulk --single-slug="test-export"
/path/to/my/directory/test-export.xml
Important
For the export task to succeed when using the --single-slug option, you
must specify not just a target output directory, but a target output file
name. Exporting to path/to/my/directory/ will result in nothing being
exported - you will be given a warning that the path should be a file -
while exporting to path/to/my/directory/some-filename.xml will succeed.
Note that the task cannot create new directories - but you can give the
target file any name you wish (ending in .xml); it doesn’t need to be
based on the target slug.
The --public option is useful for excluding draft records from an export.
Normally, all records in a hierarchical tree will be exported regardless of
publication status. Note that if a published record is the child of a
draft record, it will not be included when this option is used - when the
parent is skipped (as a draft record), the children are also skipped, so as not
to break the established hierarchy.
See also
Exporting EAC-CPF XML for authority records¶
In addition to the bulk export CLI tool for archival descriptions described above, AtoM also has a separate command-line task for the bulk export of authority records in EAC-CPF XML format.
The EAC-CPF XML standard is prepared and maintained by the Technical Subcommittee for Encoded Archival Context of the Society of American Archivists and the Staatsbibliothek zu Berlin, and a version of the Tag Library is available at:
When using the task, EAC-CPF XML files will be exported to a directory; you must first create the target directory, and then you will specify the path to it when invoking the export command:
php symfony export:auth-recs /path/to/my/xmlExportFolder
The authority record bulk export task has the same options available as the
archival description export task described above.
Some of these options will not be relevant to EAC-CPF exports (e.g. the
--current-level-only option, as authority records are not hierarchical; and
the --public option, as currently authority records do not have a
publication status), but otherwise they can be used with this task in the same
way as described for the archival description export options
above. Please refer there for more detailed usage
notes. Below is an example application, using the --criteria option:
Example: using the --criteria option to select only authority records
whose entity type is “family”
First, you will need to know the entity type ID for family. Entity type is a term maintained in the Actor entity types taxonomy - when elements from a different table in the database are linked to actors, the term ID is used. Here are the term object IDs for the Actor entity types:
| Term | Term ID |
|---|---|
| Corporate body | 131 |
| Person | 132 |
| Family | 133 |
Tip
An easy way to figure this out in the user interface is to use the related Entity type facet on the authority record browse page, and look at the resulting URL. For example, if we go to the public AtoM demo site, navigate to the Authority record browse page, and use the facet to limit the results to those records with an Entity type of family, the resulting URL is:
See the 133 in the URL? This represents the Entity type we have applied
to filter the results!
We can now use the entity type to limit our export to include only those authority records with an entity type of “Family,” like so:
php symfony export:auth-recs --criteria='a.entity_type_id=133'
path/to/my/export-folder
Validate CSV files via the command-line before import¶
To help users avoid bad imports and unexpected outcomes, AtoM supports two CSV validation tasks that can be run in advance of an import. The first task provides general validation, and also includes support in the user interface - for more information on CSV validation via the user interface, see:
The second task, currently only supported via the command-line, can be used to help review import files that import digital objects, to ensure that the digital object files match what is found in the accompanying import CSV.
Jump to:
Validate a CSV import file via the command-line¶
This task can be run prior to import as a way of checking for common issues in CSV formatting and data preparation. Unlike the validation option supported via the user interface, the command-line task can also be pointed at a directory of CSV files to perform bulk CSV validation instead of one file at a time. However, while the user interface supports a downloadable text file report of the validation output, the command-line task will currently only output results in the console.
Details on how to interpret the results included in the console report can be found in the User Manual, here:
The basic syntax for running the validation task against a single CSV is:
php symfony csv:check-import /path/to/my/file.csv
To run validation against multiple CSVs at once, place them in a common directory accessible by AtoM and provide a path to the directory itself, instead of to an individual CSV:
php symfony csv:check-import /path/to/my/directory/
See also
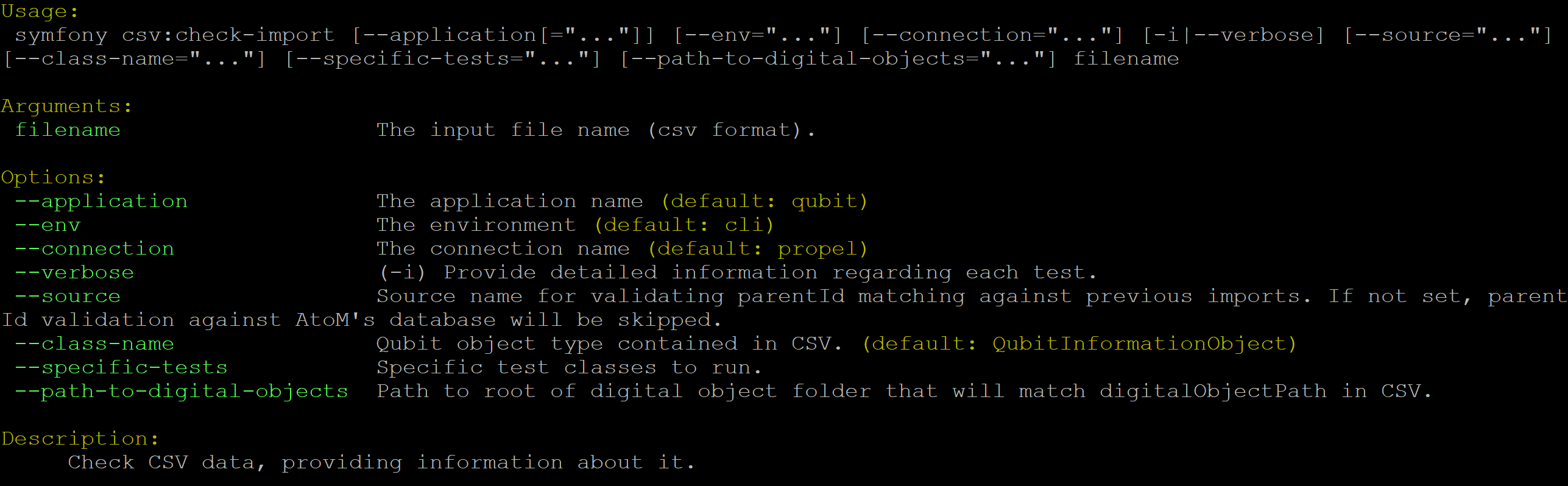
By typing php symfony help csv:check-import into the command-line from
your root AtoM installation directory without specifying the location of a
CSV, you will able able to see the CSV import options available (pictured
above). A brief explanation of each is included below.
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the task.
The task includes two output options for the validation results - a shorter
report version that does not include a sample output row and in some cases
includes less details on each test outcome (and which matches what is shown in
the console log on the job details page when run via the
user interface), and a more detailed version with additional
information intended to help you locate reported issues. If the task is run
without options, the short report will be the default used. However, if you
would like to see the more detailed report, you can add the --verbose
(or -i for short) flag to the task, like so:
php symfony csv:check-import --verbose /path/to/my/file.csv
Tip
If you are not sure how to locate issues reported during validation in your
CSV, we recommend running the validation task again using the --verbose
option, as it will include additional information (such as row numbers,
problem values, etc) that should help you know where to look in the CSV
file to review and resolve issues.
For archival descriptions, the task can provide
some basic checks on the legacyID and parentID columns used to structure
hierarchical data in the CSV, to ensure that all parentID values match a
legacyID value found in the CSV. However, since CSV imports can also be
used as updates to existing records, the --source option can be used to
provide a source name value, that will then be used to check for matches in
AtoM’s database in the keymap table from prior imports if no matches are
found in the CSV.
Tip
For more information on source names, the keymap table, and CSV import updates, see:
The value provided with the --source option should match the source name
value used during previous imports - AtoM will use this value to look for a
match in the keymap table, and will then be able to check if parentID
values in the CSV being validated match legacyID values from prior imports
with the matching source name as well.
By default, the validation task expects archival description CSVs as
input to be validated - at present, this entity type has the most
comprehensive set of tests. However, most of the tests can be run on any CSV
import type, such as checking for UTF-8 encoding and proper line endings;
checking culture values; etc. The --class-name option can be used to specify
a different entity type of CSV to validate. Supported options include:
QubitInformationObject: archival description CSV (default)QubitActor: authority record CSVQubitAccession: accession record CSVQubitRepository: archival institution record CSVQubitEvent: event data CSV (used to add actor-description events via import)QubitRelation-actor: authority record relationship CSV
For example, to validate a CSV of authority record data, the basic task syntax would look something like the following:
php symfony csv:check-import --class-name="QubitActor" /path/to/my/authorities.csv
Run without additional options, all supported tests will be run for the selected
entity when validating a CSV. However, the --specific-tests option
can be used to specify only a subset of checks that should be performed when the
task is executed. A brief summary of the test class names and relevant entity
types is provided below - for more detailed information on each test,
see the User Manual: CSV Validation.
| Test class name | Supported entity type(s) |
|---|---|
| CsvSampleValuesValidator | All entities |
| CsvFileEncodingValidator | All entities |
| CsvColumnNameValidator | All entities |
| CsvColumnCountValidator | All entities |
| CsvDigitalObjectPathValidator | QubitInformationObject |
| CsvDigitalObjectUriValidator | QubitInformationObject |
| CsvDuplicateColumnNameValidator | All entities |
| CsvEmptyRowValidator | All entities |
| CsvCultureValidator | All entities |
| CsvLanguageValidator | QubitInformationObject, QubitRepository |
| CsvFieldLengthValidator | All entities |
| CsvParentValidator | QubitInformationObject |
| CsvLegacyIdValidator | QubitInformationObject |
| CsvEventValuesValidator | QubitInformationObject |
| CsvScriptValidator | QubitInformationObject |
| CsvRepoValidator | QubitInformationObject |
You can include more than one test class name using the --specific-tests
option, by separating each test class name by a comma. An example:
php symfony csv:check-import --specific-tests="CsvSampleValuesValidator,CsvColumnNameValidator" /path/to/my/import.csv
Finally, the --path-to-digital-objects option can be used when importing
archival description records that include a digital object
path in the digitalObjectPath CSV column. To import local digital objects
using this CSV column, the digital objects must be available somewhere on
the local file system - for more information on including digital objects in
CSV imports, see:
The --path-to-digital-objects option can then be used to include the path
to where the related digital objects are located on the local filesystem, so that
further validation checks can be run against them. Possible check outputs
include:
- INFO: The
digitalObjectPathcolumn is not present in the CSV file. - ERROR: The path to the digital object directory specified in the validation task option cannot be found or accessed
- WARNING: A
digitalObjectURIvalue is also specified in the CSV for a given row. Note that in such a case, if you proceed with the import, AtoM will favor thedigitalObjectURIcolumn value and ignore thedigitalObjectPathvalue for the target row. - WARNING: There are digital objects in the folder that are not referenced by the CSV. These will not be imported if you proceed with the CSV import.
- ERROR: There are digital objects specified in the CSV that cannot be found in the related objects directory. The import will fail at this point if you attempt to proceed.
- WARNING: A digital object is referred to more than once in the CSV.
If you choose to proceed, here are some notes on the outcome:
- Only one master digital object will be stored. Clicking through on the reference display copy of the digital object shown on the description view page of each record will point to the same master.
- Each description will have its own unique derivatives - this means you can delete the thumbnail and/or the reference display copy associated with one description without impacting the others
- Deleting the master digital object on one description will not
automatically delete it everywhere - other descriptions are unaffected, and
the digital object will not actually be removed from the filesystem’s
uploadsdirectory until all description relations are deleted.
An example of running the task when providing a path to a digital objects directory:
php symfony csv:check-import --path-to-digital-objects="/usr/share/nginx/atom/my-upload-files" /path/to/my/import.csv
See also
For specific information on the validation outputs for the
digitalObjectPath checks, see:
There is also a separate command-line task that can be used to check the filepaths associated with a digital object upload, that can be used when using the digital object load task. See below for more information:
For more information on all the validation tests the task can run and how to interpret the results, please see:
Check filepaths before importing digital objects¶
In addition to the general CSV validation task, AtoM also includes a command-line task to help double-check import files that involve digital objects. The task will take the path to a CSV file and the path to a directory of digital objects as inputs, and will report on potential errors, such as:
- Any digital objects in the filesystem directory that aren’t referenced in the CSV data
- Any digital objects that are referenced in CSV data but missing on the filesystem
- Any digital objects that are referenced more than once in the CSV data
This can be a useful way of verifying archival description or
authority record CSV imports that use the digitalObjectPath column
to link local digital objects during the import, or for double-checking the
CSV accompanying a digital object load, before
you actually import your data.
See also
The basic syntax of the task is:
php symfony csv:digital-object-path-check path/to/objects/directory path/to/csv-file.csv
Where path/to/objects/directory is the path to where your digital object
directory is located on the server, and path/to/csv-file.csv is the path
to the CSV file with your import metadata.
By default, this task expects the column in the CSV with the digital object
file paths to be named digitalObjectPath, as it is in the description and
authority record CSV templates. However, the task also includes one user option,
--csv-column-name, that can be used to specify a different CSV column to
check. This allows you to use the task to review a
digital object load task CSV for example,
which uses a column named filename instead. An example:
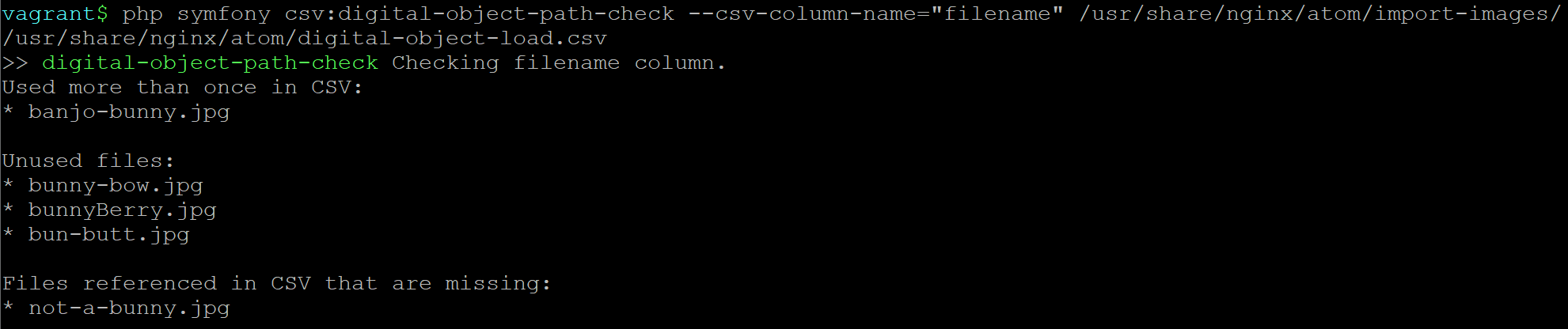
php symfony csv:digital-object-path-check --csv-column-name="filename" /usr/share/nginx/atom/import-images/ /usr/share/nginx/atom/digital-object-load.csv
An example of the task output:
Import CSV files via the command-line¶
As of AtoM 2.4, the import and export functionality in the user interface is supported by the job scheduler, meaning that large CSV files can be imported via the user interface without timing out as in previous versions. However, there are some options available via the command-line that do not have equivalents in the user interface. For this reason, there may be times when it is preferable to import a CSV records via the CLI. Below are basic instructions for each available import type.
Jump to:
- Importing archival descriptions
- Importing events
- Importing repository records
- Importing authority records
- Import authority record relationships
- Import accession records
- Import deaccession records
- Import physical storage containers and locations
- Display the progress of an upload via the command-line interface (CLI)
- Load digital objects via the command line
You can find all of the CSV templates on the AtoM wiki, at:
Examples are also stored directly in the AtoM codebase - see:
lib/task/import/example
Important
Please carefully review the information included on the CSV import page prior to attempting a CSV import via the command-line! Here is a basic checklist of things to review before importing a CSV:
- You are using the correct CSV template for both the type of record you want to import, and for the version of AtoM you have installed. You can
- CSV file is saved with UTF-8 encodings
- CSV file uses Linux/Unix style end-of-line characters (
/n) - All parent descriptions appear in rows above their children if you are importing hierarchical data (such as descriptions)
AtoM also supports a CSV validation task that can be run from the command-line or the user interface, that can help identify common errors in CSVs prior to import. For more information, see:
The CSV import User manual documentation includes more specific guidance for preparing a CSV for each entity type - ensure you have reviewed it carefully prior to import.
All CSV import command-line tasks should be run from the root AtoM directory.
Importing archival descriptions¶
Example syntax use (with the RAD CSV template):
php symfony csv:import lib/task/import/example/rad/example_information_objects_rad.csv
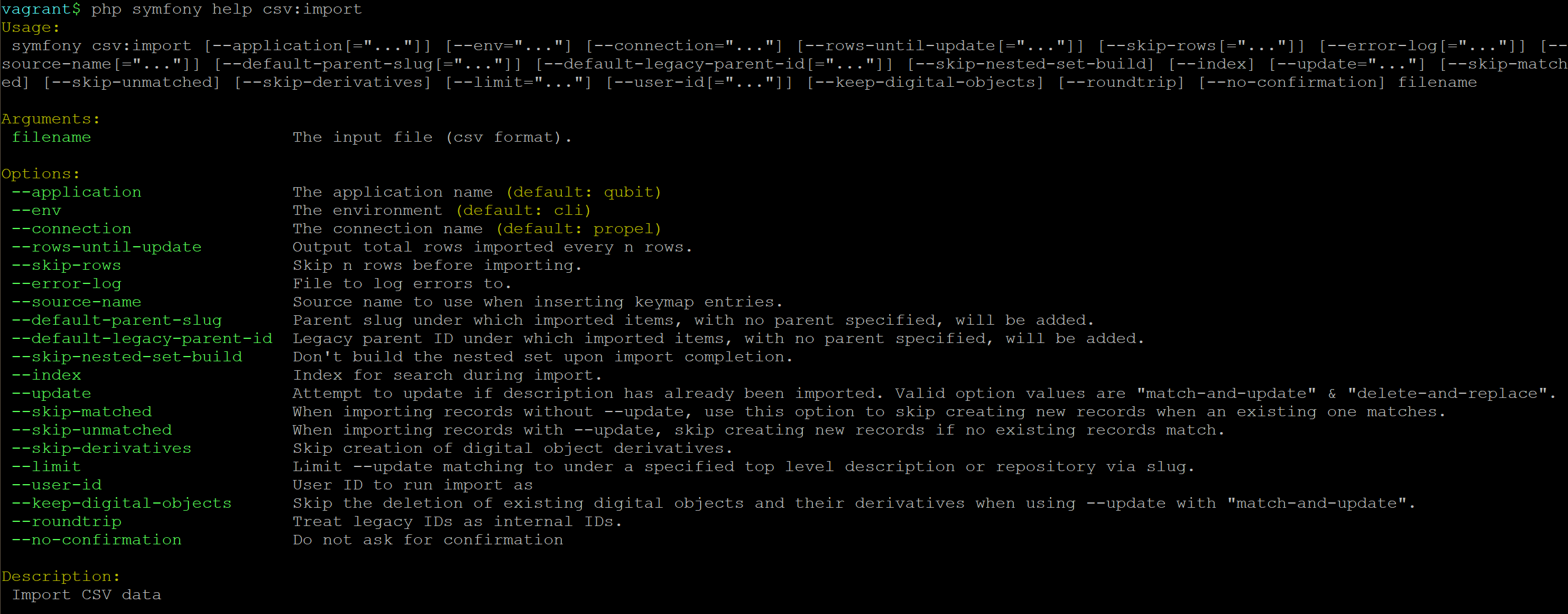
By typing php symfony help csv:import into the command-line from your root
directory, without specifying the location of a CSV, you will able able to
see the CSV import options available (pictured above). A brief explanation of
each is included below. For full archival description CSV import
documentation, please see:
- Prepare archival descriptions for CSV import
- Import new archival descriptions via CSV
- Fields that will support update imports
- Update existing descriptions via CSV import
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update option can be used for a simple visual
representation of progress in the command-line. Enter a whole integer, to
represent the number of rows should be imported from the CSV before the
command-line prints a period (e.g. `` . `` ) in the console, as a sort of
crude progress bar. For example, entering --rows-until-update=5 would
mean that the import progresses, another period will be printed every 5 rows.
This is a simple way to allow the command-line to provide a visual output of
progress. For further information on the --rows-until-update option and an
example of the command-line option in use, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
You can use the --skip-rows option to skip X amount of rows in the CSV
before beginning the import. This can be useful if you have interrupted the
import, and wish to re-run it without duplicating the records already
imported. --skip-rows=10 would skip the first 10 rows in the CSV file,
for example. Note that this count does not include the header column, so
in fact, the above example would skip the header column, and rows 2-11 in
your CSV file.
The --error-log option can be used to specify a directory where errors
should be logged. Note that this option has not been tested by Artefactual
developers.
Use the --source-name option (described in the CSV import
documentation here) to specify a source when
importing information objects from multiple sources (with possibly conflicting
legacy IDs), or when importing updates, to match the previous import’s source
name. This will ensure that multiple related CSV files will remain related -
so, for example, if you import an archival description CSV, and then
supplement the authority records created (from
the eventActors field in the description CSV templates) with an authority
record CSV import, using the --source-name option will help to make sure
that matching names are linked and related, instead of duplicate authority
records being created. You can also use this option to relate a large import
that is broken up into multiple CSV files, or when importing updates to existing
descriptions. See the Legacy ID mapping: dealing with hierarchical data in a CSV section in the User manual
for further tips and details on the uses of this option.
Tip
When no --source-name is set during import, the filename of the CSV
will be used by default instead.
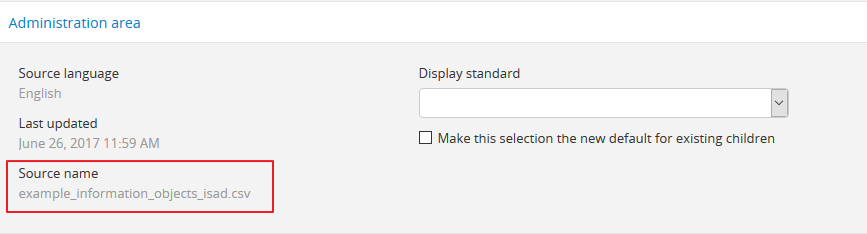
You can always check what source name was used for records created via an import by entering into edit mode and navigating to the Administration :term:` area <information area>` of the edit page - the source name used will be displayed there:
The --default-legacy-parent-id option will allow the user to set a default
parentID value - for any row in the CSV where no parentID value is
included and no qubitParentSlug is present, this default value will be
inserted as the parentID.
Similarly, the --default-parent-slug option allows a user to set a
default qubitParentSlug value - wherever no slug value or parentID /
legacyID is included, AtoM will populate the qubitParentSlug with the
default value. If you are importing all rows in a CSV file to one parent
description already in AtoM, you could use the --default-parent-slug option
to specify the target slug of the parent, and then leave the legacyID,
parentID, and qubitParentSlug columns blank in your CSV. Note that this
example will affect ALL rows in a CSV - so use this only if you are
importing all descriptions to a single parent!
By default, AtoM will build the nested set after an import task. The
nested set is a way to manage hierarchical data stored in the flat tables of a
relational database. However, as Wikipedia notes, “Nested sets are very slow for
inserts because it requires updating left and right domain values for all
records in the table after the insert. This can cause a lot of database thrash
as many rows are rewritten and indexes rebuilt.” When performing a large import,
it can therefore sometimes be desirable to disable the building of the nested
set during the import process, and then run it as a separate command-line task
following the completion of the import. To achieve this, the
--skip-nested-set-build option can be used to disable the default behavior.
NOTE that the nested set WILL need to be built for AtoM to behave as expected. You can use the following command-line task, from the AtoM root directory, to rebuild the nested set if you have disabled it during import:
php symfony propel:build-nested-set
The task is further outlined on the Command line tools page - see: Rebuild the nested set.
Tip
Want to learn more about why and how nested sets are used? Here are a few great resources:
- Mike Hyllier’s article on Managing Hierarchical data in MySQL
- Evan Petersen’s discussion of nested sets
- Wikipedia’s Nested set model
Similarly, when using the user interface to perform an import, the import is indexed automatically - but when running an import via the command-line interface, indexing is disabled by default. This is because indexing during import can be incredibly slow, and the command-line is generally used for larger imports. Generally, we recommend a user simply clear the cache and rebuild the search index following an import - from AtoM’s root directory, run:
php symfony cc && php symfony search:populate
However, if you would like to index the import as it progresses, the
--index option can be used to enable this. This is useful if you have a
large database, and don’t want to have to re-index everything. For more
information on indexing options, see: Populate search index.
The --update option can be used when you want to use a CSV import to
update existing archival descriptions, instead of creating new records. There
are 2 modes: --update="match-and-update" and
--update="delete-and-replace. When used, AtoM will attempt to identify
matching archival descriptions and, depending on which option is used, either
update them in place, or delete the match and replace it with the new
description in the CSV. For more information on how AtoM attempts to match
incoming imports to existing descriptions, see:
Matching criteria for archival descriptions.
For the “match-and-update” option, AtoM will update any information object related columns that have new data. Columns in the related CSV row that are left blank will not delete existing data - instead, they will be ignored and any existing data in the related field will be preserved.
Important
AtoM can only update description fields that are stored in the primary information object database tables using this method. This means that related entities (such as events, creators, access points, etc.) cannot be deleted or updated with this method. You can add additional related entities, but the old ones will be left in place. There is code to prevent duplication however - so if you have left the same creator/event information as previously, it will be ignored.
For more information on supported fields for updating, see:
The one exception to this is updating the biographical or administrative history of a related authority record, which requires specific criteria. See scenario 2B in the following section of the User manual: Attempting to match to existing authority records on import.
Additionally, in AtoM notes are stored in a different database table - this includes the General note, Archivist’s note, and the RAD- and DACS-specific note type fields in AtoM’s archival description templates. This means that in addition to related entities, notes cannot be deleted or updated with this method, though again, you can append new notes if desired.
If you wish to make updates to these entities or fields, consider using the “Delete and replace” update option instead - though be sure to read up on the behavior and limitations of that method as well!
Finally, note that without the --rountrip option (described below),
title, identifier, and repository may be used as matching criteria. This means
that trying to import updates to these fields may cause matching to fail,
unless you successfully meet the first matching criteria or use the
--roundtrip option. For more information on matching, see:
With the “delete-and-replace” option, the matched archival description and any descendants (i.e. children) will be deleted prior to import. Note that related entities are not deleted - such as linked authority records, terms such as subject, place, or genre access points, accessions, etc. If you want these removed as well, you will need to manually delete them from the user interface following the delete-and-replace import. On import of the replacement record, AtoM will also not automatically link to the same entities. Instead, it will use the existing matching logic to determine if it should link to an existing linked record, or create a new one. For more information on how AtoM determines whether or not to link to an existing authority record, see: Attempting to match to existing authority records on import.
See also
The AtoM user manual further explains these options, as they are available on the Import page in the user interface. See:
The --limit option can be used with --update to increase the
likelihood of a successful match by limiting the match criteria to either
records belonging to a specific repository, or matching a specific existing
top-level description. It takes the slug of the related repository or
top-level archival description as its value. For example, to import a
CSV called “my-updates.csv” and update the descriptions of the John Smith
Fonds, your command might look like this:
php symfony csv:import --update="match-and-update" --limit="john-smith-fonds"
/path/to/my-updates.csv
Normally, when attempting to match records, if AtoM fails to find a match
candidate, it will proceed to import the row as a new record. However, you can
use the --skip-unmatched option with --update to change this default
behavior. When --skip-unmatched is used, then any records that do not
match will be ignored during the import, and reported in the console log shown
on the Job details page of the related import job (see:
Manage jobs for more information). This is recommended if you are
intending to only import updates to existing records. Note that
--skip-unmatched will not work if it is not used in conjunction with the
--update option.
Warning
It is very difficult to use the --skip-unmatched option with a
--update="delete-and-replace when working with hierarchical data. Once a
match is found for the top-level description (e.g. the root
parent record), AtoM will then proceed to delete the original
description and all of its children (e.g.
lower level records). This means that when AtoM gets to the next child row
in the CSV, it will find no match in the database - because it has already
deleted the children - and the records will therefore be skipped and not
imported.
Unless you are only updating standalone descriptions (e.g. descriptions
with no children), we do not recommend using the --skip-unmatched
with --update="delete-and-replace.
Similarly, with new imports, you can use the --skip-matched option to skip
any records that AtoM identifies as matching those you have already imported.
This can be useful if you are uncertain if some of the records in your CSV
have been previously imported - such as when passing records to a portal site
or union catalogue. Any records that appear to match existing archival
descriptions will be ignored during the import, and reported in the console
log shown on the Job details page of the related import
job. For more information on how AtoM attempts to match incoming imports to
existing descriptions, see: Matching criteria for archival descriptions.
Normally during an update import when using match-and-update, the digital
object will be deleted and re-imported as part of the update, even if the path
or URI provided is the same - this is in case the digital object itself has
changed at the source. However, there are 2 ways users can avoid this. The
first is to include a digitalObjectChecksum column in the import CSV, and
to populate the row with the exact same checksum used by AtoM when uploading
the digital object (this can be seen in the file path to the
master digital object). If you export a CSV with a digital object from
AtoM, the checksum column and value is included in the export (see:
CSV export). However, if you do not have the checksum value handy and
you don’t want or need the digital object to be deleted and re-imported,
then the other way to skip this process is to use the
--keep-digital-objects option. When this option is used with
--update="match-and-update", then the deletion of the existing digital
object and its derivatives will be skipped.
The --skip-derivatives option can be used if you are using the
Digital object-related import columns to import a digital object attached to
your description(s). For every digital object uploaded, AtoM creates two
derivative objects from the master digital object: a thumbnail
image (used in search and browse results) and a reference display copy
(used on the view page of the related archival description). The
master digital object is the unaltered version of a digital object
that has been uploaded to AtoM. When the --skip-derivatives option is
used, then the thumbnail and reference display copy of your linked digital
object will not be created during the import process. You can use the
digital object derivative regeneration task to create them later, if desired -
see: Regenerating derivatives.
Finally, the --roundtrip option is useful when attempting to update records
that have been exported from the same system which you are trying to update
via import (“roundtripping” implies exporting a CSV, making changes, and then
re-importing it as an update). On export, AtoM populates the legacyId
column with the unique database object ID value used in AtoM. When the
--roundtrip option is used, AtoM will only look for exact matches on the
legacyId in the CSV, comparing it against AtoM’s internal description
object ID values and bypassing all other matching criteria. This can be useful
when trying to update secondary matching criteria values such as the title,
identifier, and/or repository associated with a description.
Important
Note that if you originally created your descriptions via import, AtoM’s
object ID value (included in the legacyID column in exports) is not
the same value as you added in the legacyID column during the original
import. That value is stored in AtoM’s keymap database table, and is
used only for matching criteria for subsequent imports. The legacyID
column was originally added for supporting and troubleshooting migrations
from third-party systems (so that a unique ID from the source system would
remain associated with the incoming descriptions); without the
--roundtrip option AtoM continues to assume that the metadata
originates from outside of AtoM, and will use the sourcename and
legacyID values in the keymap table from the original import as the
first matching criteria. For more information, see:
Because AtoM object IDs are always unique throughout an installation, this
option provides a more reliable matching criteria when roundtripping
descriptions in the same system. The --roundtrip should be used in
conjunction with the --update option.
Example use:
php symfony csv:import --update="match-and-update" --roundtrip /path/to/rad_0000000001.csv
Normally, the --roundtrip option, when used, will first ask you if you have
a backup of your database before proceeding. However, you can skip this
confirmation requirement by adding the --no-confirmation option as well.
Importing events¶
Read more about importing events in the AtoM User manual documentation, here:
Example use - run from AtoM’s root directory:
php symfony csv:event-import lib/task/import/example/example_events.csv
There are also various command-line options that can be used, as illustrated in the options depicted in the image below:
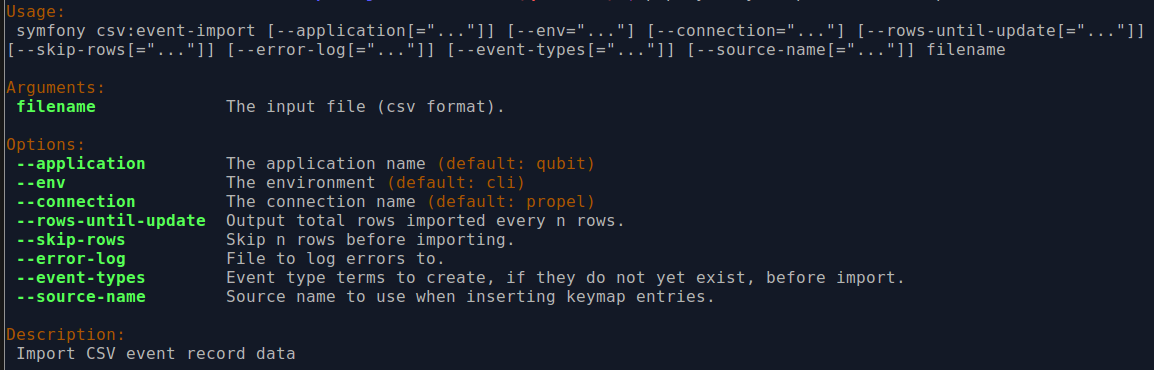
By typing php symfony help csv:event-import into the command-line from your
root directory, without specifying the location of a CSV, you will able able to
see the CSV import options available (pictured above). A brief explanation of
each is included below.
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update, --skip-rows, and --error-log options can
be used the same was as described in the section
above on importing descriptions. For more
information on the --rows-until-update option, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
Use the --source-name to specify a source importing to a AtoM installation
in which information objects from multiple sources have been imported, and/or
to associate it explicitly with a previously-imported CSV file that used the
same --source-name value. Further information is provided in the section on
legacy ID mapping in the User Manual - see: Legacy ID mapping: dealing with hierarchical data in a CSV.
The --event-types option is deprecated, and no longer supported in AtoM.
Importing repository records¶
Example use - run from AtoM’s root directory:
php symfony csv:repository-import
lib/task/import/example/example_repositories.csv
There are also various command-line options that can be used, as illustrated in the options depicted in the image below:
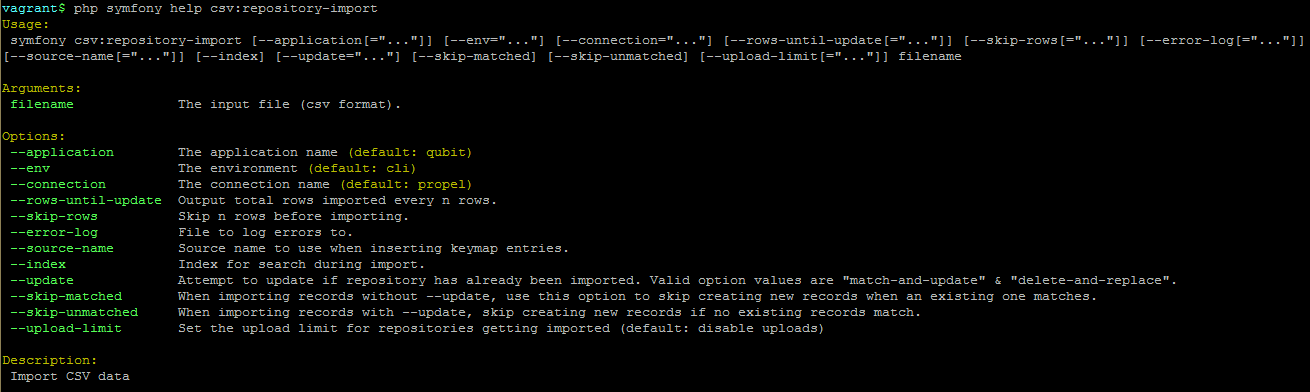
By typing php symfony help csv:repository-import into the command-line from
your root directory, without specifying the location of a CSV, you will able
able to see the CSV import options available (pictured above). A brief
explanation of each is included below. For full details on
archival institution CSV imports, please see:
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update, --skip-rows, and --error-log options can
be used the same was as described in the section
above on importing descriptions. For more
information on the --rows-until-update option, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
Use the --source-name option (described in the CSV import
documentation here) to specify the source name
that will be added to the keymap table. This can be useful for improving the
matching logic when importing updates - you can specify the same source name
used as the was used during the original import for greater matching. By
default in AtoM, when no source name is specified during import, the CSV
filename will be stored in the keymap table as the source name.
The --index option will progressively add your imported repository records
to AtoM’s search index as the import progresses. Normally when using the
user interface to perform an import, the import is
indexed automatically - but when running an import via the command-line
interface, indexing is disabled by default. This is because indexing during
import can sometimes be incredibly slow, and the command-line is generally used
for larger imports. Generally, we recommend a user simply clear the cache and
rebuild the search index following an import - from AtoM’s root directory, run:
php symfony cc && php symfony search:populate
However, if you would like to index the import as it progresses, the
--index option can be used to enable this. This is useful if you have a
large database, and don’t want to have to re-index everything. For more
information on indexing options, see: Populate search index.
The --update option can be used when you want to use a CSV import to
update existing archival institutions, instead of creating new records. There
are 2 modes: --update="match-and-update" and
--update="delete-and-replace. When used, AtoM will attempt to identify
matching archival institution records and, depending on which option is used,
either update them in place, or delete the match and replace it with the new
repository record in the CSV. The matching criteria for repository records is
based on an exact match on the authorized form of name of the existing
repository. This means that you cannot use the --update option to update
the name of your existing repositories, or AtoM will fail to find the correct
match on import.
Tip
You can read more about each update option in the User Manual:
For the “match-and-update” option, AtoM will update any repository record related columns that have new data. Columns in the related CSV row that are left blank will not delete existing data - instead, they will be ignored and any existing data in the related field will be preserved.
Important
At this time, not all fields in the archival institution record can be updated. Primarily, these are fields that are found in other tables in the AtoM database than the primary repository record table. For further details, see: Updating repository records in place via CSV import.
With the “delete-and-replace” update option, AtoM will delete the matches prior to importing the CSV data as a new record to replace it.
Note that only the matched repository record is deleted during this process. Any related/linked entities (such as an authority record linked as being maintained by the repository, Thematic area or other repository access points, and linked archival descriptions) are not automatically deleted. If you also want these fully removed, you will have to find them and manually delete them via the user interface after the import.
Once the original matched repository record has been deleted, the CSV import proceeds as if the record is new. That is to say, just as AtoM does not automatically delete entities related to the original archival institution, it also not automatically re-link previously related entities.
Warning
This means that if your archival institution record is linked to descriptions, using the “Delete and replace” method will unlink all descriptions - these will not be automatically re-linked with the new import!
We recommend you only use the “Delete and replace” method with repository records that are not currently linked to other entities.
Normally, when attempting to match records, if AtoM fails to find a match
candidate, it will proceed to import the row as a new record. However, you can
use the --skip-unmatched option with --update to change this default
behavior. When --skip-unmatched is used, then any records that do not
match will be ignored during the import, and reported in the console log shown
on the Job details page of the related import job (see:
Manage jobs for more information). This is recommended if you are
intending to only import updates to existing records. Note that
--skip-unmatched will not work if it is not used in conjunction with the
--update option.
Similarly, with new imports, you can use the --skip-matched option to skip
any records that AtoM identifies as matching those you have already imported.
This can be useful if you are uncertain if some of the records in your CSV
have been previously imported - such as when passing records to a portal site
or union catalogue. Any records that appear to match existing repository
records (based on the authorized form of name) will be ignored during the
import, and reported in the console log shown on the
Job details page of the related import job.
You can use the --upload-limit option to specify the default upload limit
for repositories which don’t specify their uploadLimit in the CSV file. That
is, if for example you performed a CSV import with the command-line option of
--upload-limit=5, then for every repository in the CSV that does NOT have a
value in the uploadLimit column, the default value of 5 GBs will be assigned.
For more information on this functionality in the
user interface, see: Set digital object upload limit for an archival institution.
Importing authority records¶
The authority record import tool allows you to import data about people, families, and organizations. Note that authority records and their relationship data can also be imported via the user interface - for more information, see: Import new authority records via CSV and Import new authority record relationships via CSV.
You can view the example CSV files for authority records in the AtoM code (at
lib/task/import/example/authority_records/) or they can be downloaded
directly here:
The primary documentation for preparing the authority record CSV template can be found in the User Manual, here:
See also
Run the CSV import task from AtoM’s root directory. To use the example authority record import file that is included with the AtoM installation:
php symfony csv:authority-import lib/task/import/example/authority_records/example_authority_records.csv --index
There are also various command-line options that can be used, as illustrated in the options depicted in the image below:
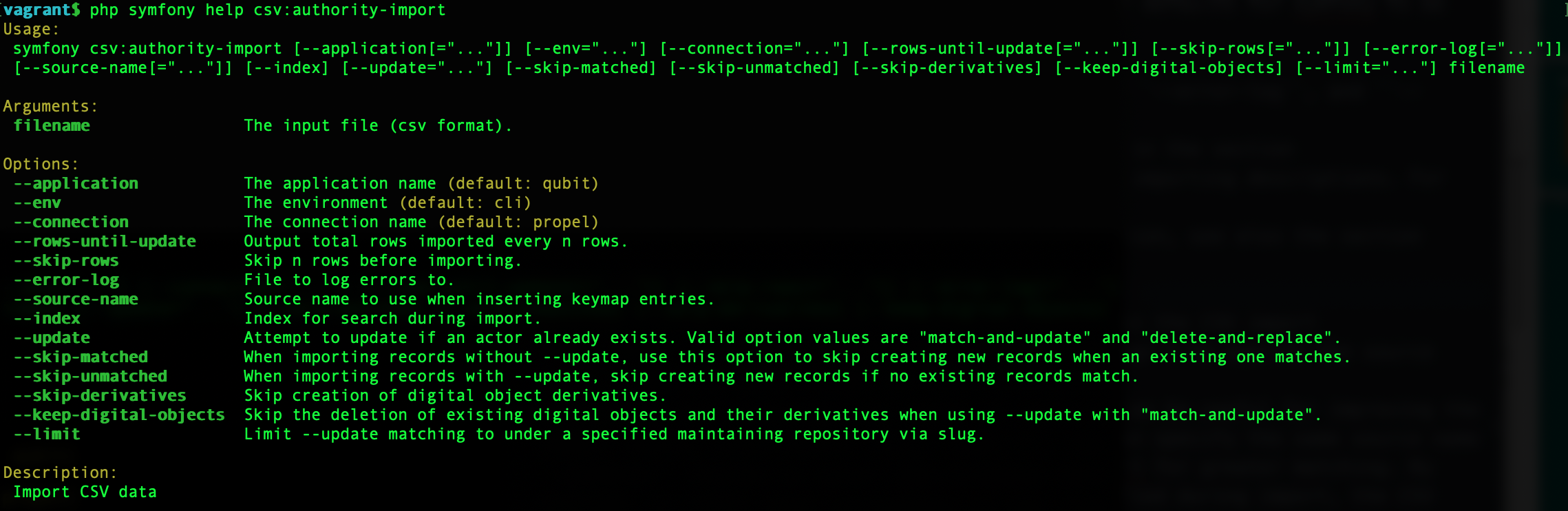
By typing php symfony help csv:authority-import into the command-line from
your root directory, without specifying the location of a CSV, you will
able able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update, --skip-rows, --error-log, and --index
options can be used the same was as described in the section
above on importing descriptions. For more
information on the --rows-until-update option, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
Use the --source-name option (described in the CSV import
documentation here) to specify the source name
that will be added to the keymap table. This can be useful for improving the
matching logic when importing updates - you can specify the same source name
used as the was used during the original import for greater matching. By
default in AtoM, when no source name is specified during import, the CSV
filename will be stored in the keymap table as the source name.
The --index option will progressively add your imported authority records
to AtoM’s search index as the import progresses. Normally when using the
user interface to perform an import,
the import is indexed automatically - but when running an import via the
command-line interface, indexing is disabled by default. This is because
indexing during import can sometimes be incredibly slow, and the command-line
is generally used for larger imports. Generally, we recommend a user simply
clear the cache and rebuild the search index following an import - from AtoM’s
root directory, run:
php symfony cc && php symfony search:populate
However, if you are running a small import or simply would like to index the
import as it progresses, the --index option can be used to enable this.
This is useful if you have a large database, and don’t want to have to re-index
everything. For more information on indexing options, see:
Populate search index.
The --update option can be used when you want to use a CSV import to
update existing authority records, instead of creating new records. There
are 2 modes: --update="match-and-update" and
--update="delete-and-replace. When used, AtoM will attempt to identify
matching authority records and, depending on which option is used,
either update them in place, or delete the match and replace it with the new
repository record in the CSV. The matching criteria for authority records is
based on an exact match on the authorized form of name of the existing
authority record. This means that you cannot use the --update option to
update the authorized form of name of your existing authority records, or AtoM
will fail to find the correct match on import.
Tip
You can read more about each update option in the User Manual:
For the “match-and-update” option, AtoM will update any authority record related columns that have new data. Columns in the related CSV row that are left blank will not delete existing data - instead, they will be ignored and any existing data in the related field will be preserved.
Important
At this time, not all fields in the authority record template can be updated. Primarily, these are fields that are found in other tables in the AtoM database than the primary authority record table. For further details, see:
With the “delete-and-replace” update option, AtoM will delete the matches prior to importing the CSV data as a new record to replace it.
Note that only the matched authority record is deleted during this process. Any related/linked entities (such as a repository linked as the authority record’s maintainer, other authority records linked via a relationship, Occupation access points, and linked archival descriptions) are not also automatically deleted. If you also want these fully removed, you will have to find them and manually delete them via the user interface after the import.
Once the original matched authority record has been deleted, the CSV import proceeds as if the record is new. That is to say, just as AtoM does not automatically delete entities related to the original archival institution, it also not automatically re-link previously related entities.
Warning
This means that if your authority record is linked to descriptions, a repository, or other authority records, using the “Delete and replace” method will unlink all descriptions, repositories, and authority records - these will not be automatically re-linked with the new import!
We recommend you only use the “Delete and replace” method with authority records that are not currently linked to other entities.
For more information on linking authority records, see:
The --limit option can be used with --update to increase the
likelihood of a successful match by limiting the match criteria to records
linked to a specific repository as its maintainer.
This option takes the slug of the related repository as its value. For
example, to import a CSV called “my-updates.csv” and update an authority
record for Jane Doe belonging to the Example Archives, your command might look
something like this example:
php symfony csv:authority-import --update="match-and-update"
--limit="example-archives" /path/to/my-updates.csv
Normally, when attempting to match records, if AtoM fails to find a match
candidate, it will proceed to import the row as a new record. However, you can
use the --skip-unmatched option with --update to change this default
behavior. When --skip-unmatched is used, then any records that do not
match will be ignored during the import, and reported in the console log shown
on the Job details page of the related import job (see:
Manage jobs for more information). This is recommended if you are
intending to only import updates to existing records. Note that
--skip-unmatched will not work if it is not used in conjunction with the
--update option.
Similarly, with new imports, you can use the --skip-matched option to skip
any records that AtoM identifies as matching those you have already imported.
This can be useful if you are uncertain if some of the records in your CSV
have been previously imported - such as when passing records to a portal site
or union catalogue. Any records that appear to match existing authority
records (based on the authorized form of name) will be ignored during the
import, and reported in the console log shown on the
Job details page of the related import job.
Import authority record relationships¶
Relationships between authority records can be imported in a CSV file. This import can be done via the user interface or from the command line, as explained below.
Another way to create relationships between two authority records is via the user interface. See: Create a relationship between two authority records.
The primary documentation for preparing the authority record relationships CSV template can be found in the User Manual, here:
An example CSV template containing relationship data is available in the AtoM
source code at lib/task/import/example/authority_records/
example_authority_record_relationships.csv or it can be downloaded here:
Note that the Relationships CSV file can only import relationships between two authority records that already exist in the AtoM database and using a relationship type term that has already been created in the Actor relation type taxonomy. For more information on managing and creating relation type terms, see: Terms; see specifically Add/edit a converse term.
Assuming you have already imported the authority records in the
lib/task/import/example/authority_records/example_authority_records.csv
file, here is an example import that establishes a relationship between
those authority records:
php symfony csv:authority-relation-import lib/task/import/example/authority_records/example_authority_record_relationships.csv --index
Include the --index parameter to update the search index for each
imported relationship. Otherwise run php symfony search:populate to
rebuild your entire application index in one batch after the import
completes.
When an authority record in the Relationship CSV file does not match an existing authority record, AtoM will ignore that row in the CSV file and provide a warning to indicate that a match was not found.
As with other import jobs, you can add an --update parameter to specify
more specific import behaviour. Specifically:
--update="match-and-update": AtoM will look for a match on thesubjectAuthorizedFormOfNameandobjectAuthorizedFormOfName. If therelationTypeis also the same, then AtoM will update any new values for the description, dates, and/or culture fields found in that row of the CSV file. If therelationTypeis different, then AtoM will create a new relationship between the two authority records using this new relationship type along with any values found in the description, dates, and/or culture fields. If a newly imported relationship matches an existing relationship but thematch-and-updateparameter is not being used, then AtoM will ignore that row in the CSV file and provide a warning to indicate that an update was not made.--update="delete-and-replace": AtoM will look for a match on thesubjectAuthorizedFormOfNameandobjectAuthorizedFormOfNamefields. When it finds these matches, AtoM will delete all existing relationships records between these two authority records and replace them with the one or more new relationships found in the CSV file.
Import accession records¶
The accession record import tool allows you to import data about your
accessions. Additionally, when importing descriptions as well, you can use the
subsequent archival description CSV import to create a link between
your accession records and your descriptions, by adding an accessionNumber
column in the archival description CSV and populating it with the exact
accession number(s) used during your accessions data import.
Alternatively, you can use the qubitParentSlug column to link existing
descriptions in AtoM to new or updated accessions records via your import -
for more details see the User Manual: Prepare accession records for CSV import.
An example CSV template file is available in the
lib/task/import/example/example_accessions.csv directory of AtoM, or it
can be downloaded here:
The primary documentation for preparing your accession record data in a CSV file for import can be found in the User Manual:
Please review the guidance provided there carefully prior to running a command line import. The use of the command-line task and its options are outlined below.
Example use - run from AtoM’s root directory:
php symfony csv:accession-import /path/to/my/example_accessions.csv
There are also a number of options available with this command-line task.
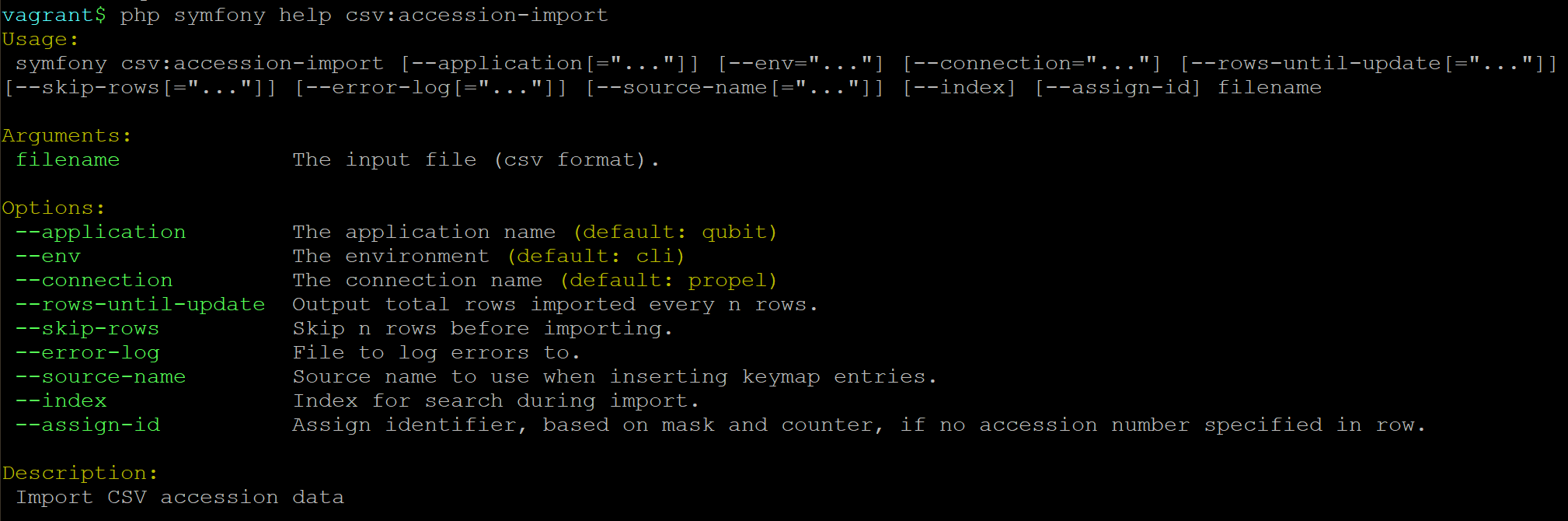
By typing php symfony help csv:accession-import into the command-line from
your root directory, without specifying the location of a CSV, you will
able able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
Use the --source-name to specify a source importing to a AtoM installation
in which accessions and information objects from multiple sources have been
imported, and/or to associate it explicitly with a previously-imported CSV
file that used the same --source-name value. An example is provided in the
section on legacy ID mapping in the User Manual - see:
Legacy ID Mapping.
The --rows-until-update, --skip-rows, --error-log, and --index
options can be used the same was as described in the section
above on importing descriptions. For more
information on the --rows-until-update option, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
The --index option will progressively add your imported accession records
to AtoM’s search index as the import progresses. Normally when using the
user interface to perform an import,
the import is indexed automatically - but when running an import via the
command-line interface, indexing is disabled by default. This is because
indexing during import can sometimes be incredibly slow, and the command-line
is generally used for larger imports. Generally for very large imports we
recommend a user simply clear the cache and rebuild the search index following
an import - from AtoM’s root directory, run:
php symfony cc && php symfony search:populate
However, if you would like to index the import as it progresses, the
--index option can be used to enable this. This is useful if you have a
large database, and don’t want to have to re-index everything. For more
information on indexing options, see: Populate search index.
The --assign-id option can be used to automatically assign the next unique
accession number value to each incoming record, based on the accession mask and
counter settings available in Admin > Settings > Identifiers. For more
information on these settings, see:
Typically, populating the accessionNumber column in an
accession record CSV import is required for the row not to be skipped.
However, when the --assign-id option is used, you can leave this column
blank in the CSV file. On import, AtoM will add the next available unique
accession number value, based on the mask and counter settings.
Important
The accession counter may not auto-increment in the user interface after the import completes. To ensure that the next time you generate an accession number in the user interface you don’t get an error, make sure you check the incremental number of the last accession in your import against the counter value, and manually increment the counter to this number post-import if it has not updated automatically.
See: Accession counter
Import deaccession records¶
The deaccession import tool allows you to import data about deaccession activities, which can be appended to accession records in AtoM. For more general information on working with deaccession records in AtoM, consult the User manual: Deaccession records. For the task to succeed, an accession number for an existing accession must be provided for each row - it is not possible to create new accession records while importing deaccession CSV data.
An example CSV template file is available in the
lib/task/import/example/example_deaccessions.csv directory of AtoM,
or it can be downloaded here:
The expected CSV will have 7 columns, corresponding to various fields available in the Deaccession record template. These include:
- accessionNumber: expects the accession number of an existing accession record in AtoM as input. If no match is found for an existing accession, the console will provide a warning, the row will be skipped, and the task will continue.
- deaccessionNumber: an identifier for the deaccession. Free text, will support symbols and typographical marks such as dashes and slashes.
- date: expects a date value in ISO-8601 format (YYYY-MM-DD).
- scope: expects one of the controlled terms from the “Scope” field in the AtoM deaccession record template. English options include “Whole” and “Part”.
- description: Free-text. Identify what materials are being deaccessioned.
- extent: Free-text. Identify the number of units and the unit of measurement for the amount of records being deaccessioned.
- reason: Free-text. Provide a reason why the records are being deaccessioned.
- culture: Expects a 2-letter ISO 639-1 language code as input (e.g.: en, fr, es, pt, etc).
Example use - run from AtoM’s root directory:
php symfony csv:deaccession-import /path/to/my/example_accessions.csv
There are also a number of options available with this command-line task.
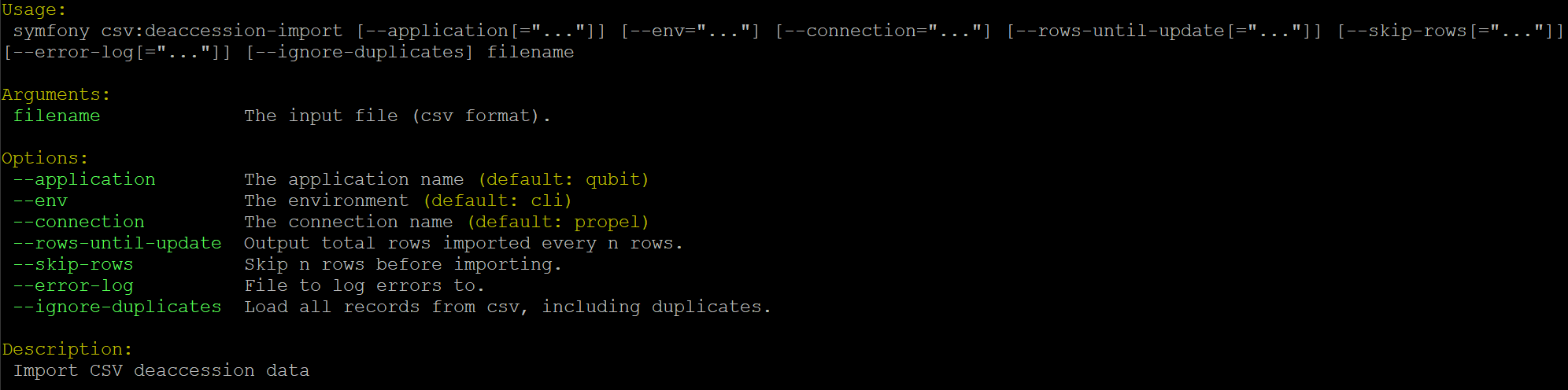
By typing php symfony help csv:deaccession-import into the command-line from
your root directory, without specifying the location of a CSV, you will
be able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update, --skip-rows, and --error-log options can
be used the same was as described in the section
above on importing descriptions. If you
wish a summary of warnings reported in the console log, you can use the
--error-log option - it takes a path to a new text file as input, and
will copy all console warnings to this log file. Acceptable file extensions for
the log file are .txt or .log. For more information on the
--rows-until-update option, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
More than 1 row of data (i.e more than 1 deaccession record) can be associated
with the same accession record. To prevent accidental exact duplicates, by
default AtoM will skip any rows where all data is identical to a row
preceding it, and will report the skipped record in the console log. If you
are intentionally importing duplicate deaccession records, you can use the
--ignore-duplicates option.
Import physical storage containers and locations¶
This task will allow for the import of physical storage data, as well as updates to existing physical storage containers, via a CSV file. Read more about managing physical storage data in AtoM in the User manual:
The basic syntax for this task is:
php symfony csv:physicalobject-import /path/to/storage.csv
The CSV filename and path (shown as the example /path/to/storage.csv
above) must be a valid path to a CSV file that is readable by the current
user. The CSV file must use UTF-8 character encoding if it includes characters
outside of the basic ASCII character set. The CSV file formatting must use a
comma for the column delimiter. Literal values that include a comma character
must be enclosed in double-quotes (e.g. “Shelf 10, Box 12345”). Line endings
can be Windows (\r\n) or Linux (\n) formatted. For more general
suggestions on properly preparing your CSV for import, see:
Verify character encoding and line endings.
You can find a copy of the example physical object CSV import template on the
AtoM wiki, or
stored locally in AtoM’s code at
lib/task/import/example/example_physicalobject.csv
The CSV template contains 6 columns, summarized below:
- legacyID: A unique value, used to capture database identifiers from legacy systems during data migrations for easier troubleshooting. Not required for new import data, but recommended. Can be any alphanumeric characters. Does not display in AtoM’s user interface.
- name: Free-text. The container name to be used in AtoM
- type: Type of container. Links to AtoM’s Physical Object Type taxonomy. See Manage physical storage types in the User manual for more information and default terms. A new term in the CSV data will create a new corresponding term in the Physical Object Type taxonomy in AtoM on import.
- location: Free text. Used to add information about a container’s location.
- culture: Language of the import data. Expects ISO 639-1 two-letter
language codes. If left unpopulated, it will default to
enduring import. - descriptionSlugs: multi-value input for the slugs of
related archival descriptions. When linking a
container row to multiple archival descriptions, separate each slug value
with a
|pipe separator.
Tip
A slug is a word or sequence of words which make up a part of a URL that
identifies a page in AtoM. It is the part of the URL located at the end of
the URL path and often is indicative of the name or title of the page
(e.g.: in www.youratom.com/this-description, the slug is
this-description). For more information on slugs in AtoM, see:
By typing php symfony help csv:physicalobject-import into the command-line
without specifying the path to a CSV file, you can see the options available
on the csv:physicalobject-import command:
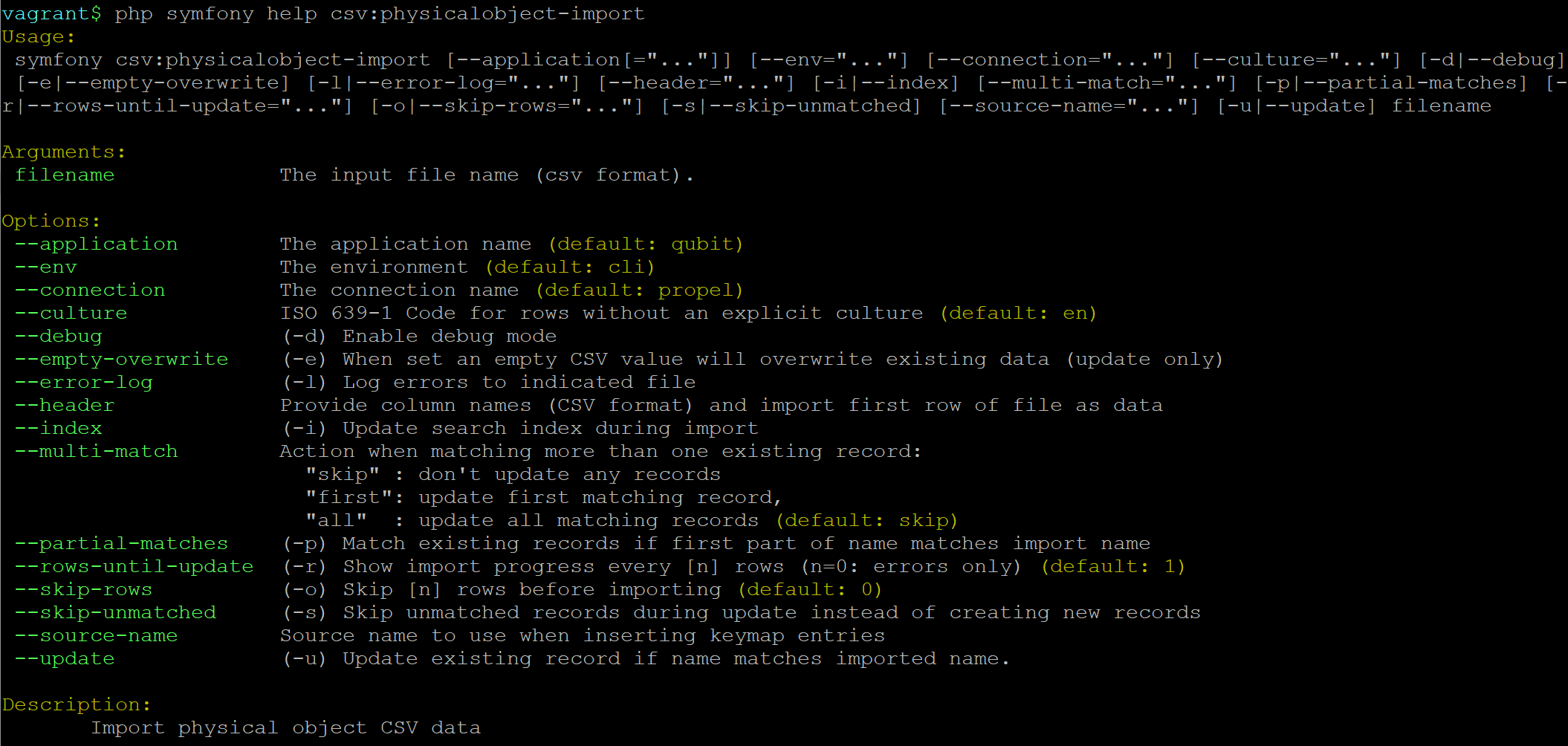
The --application, --env, and --connection options should not be
used - AtoM requires the use of the pre-set defaults for symfony to be able to
execute the import.
The --culture option can be used to specify a default culture code for the
CSV import using a two letter ISO 639-1 code (e.g. en for English, fr
for French). The culture column in the CSV import file can be used to
specify a culture for that row, and will override the default culture value set
with this option. The default value if this option is not specified is en
for English.
The --debug or -d option outputs timing data for various import
subprocesses to help identify and diagnose bottlenecks.
The --empty-overwrite or -e option will cause empty columns to overwrite
existing data in AtoM when updating existing physical storage data via the
--update option. This option must be used with the --update option.
The --error-log or -l option can be used to specify a file to log errors
encountered during import. Note that it is possible for critical errors in the
import to halt the import completely, in which case the critical error will not
be written to the log file, but will be output to the console (STDERR) instead.
Other error messages and warnings will be logged to the file. Output that is
not a warning or error (e.g. progress indicators) will not be logged to the
error log, but will be output to console (STDOUT) and can be saved to file if
desired by redirecting STDOUT to a file. This option expects a path to where the
log should be output. Example:
php symfony physicalobject:import --error-log="/usr/share/nginx/atom/import-log.txt" lib/task/import/example/example_physicalobject.csv
You can leave the file extension off the error log path, but the path must end
in the file name you want used for the log file. Acceptable file extensions
include .log or .txt.
The --header option can be used to specify a comma delimited list of strings
(e.g. --header="name,type,location,culture") that will be used as column
names for the import. This option should not be used for CSV import files
that already include column headers (such as the example_physicalobject.csv
template), as the first row will be imported as physical object data. If the
--header option is not used, the first row of the CSV file will be used as
column header names. The number of column names passed to --header must
match the number of columns in the import file.
The --index or -i option adds imported data to the AtoM search index
incrementally during execution of the import script. For large imports it may
be desirable to omit the index option as the import will run more quickly, and
then run php symfony search:populate to update the search index after the
import is complete. For more information on populating the search index, see:
Populate search index.
The --multi-match option determines how the import script will handle an
import name that matches more than one physical object name in AtoM when the
--update option is used. It expects one of 3 values as input: “skip”,
“first”, or “all.” The default value of “skip” will not update any
existing records if the import name matches multiple existing records, and
will report the matched and skipped rows in the error log or STDERR. The
“first” option will update only the first matching record in the database, and
skip subsequent matches - skipped matches will be reported in the error log or
STDERR. Please be aware that the sort order of the matched records may not
match your expectations for ordering based on the database primary key or
default ordering. The “all” option will update all records in the database
that match the import name.
The --partial-matches or -p option will match any records in the AtoM
database where record name starts with the import name value. For instance, an
import name of “box” will match existing records “boxes”, “box1”, and
“box-hollinger”, but will not match “hollinger-box” or “bo”. Note that matches
are not case sensitive, and the --multi-match option will determine
which matched records are updated in the case of multiple matching records.
The --rows-until-update or -r option controls how often the import task
will output information about the progress of the import process. For more on
this general import option, see below: Display the progress of an upload via the command-line interface (CLI).
The --skip-unmatched or -s option must be used with the --update
option, and prevents the unwanted creation of new records in the database.
CSV rows that match an existing record in the database (by name) will update
the matched record or records (see the --multi-match option for information
on multiple matches). Normally, when a match is not found during an update import,
AtoM will treat an unmatched row as new data, and will create a new container -
however, with the skip-unmatched option used as well, CSV records that do
not match an existing database record will be ignored. A warning message will
be output to the error log or STDERR for each CSV record that is skipped because
it does not match an existing container record.
The --skip-rows or -o option will skip the specified number of rows in the
CSV, and then start importing data after that point. For instance, specifying
--skip-rows=100 would start the import at row 101 of the CSV import file.
The --skip-rows option is normally used to resume an import that failed or
was aborted to prevent duplicating already imported data. Please note that
unless the --header option is used, the first row of the CSV file is assumed
to contain field names rather than data, and this row is not counted when
determining the number of skipped rows. For example, if the --header option
is not specified and --skip-rows=10, the first eleven rows of the CSV file
(i.e. the header plus 10 data rows) will be skipped, and the 12th CSV row will
be the first record imported.
The --source-name option is used to logically group multiple imports
together if a single data set has been split into multiple CSV files to prevent
running out memory during an import, or to limit the time each import takes to
complete. For example, --source-name="January 2020 import" could be used for
multiple CSV files that comprise a January 2020 data update.
Finally, the --update or -u option will attempt to match each import
record with one or more (see --multi-match) existing physical storage
records in the database, and will use the matching CSV row data to update the
matched record(s).
A match is determined solely on physical object name by default (though
see the --partial-match option, which modifies the matching criteria), and
matching is not case sensitive (i.e. “box-1234” will match “BOX-1234”).
For example, if the --update option is used, and the CSV import file
includes a container named “box-1234”, and there is an existing physical
object in AtoM named “Box-1234,” then the existing physical object will be
updated with the CSV data instead of creating a new physical object in AtoM.
Please note that the --empty-overwrite, --skip-unmatched,
--multi-match, and --partial-match options all affect the match and
update criteria when using the --update option.
An example
The following example import command will:
- Import a CSV of physical storage data as an update to existing data
- Skip any unmatched rows
- Update all matching records where multiple matches on container name are found
- Allow for partial name matches to be considered acceptable matching criteria
- Skip the first 10 data rows of the CSV
- Report any non-fatal errors to a file called “errors.log”
- Update the search index as the import progresses
php symfony csv:physicalobject-import --update --skip-unmatched --multi-match="all" --partial-match --skip-rows=10 --error-log="/usr/share/nginx/atom/errors.log" --index /path/to/my/storage.csv
This example could also be written as follows, use the short names for the options:
php symfony csv:physicalobject-import -u -s --multi-match="all" -p -o=10 -l="/usr/share/nginx/atom/errors.log" -i /path/to/my/storage.csv
See also
Display the progress of an upload via the command-line interface (CLI)¶
The various CSV import tools allow the use of the --rows-until-update
command-line option to display the current row of CSV data being imported.
This is an extremely simplified way to indicate progress graphically via the
command-line - the user sets a numerical value for the number of rows the task
will progress before an update, and then the task will output a dot (or period
) in the command-line every time the indicated number of rows has been
processed in the current CSV.
Example use reporting progress every 5 rows:
php symfony csv:import
lib/task/import/example/rad/example_information_objects_rad.csv
--rows-until-update=5
This can be useful for large imports, to ensure the import is still progressing, and to try to roughly determine how far the task has progressed and how long it will take to complete.
Audit a CSV import¶
With large CSV files, it can sometimes be difficult to determine if all rows imported as expected. This simple command-line task can be used following a CSV import to determine if a match can be found in AtoM’s database for each row in the import CSV.
How it works: using the keymap table and the import source name¶
When a CSV import is performed in AtoM, two values are added to a database table called the keymap table for every row in the CSV:
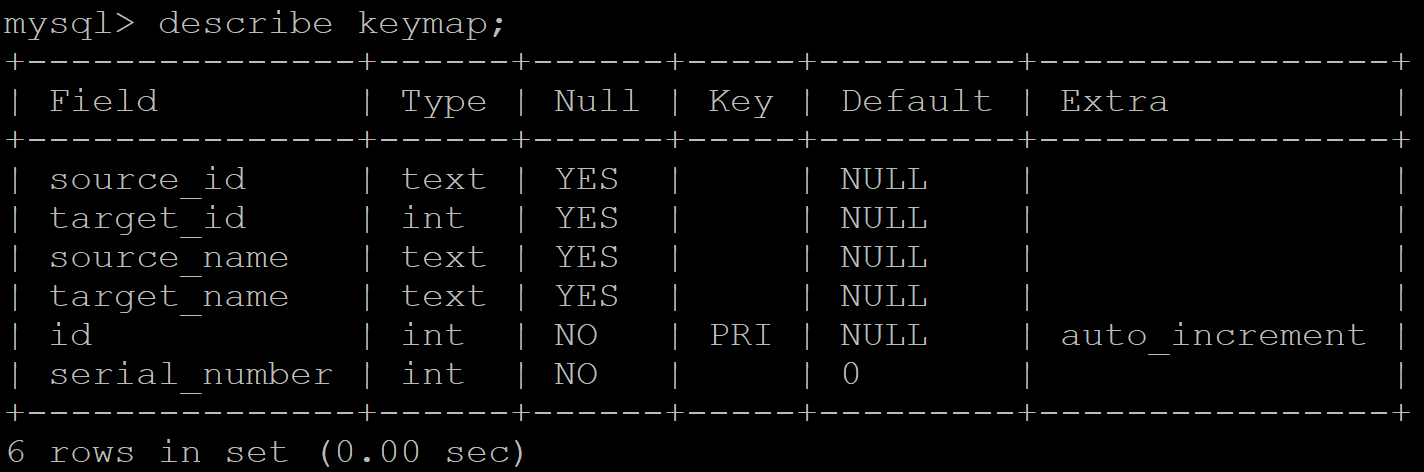
- legacyId: The
legacyIdvalue used in the CSV for that row will be stored in the keymap table’ssource_idfield - source name: A source name for the CSV will be stored in the
source_namefield of the keymap table. The command-line CSV import tasks (such as the archival description import task) include a--source-nameoption that allows a user to manually define the source name used; if this is not specified (such as during imports via the user interface, where no option for manually entering a source name is provided), then the filename of the CSV (including the.csvextension) is used by default.
These values are also used in the matching logic used for update imports. For more general information on the use of the keymap table values, see:
- Importing archival descriptions
- Matching criteria for archival descriptions (importing archival description CSV updates)
This audit task will use the sourcename of the import to find related values
in the keymap table, and then will compare every CSV row’s legacyId values
with those found in the source_id column of the keymap database table.
If a row is found in the CSV without a corresponding match in the keymap table, then this will be reported in the console. You can then address the issue however you’d prefer, such as:
- Creating a new CSV with the missing rows as a follow-up import
- Loading a database backup and then re-performing the original import
- Using the Delete descriptions created by a CSV import task described below to delete the results of the first import, before re-performing the import
- Manually creating the missing records
- Etc.
Task usage¶
The basic syntax for the CSV audit import task is:
php symfony csv:audit-import sourcename filename
Where sourcename represents the source name used during the original CSV
import (which will default to the CSV filename, including the extension, if
none is defined during import), and where filename represents the current
path and filename where the original import CSV is located, so it can be used
for comparison against AtoM’s keymap table.
Tip
See below for tips on how to find the source name of a previously imported record in AtoM:
Sample task execution and output on a 3-row description CSV:

By running php symfony help csv:audit-import we can also see the console’s
help output for the task:
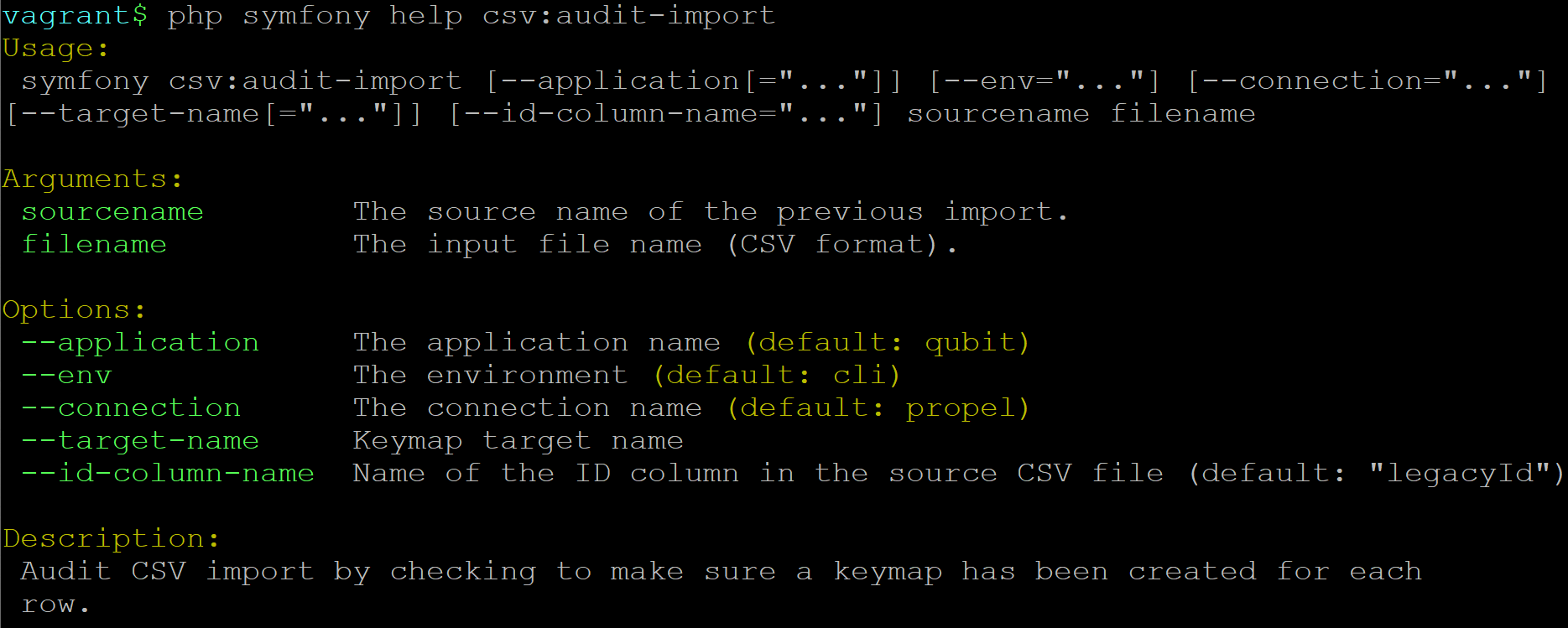
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for Symfony to be
able to execute the task.
The --target-name option is used to specify the entity type of the
records in the accompanying CSV. The default when this option is not specified
is information_object (i.e. archival description). Supported options
include:
- information_object (i.e. archival description)
- actor (i.e. authority record)
- repository (i.e. archival institution)
- event
- accession
- physical_object (i.e. physical storage)
Below is an example command to audit an authority record CSV import, where the
original import source name was set to myauthoritiesimport:
php symfony csv:audit-import --target-name='actor' 'myauthoritiesimport' lib/task/import/example/authority_records/example_authority_records.csv
Finally, the --id-column-name option is useful if you are using a
transformation script as part of an automated process, such as a migration
from a different legacy system. This option can be used to tell AtoM to use a
different CSV column name instead of the default legacyId column when
comparing values in the CSV against the source_id column in the keymap
table of AtoM’s database.
Delete descriptions created by a CSV import¶
Even with CSV Validation available, occasionally a CSV import will have unexpected results, and it can be time consuming to manually delete archival description records created by a bad import.
Fortunately, AtoM has a command-line task that can delete descriptions created by a CSV import. The task will not delete other entity types created by the import (such as linked access point terms, authority records, archival institutions, etc) since these may be related to other records in AtoM - you would need to find and delete these manually if desired. However, this CLI task can still make undoing a bad archival description CSV import much easier, provided the task is used carefully with a proper understanding of its methods and limitations.
How it works: using the source name as the task parameter¶
When a CSV import is performed in AtoM, two values are added to a database table called the keymap table for every row in the CSV:
- legacyId: The
legacyIdvalue used in the CSV for that row will be stored in the keymap table’ssource_idfield - source name: A source name for the CSV will be stored in the
source_namefield of the keymap table. The command-line CSV archival description import task includes a--source-nameoption that allows a user to manually define the source name used; if this is not specified (such as during imports via the user interface, where no option for manually entering a source name is provided), then the filename of the CSV (including the.csvextension) is used by default.
These values are used in the matching logic used for update imports. For more general information on the use of the keymap table values, see:
- Importing archival descriptions
- Matching criteria for archival descriptions (importing CSV updates)
This command-line task to delete records from an import will also use the source name value of the original import, stored in the keymap table, to identify records for deletion.
Finding the source name of a record¶
You can always check in the user interface what source name was used for records created via an import by entering into edit mode and navigating to the Administration area of the edit page - the source name used will be displayed there:
Alternatively, you can use SQL to find the source name and ID values associated with a description. See:
Important
If you have not used unique filenames (or manually specified source names) during your imports, you may end up deleting more records than intended! We strongly recommend making a backup of your data before proceeding.
See:
Task usage¶
The basic syntax for the command-line task to delete archival description records from a previous CSV import is:
php symfony import:delete sourcename
Where sourcename represents the source_name value associated with the
import, stored in AtoM’s keymap database table.
By running php symfony help import:delete we can also see the console’s help
output for the task:
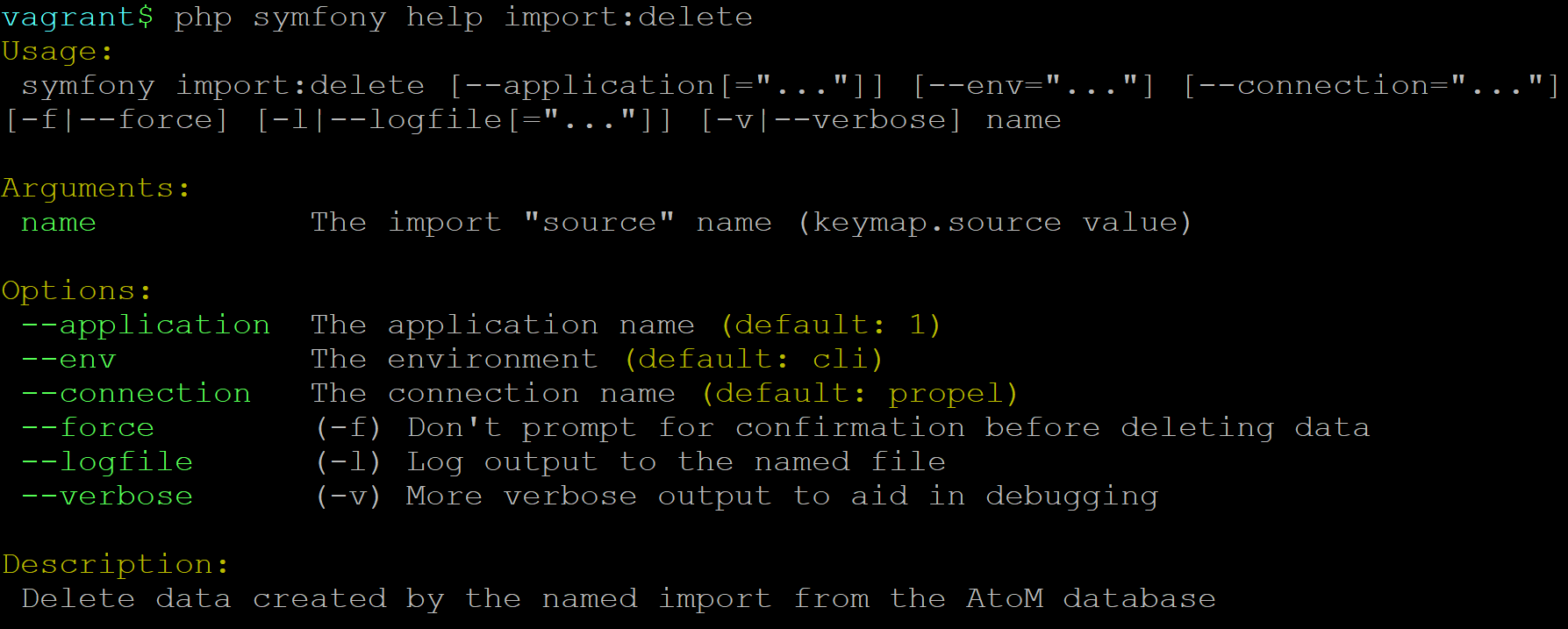
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for Symfony to be
able to execute the task.
Normally when run, the task will first remind you to create a database backup before proceeding, and will ask for confirmation before executing the task:
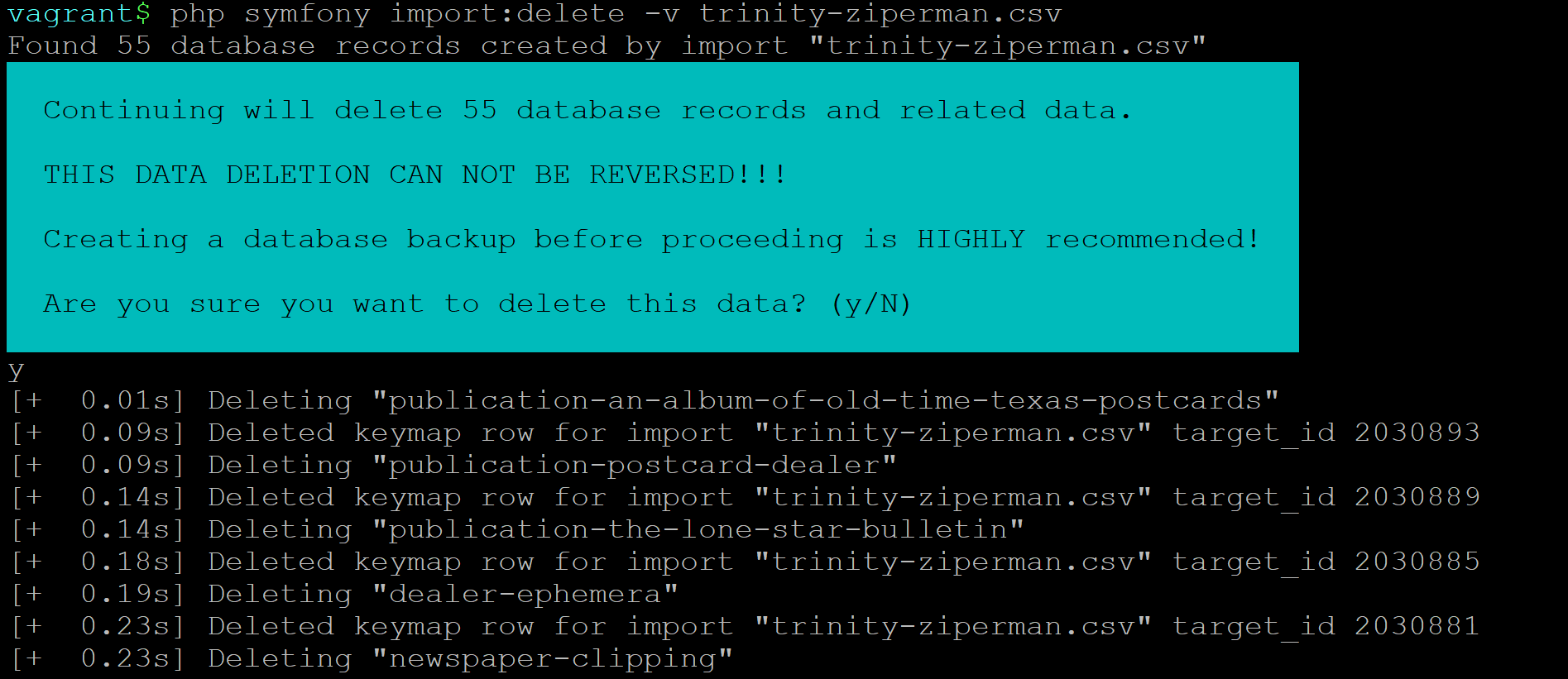
However to support scripted automation, or for a system administrator to simply
skip this confirmation step, you can use the --force (or -f) option
to bypass confirmation.
The --verbose (or -v) option can be used to provide a more detailed
output in the console as the task progresses, which can aid in debugging.
Additionally, if you would like to save the console output for review and
debugging, you can write the console log output to a file, by using the
--logfile (or -l) option and providing a file path and filename for
the target logfile, as in the example below:
php symfony import:delete --verbose --logfile="path/to/my/logfile.txt" my-bad-import.csv
Important
If you use this task, remember:
- You should make a backup of your database first, so if the results are unexpected, you can load your backup. See: Backing up the database
- Your source name should be unique for the target records. If you’ve imported multiple records with generic file names (or manually added source names) such as “isad-000001.csv”, then the task may delete more records than you expect!
- The task will not delete related entity types created by the import, such as linked access point terms, authority records, archival institutions, etc. since these may be related to other records in AtoM. You will need to find and delete these manually if desired
Load digital objects via the command line¶
Known as the Digital object load task, this command-line tool will allow a user to bulk attach digital objects to existing information objects (e.g. archival descriptions) through the use of a simple CSV file.
This task will take a CSV file as input, which contains two columns:
filename is a required column, that should contain the path to the digital
asset (file), ending in the filename and extension of the object to be
attached. AtoM does not allow more than one digital object per information
object (with the exception of derivatives), and each digital object must have
a corresponding information object to describe it, so this one-to-one
relationship must be respected in the CSV import file. See the “NOTES ON USE” at
the bottom of this task’s documentation for more information on how the task
will behave if more than one CSV row points at a single archival description.
The second CSV column column identifies the related information object (AKA archival description), to which you wish to attach your digital object. There are 3 different ways of providing this information - and therefore 3 different possible column header names, depending on the method you use:
- The first option is
information_object_id. This is a unique internal value assigned to each information object in AtoM’s database - it is not visible via the user interface and you may have to perform a SQL query to find it out. For instructions on how to do so, see Accessing the MySQL command prompt and Finding the Object ID of a record. - The second option is
slug. A slug is a word or sequence of words that make up the last part of a URL in AtoM. It is the part of the URL that uniquely identifies the resource and often is indicative of the name or title of the page (e.g.: in www.yourwebpage.com/about, the slug is about). The slug is meant to provide a unique, human-readable, permanent link to a resource. For more information on slugs in AtoM, see: Notes on slugs in AtoM. The values entered into this column are case sensitive, meaning that capitalization matters - AtoM will not matchMy-Slugtomy-slug, for example. - Finally, the description
identifiercan be used instead if preferred. A description’s identifier is visible in the user interface, which can make it less difficult to discover. However, if the target description’s identifier is not unique throughout your AtoM instance, the digital object may not be attached to the correct description - AtoM will attach it to the first matching identifier it finds.
The final CSV, once prepared, should have only 2 columns - one for the
filename, and a second column with information on the related description
(i.e. either information_object_id, slug, or identifier). The task
will take a path to this CSV as input - and it includes a number of additional
options, described in more detail below.
Using the digital object load task¶
Before using this task, you will need to prepare:
- A CSV file with 2 columns - EITHER
information_object_idandfilename, ORidentifierandfilename, ORslugandfilename. See above for further details on each option. - A directory with your digital objects inside of it
Important
You cannot use information_object_id, slug, and identifier in
the same CSV - only one of these columns must be present.
If you use the identifier column, make sure your target description
identifiers are unique in AtoM - otherwise your digital objects may not
upload to the right description!
Here is a sample image of what the CSV looks like when the identifier is used, and the CSV is prepared in a spreadsheet application:
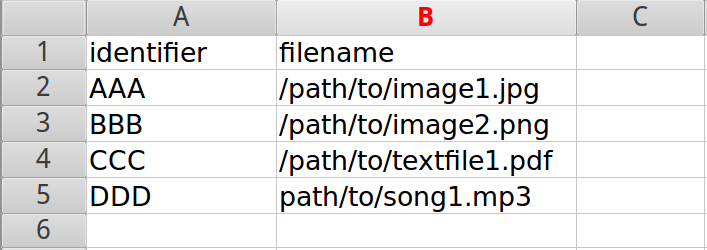
The task also includes an option to provide a default file path prefix to your
digital object directory (explained further below). Here is an example of a
CSV prepared using the slug column, with the full path to each object
omitted:

Tip
Before proceeding, make sure that you have reviewed the general CSV
preparation instructions included in the User Manual
here, to ensure that your CSV will work when
used with the digitalobject:load task. The key point when creating a
CSV is to ensure the following:
- The CSV file is saved with UTF-8 encodings
- The CSV file uses Linux/Unix style end-of-line characters (
/n)
Additionally, AtoM also has a task that can be used to double-check your load CSV against the digital object directory, looking for any discrepancies such as unused files, incorrect or duplicate file paths in the CSV, etc. For more information, see:
You can see the options available on the CLI task by typing in the following command:
php symfony help digitalobject:load
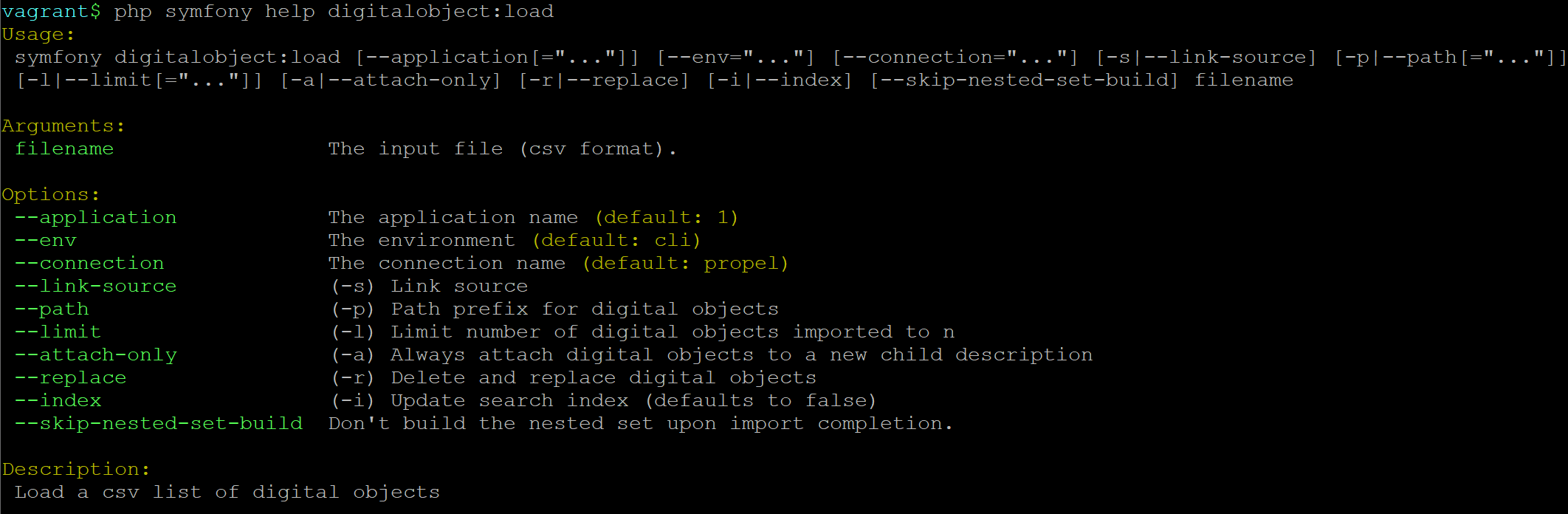
The --application, --env, and --connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
By default, the digital object load task will not index the collection as
it runs. This means that normally, you will need to manually repopulate the
search index after running the task. Running without indexing allows the task
to complete much more quickly - however, if you’re only uploading a small set
of digital objects, you can choose to have the task index the collection as it
progresses, using the --index (or -i) option.
Similarly, the task will typically update AtoM’s nested set (used to manage
hierarchical relationships) as it progresses, but this can slow import time.
If desired, you can use the --skip-nested-set-build option to omit nested
set updates, and then manually run the nested set build task after the digital
object load task completes.
The --limit option enables you to set the number of digital objects imported
via CSV using the digital object load task.
The --link-source option could apply in a use case where an institution
might typically store master digital objects in a separate local repository.
Rather than maintain multiple copies of every digital object, you could use the
--link-source option to load objects via local filepath stored to a source
file in the database. Essentially, when you use the --link-source option,
the digital object load task will behave like an external digital object being
uploaded via URI, and ultimately, the source “master” file(s) are not copied to
the uploads directory.
Note
When using the --link-source option, local derivatives are still
generated and stored in the uploads directory per usual.
The --path option will allow you to simplify the filename column in your
CSV, to avoid repetition. If all the digital objects you intend to upload are
stored in the same folder, then adding /path/to/my/folder/ to each object
filename seems tedious - your filename column will need to look something
like this:
filename
/path/to/my/folder/image1.png
/path/to/my/folder/image2.jpg
/path/to/my/folder/text1.pdf
etc...
To avoid this when all digital objects are in the same directory, you can use
the --path option to pre-supply the path to the digital objects - for each
filename, the path supplied will be appended. Note that you will need to
use a trailing slash to finish your path prefix - e.g.:
php symfony digitalobject:load --path="/path/to/my/folder/"
/path/to/my/spreadsheet.csv
The --attach-only option changes the behavior of where the task will attach
the associated digital object. When used, rather than attaching the digital
object to the target description, AtoM will instead always create a new stub
child description, and attach the digital object there.
This can be useful if you want to pass multiple digital objects to the same
parent description - for example, attaching individual TIFF files of book
pages as children to an item-level record describing the book.
Tip
See the “NOTES ON USE” section below to learn more about the load task’s default behaviors when multiple CSV rows point to the same archival description and no other task options are used.
The --replace option can be used if you want to overwrite existing digital
objects with those indicated in the CSV. When used, AtoM will delete any existing
attached digital object it finds and then attach the new object.
Important
You cannot use the --replace and --attach-only options at the same
time. This will generate the error:
Cannot use option "--attach-only" with "--replace".
Additionally, this option overrides the default multi-row behavior described
below (in the “notes on use”), and those of the --attach-only option.
When the --replace option is used:
- If the import CSV contains one image for a specific description and the description specified in the CSV does not have a digital object attached to it, this digital object will be imported and linked.
- If the import CSV contains one image for a specific description and the description specified in the CSV already has one attached, the attached digital object will be deleted and the one specified in the CSV will be imported and linked.
- If the import CSV contains more than one image for a specific description, and the description does not yet have a digital object directly linked to it, the last image specified in the CSV for this target description will be linked.
- If the import CSV contains more than one image for a specific description, and the description does already has a digital object directly linked to it, the existing image will be deleted and the last image specified in the CSV for this target description will be linked.
TO RUN THE DIGITAL OBJECT LOAD TASK
php symfony digitalobject:load /path/to/your/loadfile.csv
NOTES ON USE
- If a single CSV row points to a description that already has a digital object, then the row will be skipped and reported in the console
- If the CSV contains multiple rows pointing at a description that already has a digital object, then new stub child descriptions will be created below the target, and digital objects will be attached there. If child descriptions already exist, they will be ignored (meaning, running the task more than once will result in duplicate child descriptions).
- Note that the
--attach-onlyand--replaceoptions change the above default behaviors when multiple rows point to one description. Read the option descriptions above for more information. - Remember to repopulate the search index afterwards if you haven’t used the
--indexoption! For more information, see: Populate search index. - Additionally, if you use the
--skip-nested-set-buildoption, you will need to manually rebuild the nested set after the task has completed. See: Rebuild the nested set.
Regenerating derivatives¶
Sometimes the digitalobject:load task won’t generate the thumbnail
and reference images properly for digital
objects that were loaded (e.g. due to a crash or absence of convert installed,
etc.). In this case, you can regenerate these thumbnail/reference images using
the following command:
php symfony digitalobject:regen-derivatives
Warning
All of your current derivatives will be deleted! They will be replaced with new derivatives after the task has finished running. If you have manually changed the thumbnail or reference display copy of a digital object via the user interface (see: Edit digital objects), these two will be replaced with digital object derivatives created from the master digital object.
For more information on this task and the options available, see: Regenerating derivatives.
Index your content after an import¶
After any kind of import, you’ll want to index your content so it can be searched by users. To do so, enter the following into the command-line:
php symfony search:populate
Tip
If you have used the --index option while running your command-line
imports, then you will not need to re-index - when used, the --index
option will progressively add records to the search index as they are
created during the import process.
For more information on search index population in AtoM, see: Populate search index.
Export CSV files from the command-line¶
In addition to bulk XML import and export, AtoM also includes tasks to export archival descriptions and authority records in bulk from the command-line in CSV format.
Jump to:
- Export archival descriptions in CSV from the command-line
- Export authority records in CSV from the command-line
Export archival descriptions in CSV from the command-line¶
The CSV export task is a command-line task that will allow a system administrator with access to the root AtoM directory to export some or all archival descriptions held in AtoM in CSV format. This template is the same as that used for CSV import, and the export produced can therefore also be used to import data into another AtoM instance.
Example use - run from AtoM’s root directory:
php symfony csv:export /path/to/my/export-location/example.csv
If you specify just a path to a directory, AtoM will generate a name for the CSV. If you wish to name your CSV file, then you can specify the target filename in the path (e.g. in the above example, “example.csv” is the target filename).
CSV export task options¶
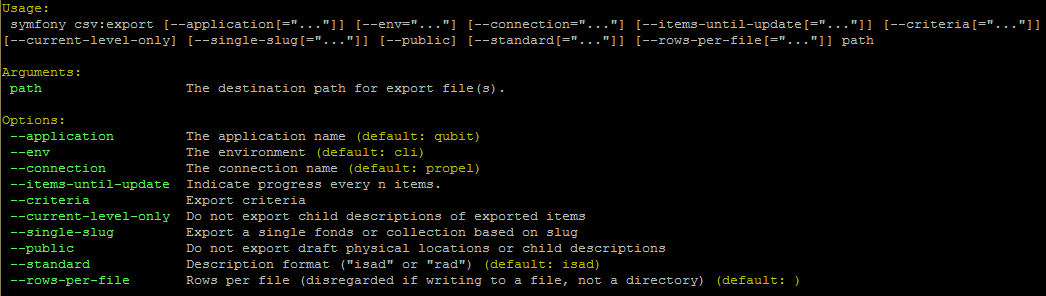
By typing php symfony help csv:export into the command-line from your root
directory, without specifying an export location of the CSV, you will able
able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the export.
The --items-until-update option can be used for a simple visual
representation of progress in the command-line. Enter a whole integer, to
represent the number of rows should be imported from the CSV before the
command-line prints a period (e.g. `` . `` ) in the console, as a sort of
crude progress bar. For example, entering --items-until-update=5 would
mean that the import progresses, another period will be printed every 5 rows.
This is a simple way to allow the command-line to provide a visual output of
progress.
The --criteria option can be added if you would like to use raw SQL to
target specific descriptions.
Example 1: exporting all draft descriptions
php symfony csv:export --criteria="i.id IN (SELECT object_id FROM status
WHERE status_id = 159 AND type_id = 158)" /path/to/my/exportFolder
If you wanted to export all published descriptions instead, you could simply
change the value of the status_id in the query from 159 (draft) to 160
(published).
Example 2: exporting all descriptions from a specific repository
To export all descriptions associated with a particular archival institution, you simply need to know the slug of the institution’s record in AtoM. In this example, the slug is “example-repo-slug”:
php symfony csv:export --criteria="i.repository_id = (SELECT object_id FROM
slug WHERE slug='example-repo-slug')" /path/to/my/exportFolder
Example 3: exporting specific descriptions by title
To export 3 fonds titled: “779 King Street, Fredericton deeds,” “1991 Canada Winter Games fonds,” and “A history of Kincardine,” You can issue the following command:
sudo php symfony csv:export --criteria="i18n.title in ('779 King Street,
Fredericton deeds', '1991 Canada Winter Games fonds', 'A history of
Kincardine')" path/to/my/exportFolder
You could add additional archival descriptions of any level of description into the query by adding a comma then another title in quotes within the ()s.
The --current-level-only option can be used to prevent AtoM from exporting
any children associated with the target descriptions.
If you are exporting fonds, then only the fonds-level description
would be exported, and no lower-level records such as series, sub-series,
files, etc. This might be useful for bulk exports when the intent is to submit
the exported descriptions to a union catalogue or regional portal that only
accepts collection/fonds-level descriptions. If a lower-level description
(e.g. a series, file, or item) is the target of the export, its
parents will not be exported either.
The --single-slug option can be used to to target a single archival
unit (e.g. fonds, collection, etc) for export, if you know the slug of
the target description.
Example use
php symfony csv:export --single-slug="test-export"
/path/to/my/directory/test-export.csv
The --public option is useful for excluding draft records from an export.
Normally, all records in a hierarchical tree will be exported regardless of
publication status. When using the --public option, only records
with a publication status of “Published” will be exported.
Important
If you are planning on re-importing your CSV export into another AtoM
instance, and you are using the --public option, you will need to ensure
that there are no published records that are children
of draft parents. If so, your re-import may fail!
AtoM uses the legacyID and parentID columns to manage hierarchical
relationships - but if the parent record is draft (and therefore excluded
from the export), then the parentID value for the published (and
exported) child record will point to a legacyID that is not included in
the export. We recommend you either remove such rows before trying to
re-import, or publish the parent record prior to exporting.
For more information on the legacyID and parentID columns, and how
AtoM manages hierarchical data via CSV import, see:
Legacy ID mapping: dealing with hierarchical data in a CSV and LegacyID and parentID.
The --standard option allows you to determine if the Canadian
RAD template or the international
ISAD(G) template is used when exporting. The default if
the option is not specified is ISAD(G). AtoM maintains several different
standards-based templates (see: Descriptive standards) and there are
currently 2 different CSV import/export templates - the default ISAD(G)
template, and the Canadian RAD template (because there are many different
fields in the RAD template). Other standards-template users (such as
DACS users) are encouraged to use the ISAD template.
The --rows-per-file option can be used when performing large exports, to
break the export into multiple CSV files. You can specify a whole integer
representing the number of rows to be included in a single CSV file, before
the export task will begin a new CSV. When invoking the task, remember to
specify the destination target to a directory, not a filename.
Example use
php symfony csv:export --rows-per-file="1000" /path/to/my/export-directory/
In the above example, when 1000 rows are added to the first CSV, AtoM will export it, and begin a second CSV - and so on.
Export authority records in CSV from the command-line¶
The CSV authority export task is a command-line task that will allow a system administrator with access to the root AtoM directory to export some or all authority records held in AtoM in CSV format. This template is the same as that used for the authority record CSV import, and the export produced can therefore also be used to import data into another AtoM instance.
Example use - run from AtoM’s root directory:
php symfony csv:authority-export /path/to/my/export-location/example.csv
If you specify just a path to a directory, AtoM will generate a name for the CSV. If you wish to name your CSV file, then you can specify the target filename in the path (e.g. in the above example, “example.csv” is the target filename).
If your database includes relationships between authority records, these will
exported along with the authority records CSV file in a separate relations
CSV file.
CSV authority export task options¶
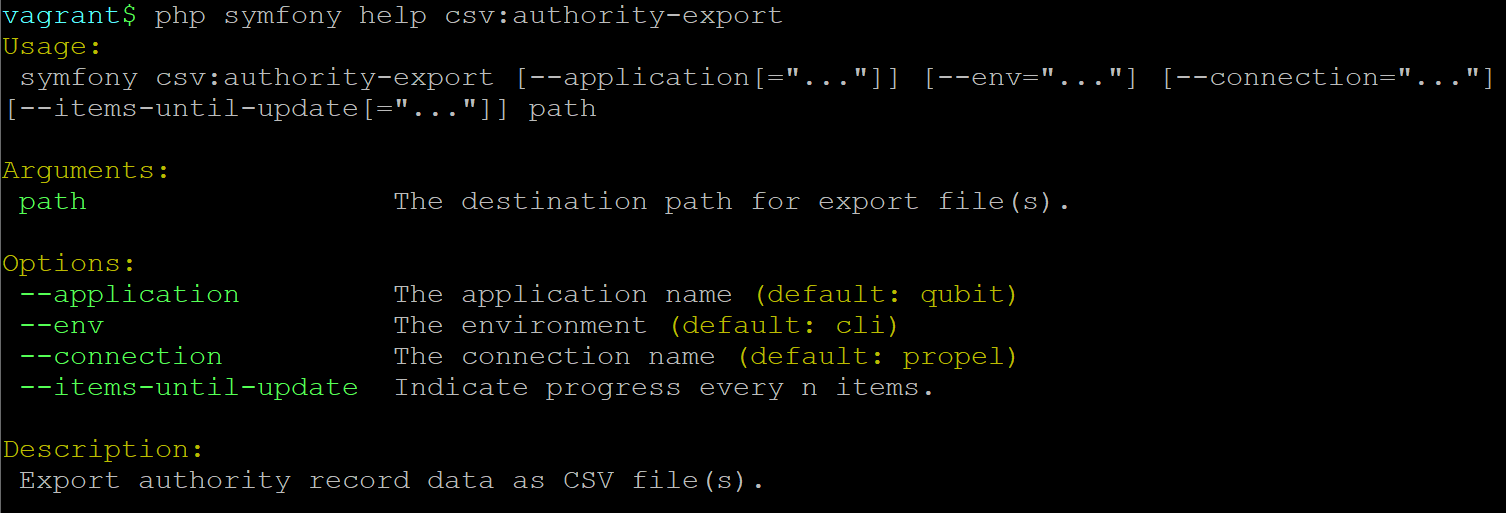
By typing php symfony help csv:export into the command-line from your root
directory, without specifying an export location of the CSV, you will able
able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the export.
The --items-until-update option can be used for a simple visual
representation of progress in the command-line. Enter a whole integer, to
represent the number of rows should be imported from the CSV before the
command-line prints a period (e.g. `` . `` ) in the console, as a sort of
crude progress bar. For example, entering --items-until-update=5 would
mean that the import progresses, another period will be printed every 5 rows.
This is a simple way to allow the command-line to provide a visual output of
progress.