CSV Validation¶
AtoM has the ability to import descriptive metadata in CSV format, both via the command-line and the user interface - see CSV import for more information.
However, properly formatting and structuring metadata in a CSV file can sometimes be a complex process, particularly with hierarchical metadata such as an archival unit. Additionally, an improperly formatted import file can potentially cause an error to abort the import process midway, leaving incomplete data when the import terminates. This can sometimes lead to data corruption, requiring further action from a system administrator to resolve.
To help avoid unexpected CSV import problems, AtoM includes a CSV validation task that can check for and report on common issues found in CSV files prior to import. This task can be run from the command-line, and is also supported in the user interface and run asynchronously by the job scheduler. An administrator can also configure validation to be run automatically before any CSV import performed via the user interface.
Note
To import and validate CSV files, a user must be logged in as an administrator. For more information on user groups and permissions, see:
This page will cover how to run CSV validation via the user interface, how to interpret the results of the validation report and resolve commonly reported issues, and how to configure validation to run automatically before any CSV import.
Jump to:
- CSV validator import settings
- Validate a CSV via the user interface
- CSV validation report structure
- CSV validation test classes
- CSV validation tests - all entities
- CSV validation tests - descriptions
- CSV validation tests - archival institutions
See also
All AtoM CSV templates can be found on the AtoM wiki:
CSV validation and import can also be completed by a system administrator via the command-line interface. For more information, see The Administrator’s Manual:
For other import options, see:
CSV validator import settings¶
In addition to being able to run CSV validation on its own either via the user interface or the command line, it is also possible for an administrator to configure AtoM to run validation automatically before any CSV import performed via the user interface.
This can be configured via  Admin > Settings > CSV Validator.
Admin > Settings > CSV Validator.
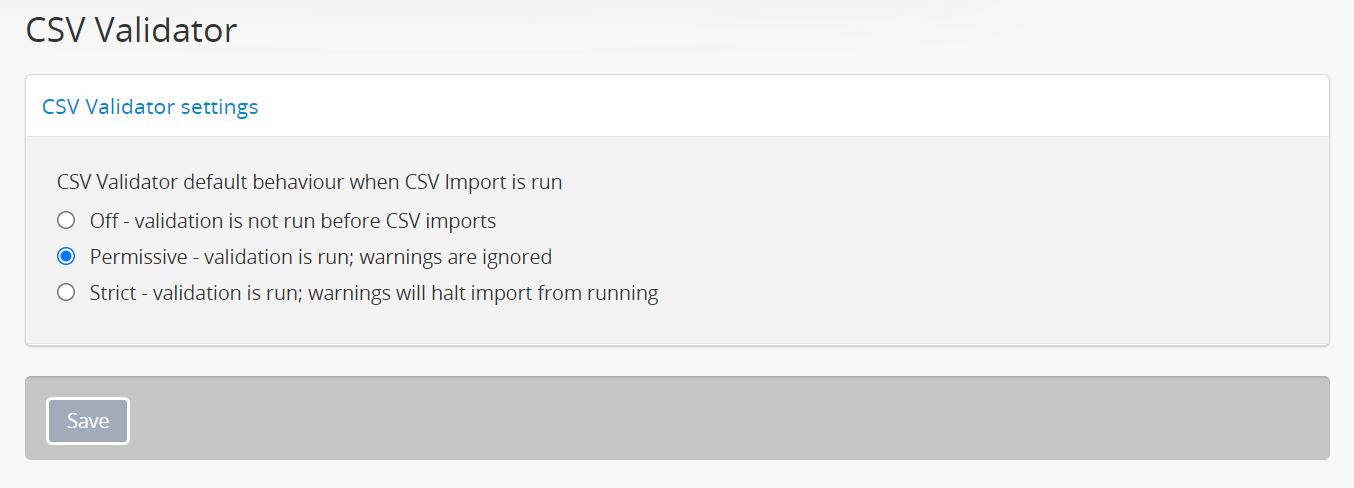
For further information on the supported options, see:
Validate a CSV via the user interface¶
This section will describe how to validate a CSV via the user interface. Validation can be performed independently of import, allowing users to check CSV files for common issues before proceeding with an import.
When performed via the user interface, CSV validation can be accessed via the
 import menu. The validation will be run
asynchronously as a job, and the validation results will be available
on the related job details page - for more information on
managing jobs, see: Manage jobs.
import menu. The validation will be run
asynchronously as a job, and the validation results will be available
on the related job details page - for more information on
managing jobs, see: Manage jobs.
The command-line task used to run validation has
two report output modes - by default, a short version of the report is used,
but users can specify a --verbose option for additional details to be
included in output. When run via the user interface, the output shown in the
console section of the related job details page will show
the short report. The longer detailed report is available on the jobs page as
a downloadable TXT file. For more information on the differences between the
two outputs, see:
To validate CSV files, a user must be logged in as an administrator. For more information on user groups and permissions, see:
To validate a CSV file:
- Click on the Import menu, located in
the AtoM header bar, and select “CSV”.
- AtoM will redirect you to the CSV validation page, where you can configure your validation settings
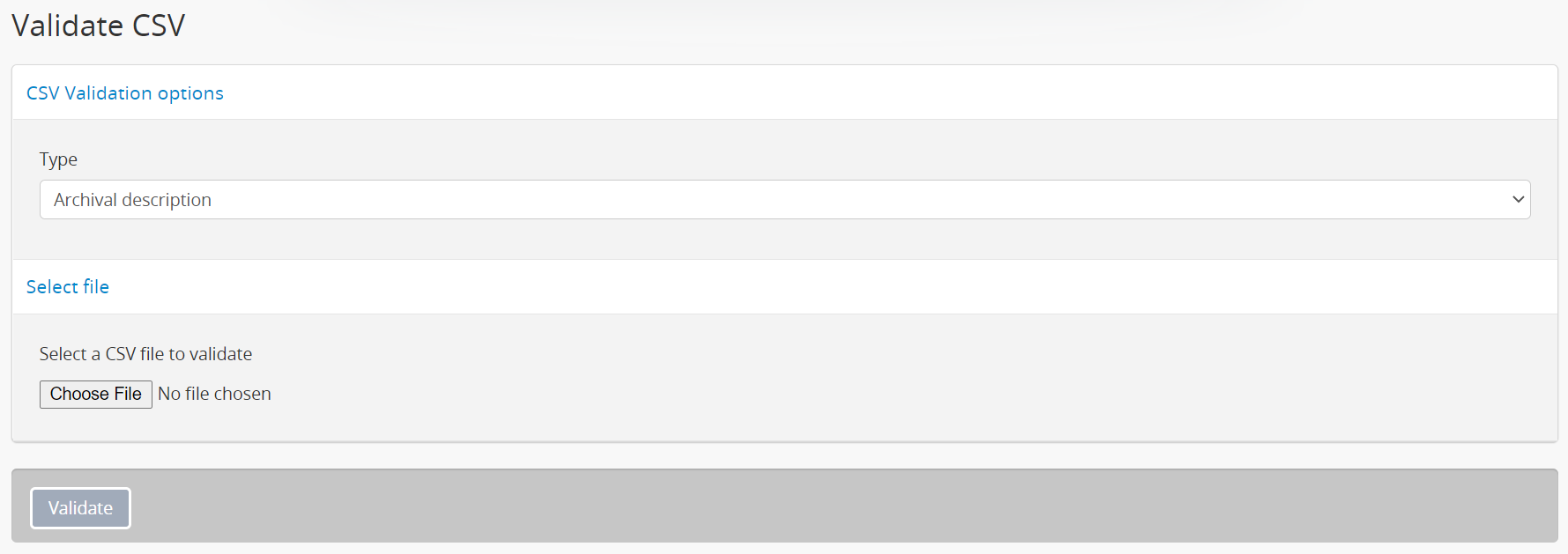
- Use the “Type” drop-down menu to select the entity type of
your CSV import template. Types currently supported include:
- Archival description
- Accession record
- Authority record
- Authority record relationships
- Event
- Archival institution
See also
All AtoM CSV templates can be found on the AtoM wiki:
For more information on how to prepare CSV files for import into AtoM, see:
- Click the “Choose File” button to open a local file explorer - use it to select the CSV file you would like to validate from your local computer. When you have selected the file from your device, its name will appear next to the “Choose File” button.
- When you have configured all the inputs, click the “Validate” button found in the button block at the bottom of the page to launch the validation task.
- Upon launching, AtoM will reload the page and display a notification at the
top of the page confirming that the CSV validation has been initiated. The
notification will also provide you with a link to the
Job details page of the related validation job, where
you will be able to find the results once completed. Alternatively, you can
navigate there using the Manage menu, by
selecting
 Manage > Jobs and then clicking on the related job.
For more information on jobs, see: Manage jobs.
Manage > Jobs and then clicking on the related job.
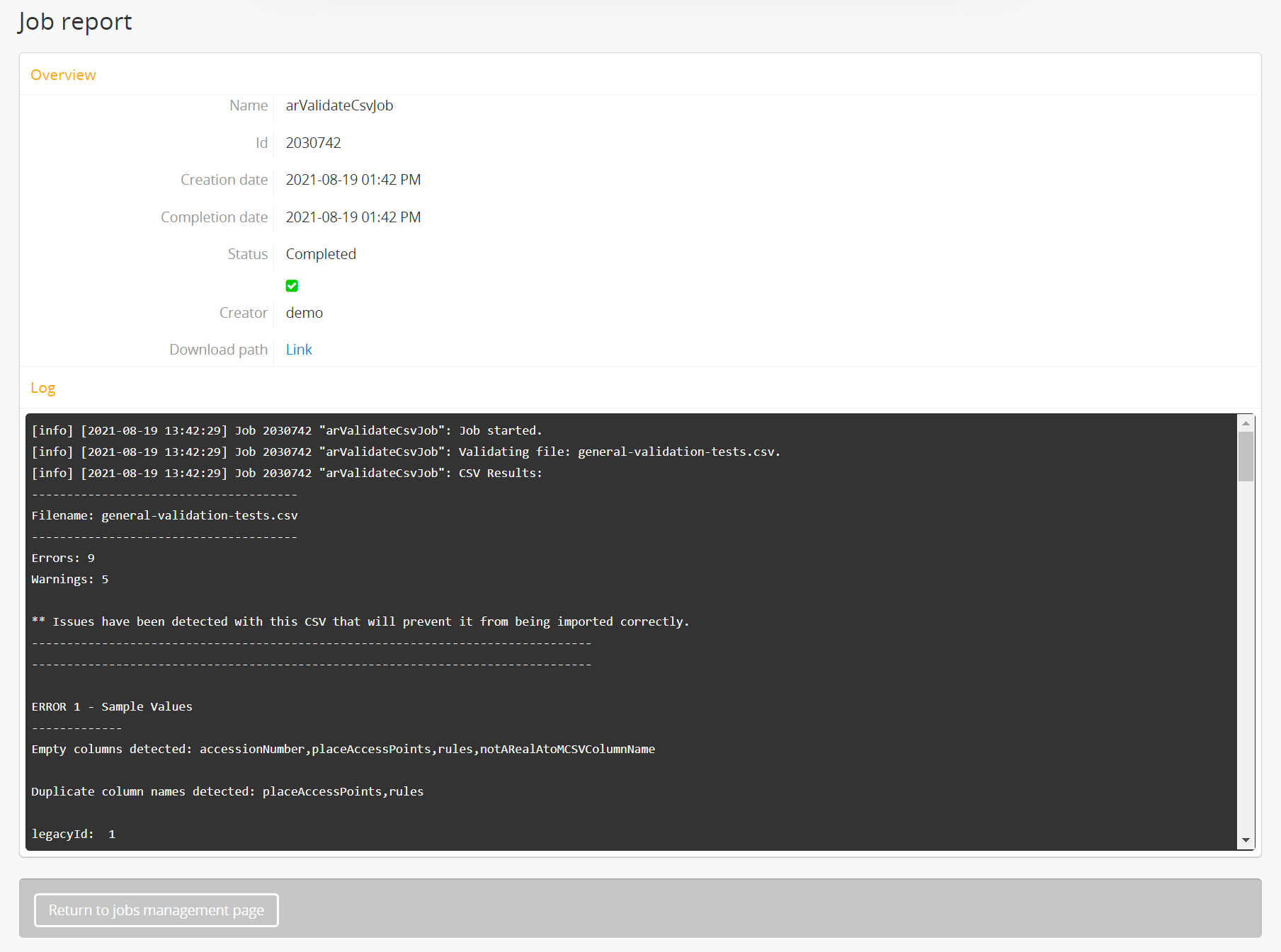
For more information on jobs, see: Manage jobs. - The related Job details page will display a short summary version of the validation report in the console log. Additionally, you can click the hyperlink in the Overview section of the job details page to download a more detailed report, which will include further information on the results of each each. See below for additional information on how to interpret the results.
See also
The command-line version of the validation task includes some additional configuration options not currently supported in the user interface. For more information, see:
CSV validation report structure¶
This section will provide an overview of how the validation results are structured, including the difference between the short summary output shown in the related job details page and the more detailed downloadable TXT file version, the various message types found in the report, and the available test classes that can be run against different AtoM entity types and CSV import templates.
Jump to:
Short vs detailed report modes¶
CSV validation in AtoM is handled by a command-line task - when run via the user interface, it is handled as a job that runs asynchronously in the background until completed. Results can be found on the related job details page.
The CLI task has two primary report modes - the default shorter report that
only includes high-level information on validation
errors and
warnings, and an
additional --verbose task option that when used, will output a more
detailed version of the report. This verbose task option includes additional
details in the resulting report on each error and warning found, which should
help you to locate and resolve the related issue. Sometimes this will include
affected row numbers; in other cases it will output problematic values found
or even the entire affected row.
The detailed report may also contain info messages, providing further information to help you assess the validity of your CSV file. See below for more information on validation message types.
Short vs detailed reports in the user interface
In the user interface, the output shown in the console log of the related job details page will always be the short report. Clicking the “Link” hyperlink in the summary section of the job details page will allow you to download the detailed validation report as a TXT file that can be opened locally.
Tip
If you are unsure where to find an error or warning identified in your CSV by the validation process, we recommend checking the downloadable detailed report for further information.
Validation report summary and body¶
Both versions of the validation report begin with a high-level summary. This section includes the name of the CSV file processed, as well as a count of errors and warnings found during the validation process. The body of the report is separated from this summary by two long lines made of dashes. Below is an example of the summary section from a validation report:
CSV Results:
-------------------------------------
Filename: my-example-descriptions.csv
-------------------------------------
Errors: 3
Warnings: 3
** Issues have been detected with this CSV that will prevent it from being imported correctly.
------------------------------------------------------------------------------
------------------------------------------------------------------------------
Below these line breaks the outcome of each validation test will be shown in the body of the report. The report body will always be structured so that errors are shown first, followed by warnings, and then (in the verbose output) any additional info messages.
Errors and warnings will be numbered, to better correspond to the count shown in the summary header of the report.
Below is an example of an error message from the body of a validation report:
ERROR 1 - Duplicate Column Name Check
---------------------------
Columns with name 'placeAccessPoints': 2
Columns with name 'rules': 2
Validation message types¶
The validation report can contain three different types of messages - errors, warnings, and info messages. By default, only errors and warnings are included in the short report shown in the console log output of the related job details page. The downloadable detailed report will also include additional info messages. Details on each type of message are included below.
Jump to:
Important
Each test class may have one or more tests that can be run. Each check will only have one section in the resulting report.
In the resulting validation report, ERROR messages are always prioritized, and appear first in the body of the report in numbered sequential order. However, a single test class may find issues that return both warnings and errors. In this case, the warning messages will be included under the error message heading.
An example:
ERROR 4 - Culture Check
-------------
Rows with blank culture value: 3
Rows with invalid culture values: 1
Rows with pipe character in culture values: 1
'culture' column does not allow for multiple values separated with a pipe '|' character.
Invalid culture values: notACultureCode, en|fr|es
Rows with a blank culture value will be imported using AtoM's default source culture.
This Culture check test result includes both warnings and errors. Rows with blank culture values will only trigger a WARNING because AtoM’s default fallback behavior when no culture value is provided for a given row is to use the default installation culture. However, rows with invalid culture values or pipe-separated values will trigger an ERROR, halting an import from proceeding.
Because errors are prioritized in the report and appear first, the Culture
Check test has been given an ERROR heading, though the tests performed
as part of the Culture Check have found both warnings and errors.
ERROR¶
An error identifies and issue that will either cause an import to fail, or else is likely to lead to unexpected and undesireable results. Imports that fail midway through may also cause data corruption, requiring further action from a system administrator to resolve. These issues are the ones you should definitely review and resolve before attempting to proceed with an import.
Tip
To prevent CSV imports with known issues from importing, an administrator can configure CSV validation to automatically run before any import attempt performed via the user interface. For more information, see: CSV Validator settings.
Examples of issues that will lead to error reports during validation:
- The file does not appear to be UTF-8 compatible
- CSV column header names are duplicated (e.g. there is more than one
legacyIdcolumn, etc.) - Two rows in row have the same
legacyIdvalue AND the sameculturevalue (suggesting they are not translation import rows) - A pipe separator character (
|) has been found in theculturecolumn, a column that does not accept multiple values per row - Invalid values have been found in AtoM’s language, script, or culture columns
- The CSV includes rows that are completely blank (resulting in blank descriptions on import)
- The header column is blank
- Etc.
Warning
Attempting to import a CSV with known errors in it may lead to data corruption, requiring further action from a system administrator to resolve. We strongly recommend fixing these issues until validation passes without errors before importing.
WARNING¶
A warning in a validation report is less severe than an error, but still worthy of review. Warnings are based on common user errors that may lead to unexpected results. In most cases, they will not cause imports to fail because AtoM has defaults in place when encountering such scenarios - however, the fallback default behaviors may not be the desired outcome. As such, you should carefully review any warnings received during validation before proceeding, and address them on a case-by-case basis as needed.
For example: an archival description CSV can successfully import
without a legacyId column present. However, not including legacy ID values
can make future update imports more
difficult. Consequently, if no legacyId column is found in the CSV
submitted for validation, AtoM will issue a warning as a reminder.
Similarly, the qubitParentSlug and parentId columns can be used for
managing archival description
hierarchical relationships in a CSV. Users
can populate both columns as needed in a CSV, but both columns should not
be populated in a single row. If AtoM encounters a single row that has both
columns populated, the default fallback behavior is to ignore the parentId
value and use the slug found in the qubitParentSlug column instead.
However, since there is no reason to ever populate both, this suggests a user
data entry error - so AtoM will output a warning if it finds both columns
populated in a single row.
Other validation warning examples:
- Neither
qubitParentSlugnorparentIdcolumns are found in a description CSV. The default import behavior will be to import all rows as top-level descriptions. - The
culturecolumn is not present in the CSV. The default import behavior will be to use the default application culture defined during installation. - The CSV contains unrecognized column header names. The default import behavior will be to ignore these columns.
- The CSV contains values in both of the
digital object-related columns
(i.e.
digitalObjectPathanddigitalObjectURI) for a single row. The default import behavior is to use the URI value and ignore the path value for that row. - A value found in the
repositorycolumn of a description CSV does not match any existing archival institution record. This warning is issued to avoid typos and minor spelling variations leading to accidental duplicate repository records. The default import behavior is to create a new stub repository record associated with the description during import. - Etc.
INFO¶
Finally, info messages are only included in the downloadable detailed version of the validation report. These are typically general information outputs intended to help a user determine if the CSV is well-formed and will import as expected. Unless something unexpected is seen in the output, no particular remedial action is necessary for info messages.
There are two types of info messages found in the detailed validation report. First, some messages include additional general information about the CSV, intended to aid in review. For example, the CSV column count check will tell you how many columns were found in the CSV:
INFO - CSV Column Count Check
----------------------
Number of columns in CSV: 59
There is also a sample values check, that will output the column header names and the first row of metadata as key/value pairs, so you can ensure that your data appears in the correct columns:
INFO - Sample Values
-------------
legacyId: 1
identifier: F1
title: Example fonds
levelOfDescription: Fonds
extentAndMedium: Example fonds Extent and medium (ISAD 3.1.5)
repository: Example Repository
...
[etc]
The other type of info message output is for tests that are either skipped because the necessary columns or values are not present, or for tests that have passed. Some examples:
INFO - UTF-8 File Encoding Check
-------------------------
File encoding is UTF-8 compatible.
INFO - Column Name Validation
----------------------
Number of unrecognized column names found in CSV: 0
INFO - Duplicate Column Name Check
---------------------------
No duplicate column names found.
INFO - CSV Empty Row Check
-------------------
CSV does not have any blank rows.
CSV validation test classes¶
Each test that is run as part of the validation process belongs to a test class
focused on a specific part of the validation process. Some test classes may have
more than one test - for example, the CsvCultureValidator class has a number
different checks it will perform, leading to 5 different possible outputs:
- If the culture column is not present, it will produce a WARNING about using the default installation culture
- If the culture column has some blank values, it will also produce a WARNING about using the default installation culture for the blank rows
- If the test identifies invalid culture values, it will emit an ERROR
- If a pipe separator is found in one of the rows of the culture column, it will emit an ERROR
- If all culture column values are populated and valid, the detailed report will include an INFO message confirming this
For further details on this particular test suite, see:
While most tests can be run against any CSV template, some tests will only apply to specific entity types. Below is a summary of the available test classes, and what Entity types the test class can be run against.
Tip
The command-line CSV validation task includes an option that will allow you to run only a subset of the available tests, by inputting the target class names. For more information, see:
| Test class name | Supported entity type(s) |
|---|---|
| CsvSampleValuesValidator | All entities |
| CsvFileEncodingValidator | All entities |
| CsvColumnNameValidator | All entities |
| CsvColumnCountValidator | All entities |
| CsvDigitalObjectPathValidator | Archival deccription |
| CsvDigitalObjectUriValidator | Archival description |
| CsvDuplicateColumnNameValidator | All entities |
| CsvEmptyRowValidator | All entities |
| CsvCultureValidator | All entities |
| CsvLanguageValidator | Archival description, Archival institution |
| CsvFieldLengthValidator | All entities |
| CsvParentValidator | Archival description |
| CsvLegacyIdValidator | Archival description |
| CsvEventValuesValidator | Archival description |
| CsvScriptValidator | Archival description |
| CsvRepoValidator | Archival description |
CSV validation tests - all entities¶
This section will cover tests that are run against all entity types in AtoM that support CSV import.
Jump to:
- Sample values check
- File encoding check
- CSV column count check
- Duplicate column name check
- CSV Empty Row Check
- Column Name Validation
- Culture check
- Field Length Check
Sample values check¶
- Test class: CsvSampleValuesValidator
The sample values check is normally an INFO message that
is included in the detailed report for all
entity types. It is useful for confirming at a glance that the
separator character is properly set (typically a comma in a CSV) - the task
will output the column headers and the first row of metadata output as key-value
pairs so you can check for example that the value under scopeAndContent is
in fact your scope and content statement for an archival description,
for example.
If the test finds empty columns (i.e. those columns that have a header but no metadata values in the body of the CSV), this will be included in output at the top. Note that this is not a warning or error specifically in this check - merely another informational element intended to help you determine if the CSV will import as expected.
Jump to:
ERROR - duplicate columns¶
However, the sample values task will throw an ERROR and appear early in the short report version if duplicate columns are detected. This is an error because when more than one column shares the same name, AtoM does not know which should be validated, used on import, or output as part of the sample values when running validation.
Recommendations
To correct this error, review the output from the Duplicate column name check for further information. Find the duplicate columns in your CSV and, once you have compared them and made any necessary updates, delete the duplicate column(s) and save the CSV before re-validating.
Sample output¶
ERROR 1 - Sample Values
-------------
Empty columns detected: accessionNumber,placeAccessPoints,rules,notARealAtoMCSVColumnName
Duplicate column names detected: placeAccessPoints,rules
legacyId: 1
identifier: F1
title: Example fonds
levelOfDescription: Fonds
extentAndMedium: Example fonds Extent and medium (ISAD 3.1.5)
repository: Example Repository
archivalHistory: Example fonds Archival history (ISAD 3.2.3)
acquisition: Immediate source of acquisition or transfer (ISAD 3.2.4)
scopeAndContent: Example fonds Scope and content (ISAD 3.3.1)
appraisal: Example fonds Appraisal, destruction and scheduling (ISAD 3.3.2)
accruals: Example fonds Accruals (ISAD 3.3.3)
arrangement: Example fonds System of arrangement (ISAD 3.3.4)
accessConditions: Example fonds Conditions governing access (ISAD, 3.4.1)
reproductionConditions: Example fonds Conditions governing reproduction (ISAD 3.4.2)
language: en|fr
script: Latn|Cyrl
[etc... truncated]
See also
File encoding check¶
- Test class: CsvFileEncodingValidator
This test will attempt to determine the character encoding of the CSV to determine if it is compatible with AtoM’s import requirements.
In computing, character encoding is a method used to represent the letters, numbers, and symbols used in textual commmunication. The character encoding represents the way that a coded character set is mapped to bytes for manipulation in a computer. As such, it provides a sort of key for converting the stored binary information into recognizeable symbols making up a character set. For more general information, see:
- https://en.wikipedia.org/wiki/Character_encoding
- https://www.w3.org/International/questions/qa-what-is-encoding
There are many different character encodings, and more than one character encoding can be used to store and represent a particular character set. Because of this, if the wrong encoding is applied to the bytes in memory, the result will be unintelligible text.
For a CSV file to upload properly into AtoM and display all characters as expected, your CSV file must use UTF-8 character encoding. UTF-8 is a widely supported Unicode Standard, that is the most common encoding used in email applications and on the web. As a web-based application, this is the character encoding that AtoM uses and expects for any incoming data.
Determining character encoding on a file can be a difficult. Not only does UTF-8 share some overlaps with other encoding schemes, but a UTF-8 encoded file such as a CSV may contain some non-UTF-8 characters - for example, if you were to cut and paste content from an application like Microsoft Word into a CSV, some characters may not be saved as UTF-8 depending on the settings of each file.
With this in mind, this suite of tests will attempt to look for common signfiers of UTF-8 encoding in the header of a file, and will also attempt to evaluate the characters themselves, to determine if any non-UTF-8 characters can be found in the CSV. If evidence of non-UTF-8 characters are found, the test will output an ERROR message.
Jump to:
- ERROR - This file includes a unicode BOM, but it is not UTF-8
- ERROR - File encoding does not appear to be UTF-8 compatible
- Sample output
ERROR - This file includes a unicode BOM, but it is not UTF-8¶
A byte order mark (BOM) is a hidden sequence of bytes at the start of a text stream used to indicate Unicode encoding of a text file. The presence of a BOM helps producers to indicate the character encoding used in a text-based file such as a CSV. BOM use is optional, and in fact is generally not recommended in UTF-8 files, but checking for a BOM in the header of a CSV may help determine if the CSV is encoded in UTF-16 or UTF-32 instead of AtoM’s expectation of UTF-8.
During validation, AtoM will check to see if a BOM is present in the header of the file. If there is a BOM, the validation test will then determine if it is a UTF-8 BOM. If it is not, AtoM will emit an ERROR message indicating that a BOM is present, but it is not a UTF-8 byte order mark.
Recommendation
Most spreadsheet applications and text editors should provide a “Save As” option that will allow you to set the character encoding used in your CSV file. Try re-saving your file and specifying UTF-8 encoding - an online web search should help you determine how to do so in your preferred application.
We recommend the use of LibreOffice Calc as an open source spreadsheet application for preparing and managing CSV import metadata. By default, Calc will allow you to configure the character encoding used to display a file each time it is opened, and offers a robust and easily accessible set of options for setting character encoding during saves.
ERROR - File encoding does not appear to be UTF-8 compatible¶
During the validation, AtoM will search the contents of the CSV for identifiable non-UTF-8 characters. If any are found, AtoM will emit an ERROR message indicating that the file’s character encoding does not appear to be UTF-8 compatible.
Recommendation
There are at least two ways in which this error might be triggered. The first is if the entire CSV uses a different character encoding.
If you have used a Windows or Mac spreadsheet application (such as Excel, for example), it’s possible that the default character encoding will not be UTF-8. For example, Excel uses machine-specific ANSI encoding as its defaults during install, so an EN-US installation might use Windows-1252 encoding by default, rather than something more universal such as UTF-8 (the default encoding in AtoM). This can cause problems on import into AtoM with special characters and diacritics. In the future, make sure that if you are using Excel or another spreadsheet application, you are setting the character encoding to UTF-8. Many open source spreadsheet programs, such as LibreOffice Calc, use UTF-8 by default, and include an easy means for users to change the default encoding.
To solve this first possibility, try re-saving your CSV with different options. Most spreadsheet applications and text editors should provide a “Save As” option that will allow you to set the character encoding used in your CSV file. Try re-saving your file and specifying UTF-8 encoding - an online web search should help you determine how to do so in your preferred application.
We recommend the use of LibreOffice Calc as an open source spreadsheet application for preparing and managing CSV import metadata. By default, Calc will allow you to configure the character encoding used to display a file each time it is opened, and offers a robust and easily accessible set of options for setting character encoding during saves.
Tip
For Excel users, here is an quick guide on converting CSV files to UTF-8:
However, in rare cases, a CSV that is properly encoded as UTF-8 can still contain non-UTF-8 characters. This can happen in cases where data has been cut and pasted from another application (for example, an MS Word document) that is not using UTF-8 encoding.
In this case, the detailed output included in the downloadable detailed report will include line numbers for the affected rows. Use this information to find and review the data. In some cases you may need to retype certain inputs once the file itself has been saved using UTF-8 encoding.
Note
To avoid outputting all row numbers in a CSV saved with the wrong character encoding, AtoM will only output the first 10 rows where non-UTF-8 characters have been identified.
If the output lists rows 1-10, this may suggest that the entire CSV is currently using the wrong encoding - try re-saving it as UTF-8 and re-validating.
If the output lists 10 random rows from your CSV, you can address any issues found in the reported rows, and then re-submit the CSV for validation to determine if any other rows are affected.
Sample output¶
ERROR 2 - UTF-8 File Encoding Check
-------------------------
File encoding does not appear to be UTF-8 compatible.
Count of UTF-8 incompatible CSV rows: 2
This file includes a unicode BOM, but it is not UTF-8.
Details:
Affected row numbers (first 10): 7, 11
CSV column count check¶
This test will compare the number of comma-separated values in a CSV, to determine if it is well-formed. A well-formed CSV file should be “square” - that is to say, every row and column should have the same amount of comma-separated values, even if some of those contain no user-entered metadata (i.e. blank cells shown in a spreadsheet application should not affect the squareness of a well-formed CSV).
If AtoM finds that some rows contain a different number of columns than others, the test will emit an ERROR message.
Jump to:
ERROR - CSV rows with different lengths detected¶
This validation ERROR occurs when AtoM detects that some rows in the CSV contain a different number of columns than others, suggesting that the CSV is not well-formed. A well-formed CSV file should be “square” - that is to say, every row and column should have the same amount of comma-separated values, even if some of those contain no user-entered metadata (i.e. blank cells shown in a spreadsheet application should not affect the squareness of a well-formed CSV).
Recommendation
There are a number of issues that can lead to a CSV appearing to be malformed during validation.
The first of these is if a different separator character is used. AtoM expects commas to be used to indicate cell divisions in an import file (hence the name, “comma-separated values”, or CSV). However, tabular text data can be separated a number of different ways, such as using tabs (TSV) instead. If you have used a spreadsheet application to prepare your data, you may not notice the difference, as the user inteface display in the application will still structure your data into rows and columns. Re-saving your file and ensuring you are saving it as a UTF-8 encoded CSV file may be one way to resolve this issue. If you’re unsure, you can also try opening the file in a text editor (such as NotePad on Windows; TextEdit on MacOS, etc) instead of a spreadsheet application. This will allow you to see the raw data without automatic formatting provided by a spreadsheet application’s user interface - your CSV row values should all be separated by commas in a well-formed CSV.
Warning
While viewing a CSV in a text editor can be helpful for troubleshooting, be extremely cautious about editing the CSV this way! If you accidentally delete a separator or other formatting character, you can end up introducing row-length errors in an otherwise well-formed CSV!
Another possible formatting issue is the use of unexpected string delimiter
characters in the CSV. Since commas can regularly appear in user-input
metadata added to a CSV, many spreadsheet applications will use a
string delimter to encapsulate cell values and ensure that inline commas are
not mistaken for separators. AtoM expects double quotations (") to be used
around user text as the string delimiter - but again, this may depend on the
settings of your spreadsheet application, and the use of a different string
delimiter can lead to errors when parsing the CSV, resulting in AtoM thinking
the CSV rows are uneven. Once again, viewing the CSV in a text editor is one
way of seeing how the metadata is formatted, and depending on your spreadsheet
application, re-saving and selecting different save options may allow you to
resolve this error.
Note
Just as you don’t need to manually add commas between your cell values, you do not need to manually enclose your metadata in double quotations when working in a spreadsheet application - this is handled automatically by the application, based on your settings. Inline quotations used in your metadata will also be automatically escaped so they are not mistaken for string delimiter characters.
We recommend the use of LibreOffice Calc as an open source spreadsheet application for preparing and managing AtoM CSV import metadata. By default, Calc will allow you to configure elements such as the character encoding, separator, and string delimiter used to display a file each time it is opened, and will provide a preview of the results of your selection before opening the file:
Calc also offers a robust and set of options for setting character encoding and other aspects during saves. Files created or edited in Calc and saved as UTF-8 CSV files will use comma separators and double quotation string delimiters by default.
Finally, in some cases this error may be caused by improper character encoding. If the encoding is not UTF-8, then commas in your CSV may not be rendered as expected, triggering the validation error. For further information and troubleshooting recommendations, see:
Sample output¶
ERROR 3 - CSV Column Count Check
----------------------
Number of rows with 59 columns: 2
Number of rows with 64 columns: 1
Number of rows with 61 columns: 12
CSV rows with different lengths detected - ensure CSV enclosure character is double quote ('"').
Duplicate column name check¶
- Test class: CsvDuplicateColumnNameValidator
This test will scan the column header names (i.e. the first row of the CSV) checking that all column names are unique in the file.
Jump to:
ERROR - Duplicate columns found¶
If any columns with the exact same name are identified, the test will output an ERROR.
The short version of the report shown in the console log of the related job details page will include the name of any duplicated columns, and a count of how many times they appear in the CSV. No additional information is provided in the detailed report.
Recommendation
The error message will include the names of the duplicate columns. Use this to review the CSV - find the duplicate columns in your CSV and, once you have compared them and made any necessary updates, delete the duplicate column(s) and save the CSV before revalidating.
Note
If duplicate values are found, this will also cause the Sample values check to emit an error, since the Sample values check does not know which column to use when outputting a sample.
Sample output¶
ERROR 4 - Duplicate Column Name Check
---------------------------
Columns with name 'placeAccessPoints': 2
Columns with name 'rules': 2
CSV Empty Row Check¶
- Test class: CsvEmptyRowValidator
This check will test to see if there are any rows in the CSV that are completely blank.
Jump to:
ERROR - Blank rows found¶
If any blank rows are found in the CSV, an ERROR message will be returned in the validation report. All blank rows are treated as errors, since the import code will create stub empty records when blank rows are encountered, requiring manual cleanup post-import. In some cases when this is a result of an incorrect line ending character, this can lead to thousands of unintentional blank rows being appended to the CSV.
Recommendation
The downloadable detailed report will also include a list of row numbers where the blank rows have been found - we recommend consulting this for guidance on where to find the reported issue.
If the blank row is in the middle of your metadata, it should be easy to find and delete using a spreadsheet application such as LibreOffice Calc.
If there are no obvious blank rows in your CSV, or else the blank rows appear at the end of the CSV, then viewing the file using a spreadsheet application may not make it obvious where the issue is or what caused the problem. You can try multi-selecting the blank rows at the bottom in a spreadsheet application and deleting them, but depending on the cause of the issue and the number of blank lines, this alone may not always resolve the problem.
In some cases, blank rows can be caused by improper
line ending characters - AtoM’s CSV import will expect
Unix-style line breaks ( \n ), and sometimes the line ending characters
used by other applications or other operating systems can have unexpected
results. If you have been using a spreadsheet application such as Excel on a
Mac or Windows, you may encounter line ending issues. Some options for
troubleshooting this:
- Consider using LibreOffice Calc to review and revise the CSV, and for CSV preparation in the future. Calc allows you to set the character encoding, separator, and delimiter values to be used every time you open a CSV, and seems to handle line-ending characters much better by default. We strongly recommend this over MS Excel for preparing AtoM CSV data for impot.
- Opening a CSV in a text editor can make locating blank rows easier - they
should appear as just a line of commas in a CSV - e.g.
,,,,,,,,,,,,,,,,etc. However, be very careful about editing the CSV in a text editor, particularly when trying to delete blank rows! If you end up with uneven rows (i.e. most rows have 60 columns but one or more now has only 59, etc) then your CSV will no longer be “square” and will trigger a different kind of error! This approach is best used for identification rather than direct manipulation. At the very least, save any manually edited CSV as a new version, rather than overwriting the current version. - There are many command-line utilities and free software options out there to convert newline characters. Again, we recommend creating a copy before experimenting with one of these solutions.
Sample output¶
ERROR 5 - CSV Empty Row Check
-------------------
CSV blank row count: 2
Details:
Blank row numbers: 14, 28
Column Name Validation¶
- Test class: CsvColumnNameValidator
This test will use the import configuration files found in
lib/flatfile/config to validate the column names included in an AtoM import
CSV. If the column names in your CSV are not found in the related configuration
file, are cased differently, or have leading or trailing whitespace present,
this test will emit a WARNING. Any unrecognized columns
will be ignored during import if they are not removed.
Jump to:
WARNING - Unrecognized column names¶
- Default behavior: Skip unrecognized columns during import
If any of the header column names in your import CSV do not match those found
in AtoM’s import configuration files (stored in AtoM at lib/flatfile/config),
this WARNING will be included in the resulting
validation report. The short version of the report shown in the console log
of the related job details page will include the
following information, depending on what is found:
- A count of unrecognized columns found in the CSV
- A list of unrecognized column names
- A count of column names that have leading or trailing whitespace
- A count of columns that may not be recognized due to differences in capitalization
Additionally, the downloadable detailed report will include:
- A list of column names with leading or trailing whitespace
- A list of column names that may not be recognized due to casing (i.e. variations in the expected capitalization of some letters)
Any unrecognized columns listed in the report will be skipped if left unchanged during a subsequent CSV import.
Recommendation
Use the list of column names included in the detailed report to review your CSV, and make adjustments as necessary.
If you would like to see a list of supported column names, you can either look
in the related local configuration file for your import entity type in
lib/flatfile/config; open one of the CSV import templates found on the
AtoM wiki and use it for comparison; or else look at the configuration files
in AtoM’s online code repository:
Replace any unsupported columns with the intended import column name.
Tip
If you would like to better understand how AtoM’s import columns map to
supported data entry fields in your chosen template, try importing one of
CSV import templates found on the AtoM wiki. Each field in these
templates is populated with example data that includes the name of the
related standards-based field - for example, the example data in the ISAD(G)
import template for the scopeAndContent field is “Example fonds Scope
and content (ISAD 3.3.1)”. Comparing the example data in your import
template with the resulting record in AtoM should help you better understand
how the column names map to AtoM’s standard-based data entry fields.
Additionally, see the following pages for further data entry guidance:
If there are whitespace issues reported, you may have unintentionally included space before or after the field title. You can open your CSV in a spreadsheet application and correct this manually. Alternatively, if you are having trouble finding or fixing the issue in a spreadsheet application, consider opening the file in a text editor - this should make it easier to find and fix any whitespace issues in the column header names.
Warning
While viewing a CSV in a text editor can be helpful for troubleshooting, be extremely cautious about editing the CSV this way! If you accidentally delete a separator or other formatting character, you can end up introducing row-length errors in an otherwise well-formed CSV!
We recommend saving a separate version of your CSV (i.e. “Save As”) if you are intending to edit your CSV this way, just in case you accidentally alter a separator or other character critical to the formatting of the CSV file.
If there are letter case issues reported, you can use the configuration files or the CSV import templates as a reference for how the column names should be properly cased. Fix any issues found - the detailed error message will also tell you what field AtoM thinks you are trying to reference, showing the expected case formatting of the column name:
Possible matches for scopeAndContent: ScopeandContent
Most fields in the CSV templates have been named in a fairly obvious way,
translating a simplified version of the field name in our data entry
templates into a condensed camelCase. For example, the Rules for Archival
Description’s (RAD) “General Material Designation” is
rendered in the CSV column header as radGeneralMaterialDesignation. In
both the RAD and ISAD(G) templates, the Scope and Content
field is mapped to the CSV column name scopeAndContent. However, for users
seeking a full mapping of fields, consult the Data entry / templates documentation.
Finally, in some cases this error may be caused by improper character encoding. If the encoding of your CSV is not UTF-8 as AtoM expects, then the column name headings in your CSV may not be rendered as expected, triggering the validation warning. This is likely the case if you see many or all of your CSV column name headers included in the detailed output of the validation check, and at a glance some or all appear to match AtoM’s expectations (e.g. they match those found in AtoM’s CSV import templates), as in the example below:
WARNING 1 - Column Name Validation
----------------------
Number of unrecognized column names found in CSV: 56
Unrecognized columns will be ignored by AtoM when the CSV is imported.
Unrecognized column names: legacyId,parentId,qubitParentSlug,accessionNumber,identifier,title,levelOfDescription,extentAndMedium,repository,archivalHistory,acquisition,scopeAndContent,appraisal,accruals,arrangement,accessConditions,reproductionConditions,language,script,languageNote,physicalCharacteristics,findingAids,locationOfOriginals,locationOfCopies,relatedUnitsOfDescription,publicationNote,digitalObjectPath,digitalObjectURI,generalNote,subjectAccessPoints,placeAccessPoints,nameAccessPoints,genreAccessPoints,descriptionIdentifier,institutionIdentifier,rules,descriptionStatus,levelOfDetail,revisionHistory,languageOfDescription,scriptOfDescription,sources,archivistNote,publicationStatus,physicalObjectName,physicalObjectLocation,physicalObjectType,alternativeIdentifiers,alternativeIdentifierLabels,eventDates,eventTypes,eventStartDates,eventEndDates,eventActors,eventActorHistories,culture
If this is the case, review the results of the character encoding validation check, and use the recommendations in this section of the documentation to resolve encoding issues before attempting to re-validate your CSV. For further information, see:
Sample output¶
WARNING 1 - Column Name Validation
----------------------
Number of unrecognized column names found in CSV: 3
Unrecognized columns will be ignored by AtoM when the CSV is imported.
Unrecognized column names: Generalnote, sources,notARealAtoMCSVColumnName
Number of column names with leading or trailing whitespace characters: 1
Number of unrecognized columns that may be letter case related: 1
Details:
Column names with leading or trailing whitespace: sources
Possible match for Generalnote: generalNote
Culture check¶
- Test class: CsvCultureValidator
This suite of tests will attempt to validate the values used in the culture
column of a CSV, a column that is available in almost all of AtoM’s
CSV import templates.
As an application with multilingual support,
most metadata elements can be created in multiple different languages. During
the installation process, a default culture for the application can be
configured, which is stored in a configuration file.
AtoM uses the ISO 639-1 two-letter language codes (e.g. en, fr,
es), with support for some localization codes (e.g. pt_BR) wherever
culture is used in the application - including in CSV import data. While an AtoM
installation may have only one default installation culture, data may be
created, imported, and/or managed in multiple languages in the application.
During import, the ISO 639-1 value added to the culture row of
a CSV will determine the language in which AtoM stores the import data.
AtoM also has the ability to import translations for archival descriptions,
which is done by including two sequential rows in an archival description
CSV with the same legacyId value, but different culture values - for
more information, see:
When the culture column value is blank for a specific row in an import CSV,
or else the column is not present at all in the CSV, AtoM will default to using
the default installation culture for any affected rows. Values in the
culture must be singular - you cannot add a | pipe separator to import
multiple culture values per row.
The Culture check task during CSV validation will attempt to assess the
validity of any values found in the culture column, based on these design
principles.
Jump to:
- ERROR - Culture column has invalid values
- ERROR - Rows with pipe character in culture values
- WARNING - Culture column has blank values
- WARNING - Culture column not present
- Sample output
ERROR - Culture column has invalid values¶
AtoM expects ISO 639-1 language codes to be used in the culture column -
these are typically two-letter codes, though in a few cases AtoM can support the
addition of ISO 3116 country codes to specify locale, such as pt_BR
(Portuguese Brazilian), fr_CH (Swiss French), etc. For a full list of
supported languages in AtoM, see:
AtoM maintains an internal list of these codes, and this validation test will
attempt to compare any values it finds in the culture column to those
maintained internally. If a mismatch is found, AtoM will emit an
ERROR.
Recommendation
The short validation report shown in the console log of the related job details page will provide a count of how many invalid culture values were found in the CSV. Meanwhile, the detailed output in the downloadable detailed report will also include affected line numbers to help you identify the problem rows.
Verify the values you have entered in these rows against the list of supported
culture values linked above, and make corrections as needed. Do not use
full language names (e.g. English) - only ISO 639-1 values (e.g. en)
will pass any future validation attempts.
ERROR - Rows with pipe character in culture values¶
AtoM expects each row to have only one value per row in the culture
column of an import CSV. While other similar metadata entry fields such as
language and languageOfDescription can support multiple values in a
single row via the use of a pipe separator (e.g. en|fr|es) to indicate
multilingual content, the culture column is used to tell AtoM what
language the record should be saved as in the database.
Recommendation
The short validation report shown in the console log of the related
job details page will provide a count of how many rows
have a pipe separator in the culture column of the CSV Meanwhile, the
detailed output in the downloadable
detailed report will also include affected
line numbers to help you identify the problem rows.
Review and update the values you have entered in these rows, and ensure that only one ISO 639-1 culture value is entered per row.
If you are trying to create both the source metadata and translations of a record via a single import, this is currently only supported for archival descriptions. For more information on how to import translations, see:
WARNING - Culture column has blank values¶
- Default behavior: Use installation culture
This WARNING is provided when a culture column is
present in the CSV, but one or more rows do not contain a value.
A culture column, or a value in the culture column per row, is not
required for an import to succeed. However, without specifying a value, AtoM
will use the default installation culture (i.e. the application language
specified during installation, and stored in a
configuration file).
Recommendation
The short validation report shown in the console log of the related
job details page will provide a count of how many rows
have no value entered in the culture column of the CSV. Meanwhile, the
detailed output in the downloadable
detailed report will also include affected
line numbers to help you identify the problem rows.
If your import metadata is in the same language as the default language of your AtoM installation (i.e. typically the language of the user interface when you first visit AtoM), then no action is needed - AtoM’s default fallback behavior when no culture value is found for a row is to use the default installation culture. Alternatively, add a supported ISO 639-1 culture code to the affected rows before re-validating the CSV. For a full list of supported languages in AtoM and their related codes, see:
If you are uncertain as to the default installation culture of your AtoM
installation, a system administrator can check by looking in the configuration
file found at apps/qubit/config/settings.yml For more information, see:
WARNING - Culture column not present¶
- Default behavior: Use installation culture
This WARNING is provided when there is no culture
column present in the CSV.
A culture column is not required for an import to succeed. However,
without specifying a value, AtoM will default to using the default installation
culture (the default application language specified during installation, and
stored in a configuration file).
Recommendation
If your import metadata is all in one language, and this is the same language as
the default language of your AtoM installation (i.e. typically the language of
the user interface when you first visit AtoM), then no action is needed
- AtoM’s default fallback behavior when no culture value is found for a row is
to use the default installation culture. Alternatively, add a culture
column to the CSV and one supported ISO 639-1 culture code per row before
re-validating the CSV.
If you are uncertain as to the default installation culture of your AtoM
installation, a system administrator can check by looking in the configuration
file found at apps/qubit/config/settings.yml For more information, see:
Sample output¶
ERROR 6 - Culture Check
-------------
Rows with blank culture value: 3
Rows with invalid culture values: 1
Rows with pipe character in culture values: 1
'culture' column does not allow for multiple values separated with a pipe '|' character.
Invalid culture values: notACultureCode, en|fr|es
Rows with a blank culture value will be imported using AtoM's default source culture.
Details:
CSV row numbers where issues were found: 5, 6
See also
Field Length Check¶
- Test class: CsvFieldLengthValidator
This suite of tests will check the length of values entered into any
culture, language, or script fields found in a CSV. If any row
value in one of these columns exceeds a designated maximum number of
characters, a WARNING will be returned in the resulting
validation report.
These checks are meant to reinforce other existing related tests, including:
- Culture check
- Language check (descriptions)
- Language check (repositories)
- Script of description check
AtoM expects any language, culture, or script values to use established ISO codes:
cultureandlanguagecolumns (includinglanguageOfDescriptionon archival descriptions) expect two-letter ISO 639-1 language codes as input. In some cases, locale extensions (such aspt_BR) are also supported. For a full list of supported languages in AtoM, see: https://bit.ly/AtoM-langsscriptcolumns expect four-letter ISO 15924 script code values that capitalize the first code letter - for example, “Latn” for Latin-based scripts, “Cyrl” for Cyrillic scripts, etc. See Unicode for a full list of ISO 15924 script codes.
Though valid values will in most cases be shorter than the set limits, the current test limits account for edge cases. Current maximum expected value length for each field type:
- Culture values: 11
- Language values: 6
- Script values: 4
Note that the language and script columns can accept multiple
pipe-separated values per row (e.g. en|fr|es). Correspondingly, the test
will check each pipe-separated value individually, and not the full combined
string length during validation. The culture column does not accept
pipe-separated values.
This suite of tests will not produce ERROR messages when encountering values in the target columns that exceed the maximum characters - instead, they will issue a warning. Error reporting depends on the related tests linked above.
Jump to:
- WARNING - ‘culture’ column may have invalid values
- WARNING - ‘language’ column may have invalid values
- WARNING - ‘script’ column may have invalid values
- Sample output
WARNING - ‘culture’ column may have invalid values¶
This WARNING is provided when one or more values in the
culture column exceeds 11 characters.
AtoM expects ISO 639-1 language codes to be used in the culture column -
these are typically two-letter codes, though in a few cases AtoM can support the
addition of ISO 3116 country codes to specify locale, such as pt_BR
(Portuguese Brazilian), fr_CH (Swiss French), etc.
The short report shown in the console log of the related job details page will include a count of rows that have values that exceed the 11 character limit. The downloadable detailed report will also include an output of the problematic values in the Details section.
Recommendation
Use the values provided in the Details section of the report to search your CSV and identify the problem culture values. Ensure that only supported ISO 639-1 language values are used - replace any problem values with the appropriate language code before re-validating.
For a full list of supported languages and related codes in AtoM, see:
Note that the culture column does not support multiple values per row
- pipe separated values (e.g. en|fr|es) will trigger an error on import.
For archival descriptions, it is possible to
import rows as translations of another row - for more information on how to
properly prepare this in your CSV, see: Importing translations.
See also
WARNING - ‘language’ column may have invalid values¶
This WARNING is provided when one or more values in the
language column exceeds 6 characters.
AtoM expects ISO 639-1 language codes to be used in the language column -
these are typically two-letter codes, though in a few cases AtoM can support the
addition of ISO 3116 country codes to specify locale, such as pt_BR
(Portuguese Brazilian), fr_CH (Swiss French), etc.
This column can accept multiple pipe-separated values per row - for example, to
list English, Spanish, and French as the languages of a record, you can enter
en|es|fr in the appropriate CSV row. When encountering pipe separators in
the language column during validation, AtoM will only apply the character
limit to each individual value and not the entire string.
The short report shown in the console log of the related job details page will include a count of rows that have individual values that exceed the 6 character limit. The downloadable detailed report will also include an output of the problematic values in the Details section.
Recommendation
Use the values provided in the Details section of the report to search your CSV and identify the problem language values. Ensure that only supported ISO 639-1 language values are used - replace any problem values with the appropriate language code before re-validating.
For a full list of supported languages and related codes in AtoM, see:
WARNING - ‘script’ column may have invalid values¶
This WARNING is provided when one or more values in the
script column exceeds 4 characters.
AtoM expects ISO 15924 script codes to be used in the script column - these
are typically four-letter codes where the first letter is capitalized. See
Unicode for a full list of ISO 15924 script codes.
This column can accept multiple pipe-separated values per row - for example, to
list Latin and Coptic as the scripts of a record, you can enter
Latn|Copt in the appropriate CSV row. When encountering pipe separators in
the script column during validation, AtoM will only apply the character
limit to each individual value and not the entire string.
The short report shown in the console log of the related job details page will include a count of rows that have individual values that exceed the 4 character limit. The downloadable detailed report will also include an output of the problematic values in the Details section.
Recommendation
Use the values provided in the Details section of the report to search your CSV and identify the problem script values. Ensure that only supported ISO 15924 script code values are used - replace any problem values with the appropriate script code before re-validating. See Unicode for a full list of ISO 15924 script codes.
See also
Sample output¶
WARNING 2 - Field Length Check
------------------
Checking columns: culture,language,script
'culture' column may have invalid values.
'culture' values that exceed 11 characters: 1
'language' column may have invalid values.
'language' values that exceed 6 characters: 1
'script' column may have invalid values.
'script' values that exceed 4 characters: 3
Details:
culture column value: notACultureCode
language column value: English
script column value: Latin and Coptic
script column value: Latin|Coptic
CSV validation tests - descriptions¶
This section describes supplementary tests that are run when an archival description import CSV is submitted for validation, in addition to the general validation tests run for all entity types.
Jump to:
- LegacyId check
- Parent check
- Event value count test
- Repository check
- Digital object path check
- Digital object URI check
- Language check (descriptions)
- Script of description check
LegacyId check¶
- Test class: CsvLegacyIdValidator
This suite of tests will attempt to validate the legacyId values present in
an archival description CSV import template. While a legacy ID value
is not required per row for a CSV to successfully import, it is used for a
number of purposes, including:
- Hierarchical arrangement of rows within a description CSV, when paired with
parentIdvalues - Migration from legacy systems - AtoM can store the unique identifier from
the source system as a
legacyIdvalue during import, making audit and troubleshooting post-import easier - Import updates - AtoM will use the
legacyIdvalue from previous imports as one of the matching criteria when an update import is performed. - Importing translations of archival description metadata
For more information on these uses and on the legacyId column in general,
see:
- Legacy ID mapping: dealing with hierarchical data in a CSV
- LegacyID and parentID
- Update existing descriptions via CSV import
- Importing translations
Typically, AtoM expects every legacyId value in a CSV template to be unique
(the one exception to this being
translation rows) and present for all
rows. Two sequential non-unique legacyId values in the same CSV that are
not part of a translation import (i.e. they are co-located, but do not have
different culture values as expected with a translation import) will cause
an ERROR on import. Additionally, because the legacyId
value is useful for many other purposes during import, validation will also
emit a WARNING when the column is missing, or some rows
are missing values, or duplicate IDs are found that are not co-located
sequentially. More information on each validation check is included below.
Jump to:
- ERROR - Rows with non-unique ‘legacyId’ values
- WARNING - Rows with non-unique ‘legacyId’ values
- WARNING - Rows with empty ‘legacyId’ column
- WARNING - ‘legacyId’ column not present
- Sample output
ERROR - Rows with non-unique ‘legacyId’ values¶
This ERROR message is returned when AtoM detects that
two co-located rows (i.e. one directly following the other in the CSV row
ordering) in the CSV contain identical legacyId values, and also the same
culture values.
AtoM uses sequentially co-located rows in an archival description CSV
import that have the same legacyId values but different culture
values as a method of
importing translations. When found in a
well-formed CSV, the first row will be imported as the source version of the
description, while the subsequent row will import as a translation of the
previous row in the language specified by the second culture value.
The AtoM data model does not support two different versions of an entity’s metadata importing with the same culture value - consequently, if two rows are found together with the same ID and the same culture value, an import error will be triggered.
When this error is encountered during validation, the short report shown in the
console log of the related job details page will include a
count of non-unique legacyId values found in the CSV. Meanwhile, the longer
downloadable detailed report will also
include an output of any legacyId value found that is not unique in the CSV.
Note
If two rows are found that have the same legacyId but are not
sequentially co-located, AtoM will emit a WARNING
message during validation instead. For more information on this warning,
see:
Recommendation
Use the information contained in the
detailed report to search for the non-unique
legacyId values in your CSV.
If you are attempting to import translations, make sure that:
- translation import rows directly follow the source culture row in the CSV
- related rows share the same
legacyIdvalue, but differentculturevalues
More information on importing description translations:
Otherwise, ensure that all legacyId values in your CSV are unique before
attempting to re-validate your CSV.
WARNING - Rows with non-unique ‘legacyId’ values¶
This WARNING message is returned when AtoM detects that
two rows in the CSV contain identical legacyId values, and are not
co-located (i.e. one directly following the other in the CSV row ordering).
Note
If two rows with the same ID are sequentially co-located, AtoM will emit an ERROR message instead during validation - for more information on this error, see:
While a CSV with non-unique ID values may still import correctly with top-level
descriptions, using the same legacyId for multiple rows can cause unexpected
results if the parentId column is also used to define
hierarchical relationships, and may also
make future update imports more difficult to
properly match during import, as the legacyId is part of the initial
criteria used to identify matches for updating.
When this issue is encountered during validation, the short report shown in the
console log of the related job details page will include a
count of non-unique legacyId values found in the CSV. Meanwhile, the longer
downloadable detailed report will also
include an output of any legacyId value found that is not unique in the CSV.
Recommendation
Use the information contained in the
detailed report to search for the non-unique
legacyId values in your CSV.
If you are attempting to import translations, make sure that:
- translation import rows directly follow the source culture row in the CSV
- related rows share the same
legacyIdvalue, but differentculturevalues
More information on importing description translations:
Otherwise, ensure that all legacyId values in your CSV are unique before
attempting to re-validate your CSV.
WARNING - Rows with empty ‘legacyId’ column¶
This WARNING message is returned when AtoM finds rows that
contain no values in the legacyId column of an archival description
CSV submitted for validation.
While a legacy ID value is not required per row for a CSV to successfully import, it is used for a number of purposes, including:
- Hierarchical arrangement of rows within a description CSV, when paired with
parentIdvalues - Migration from legacy systems - AtoM can store the unique identifier from
the source system as a
legacyIdvalue during import, making audit and troubleshooting post-import easier - Import updates - AtoM will use the
legacyIdvalue from previous imports as one of the matching criteria when an update import is performed. - Importing translations of archival description metadata
To help avoid unexpected outcomes, AtoM provides a warning during validation
so you can review your CSV before importing. The short version of the validation
report shown in the console log of the related
job details page will include a count of rows with no
legacyId value. Meanwhile, the longer downloadable
detailed report will also include an output
of row numbers in the CSV that have no legacyId.
Recommendation
Use the information contained in the
detailed report to review the affected rows
missing legacyId values in your CSV.
Though the import may still succeed without any changes, we recommend ensuring
that every row in your CSV has a unique legacyId value prior to importing.
The one exception is if some rows are intended to be imported as translations
- for more information on importing description translations, see:
If your CSV contains hierarchical data (for example a fonds and its lower levels
such as series, files, items, etc), a legacyId value is required on any
row with descendants, so that child descriptions can
reference the parent’s ID in the parentId column. For more information on
using the legacyId and parentId columns to prepare hierarchical data,
see:
Even if all rows in the CSV are intended to be imported as top-level
descriptions, you may still want to include a unique legacyId per row to
better support any future imports intended to update existing descriptions, as
the original import legacyId value is one of the matching criteria used
during update imports. See:
WARNING - ‘legacyId’ column not present¶
This WARNING message is returned when AtoM is unable to
find a legacyId column in an archival description CSV submitted for
validation.
While a legacy ID value is not required per row for a CSV to successfully import, it is used for a number of purposes, including:
- Hierarchical arrangement of rows within a description CSV, when paired with
parentIdvalues - Migration from legacy systems - AtoM can store the unique identifier from
the source system as a
legacyIdvalue during import, making audit and troubleshooting post-import easier - Import updates - AtoM will use the
legacyIdvalue from previous imports as one of the matching criteria when an update import is performed. - Importing translations of archival description metadata
To help avoid unexpected outcomes, AtoM provides a warning during validation
so you can review your CSV before importing. The short version of the validation
report shown in the console log of the related
job details page will include the following message when
no legacyId column is found:
WARNING 3 - LegacyId check
--------------
'legacyId' column not present. Future CSV updates may not match these records.
Recommendation
Consider adding a legacyId column to your archival description CSV,
and adding unique ID values to every row.
Though the import may still succeed without any changes, we recommend adding a
legacyId column and ensuring that every row in your CSV has a unique
ID value prior to importing. The one exception is if some rows are intended
to be imported as translations - for more information on importing description
translations, see:
If your CSV contains hierarchical data (for example a fonds and its lower levels
such as series, files, items, etc), a legacyId value is required on any
row with descendants, so that child descriptions can
reference the parent’s ID in the parentId column. For more information on
using the legacyId and parentId columns to prepare hierarchical data,
see:
Even if all rows in the CSV are intended to be imported as top-level
descriptions, you may still want to include a unique legacyId per row to
better support any future imports intended to update existing descriptions, as
the original import legacyId value is one of the matching criteria used
during update imports. See:
Finally, if your CSV does contain a legacyId column but you are still
receiving this warning, you will likely find information in other parts of
the report that can help you troubleshoot the issue. For example, it could
be that you have unintentionally included leading or trailing whitespace in
the column name - see:
Alternatively, this could be an indication that your CSV contains non-UTF-8 characters, causing AtoM to be unable to parse the column names as expected. See:
Check the rest of the report for information that might help you identify and troubleshoot the issue.
Sample output¶
ERROR 7 - LegacyId check
--------------
Rows with non-unique 'legacyId' values: 1
Consecutive CSV rows with matching legacyId and culture will trigger errors during CSV import.
Rows with empty 'legacyId' column: 2
Future CSV updates may not match these records.
Details:
Non-unique 'legacyId' values: 666
Duplicate translation values for: legacyId: 666; culture: en
CSV row numbers missing 'legacyId': 12, 14
Parent check¶
- Test class: CsvParentValidator
This suite of tests will attempt to validate the information in your import CSV used to define hierarchical relationships.
As described in the CSV import documentation on preparing
Hierarchical relationships in an archival description import
CSV, there are two basic ways to specify which description is the
parent of another description being imported in your CSV - either through the
use of the legacyId and parentId columns (generally used for new
descriptions being imported, or from descriptions being migrated from another
access system), or by using the qubitParentSlug column to import new
child descriptions to an existing
parent description in AtoM.
The tests run by the Parent check will attempt to identify common issues found
in these fields that could cause unexpected outcomes or errors during import. It
will also output general information such as the number of rows with
parentId values, and the number of rows with qubitParentSlug values.
Jump to:
- ERROR - no matching legacyID
- WARNING - rows with both ‘parentId’ and ‘qubitParentSlug’ populated
- WARNING - ‘parentId’ and ‘qubitParentSlug’ columns not present
- Sample output
ERROR - no matching legacyID¶
This ERROR is provided when the CSV includes a
parentId value that references a legacyId that either does not appear
in the CSV, or else appears in the CSV in a row below the parentId with the
reference.
A parentId is typically used in an archival description CSV to
import new descriptions, where both the target parent record and any
descendants appear in the same CSV. parentId values should be populated
with the legacyId value of the target parent description, thereby creating
a relationship that AtoM can use to properly establish the descriptive
hierarchy on import.
The AtoM CSV import progresses by parsing the metadata in a CSV
sequentially, row by row. If AtoM encounters a row with a parentId value
before the related parent description with the matching legacyId has been
processed (i.e. the child row appears before its parent in the CSV), the import
will throw an error and abort mid-process. If the related legacyId appears in
a row after the parentId that refers to it, then it has the same effect as
including a parentId value that doesn’t exist as a legacyId anywhere in
the system.
For further general reading on preparing a CSV with parent ID values, see:
During validation, the same process occurs - AtoM will attempt to check that
all parentId values found in the CSV reference a matching legacyId
that appears in a row preceding the parentId under evaluation. If no match
is found, AtoM will emit this error.
Tip
When using the command-line import, it’s
possible to use the --source-name option to specify a source name for the
import. When this is used, the validation task will also check AtoM’s
keymap database table for matching legacyId values from prior imports
that share the same source name.
For more information, see:
The short version of the report shown in the console log on the related
job details page will include a count of rows for which
no matching legacyId could be found. Additionally, the downloadable
detailed report will also include row numbers
to help you find the problematic values.
Recommendation
Use the information provided in the report to identify the problem rows.
Ensure that the parentId value provided is entered correctly, and:
- the ID value exactly matches the
legacyIdvalue of the target parent description - the CSV row containing the target parent description is in the same file
- the CSV row containing the target parent description appears before the child description row
If you’re using a spreadsheet application to prepare and review your data, be
aware that some settings may cause leading zeroes on an ID value (e.g. 0001)
to be stripped before saving. If you are having trouble finding or fixing the
issue in a spreadsheet application, consider opening the file in a
text editor - this should make it easier to manually add leading zeroes to
a legacy or parent ID value.
Warning
While viewing a CSV in a text editor can be helpful for troubleshooting, be extremely cautious about editing the CSV this way! If you accidentally delete a separator or other formatting character, you can end up introducing row-length errors in an otherwise well-formed CSV!
We recommend saving a separate version of your CSV (i.e. “Save As”) if you are intending to edit your CSV this way, just in case you accidentally alter a separator or other character critical to the formatting of the CSV file.
See also
For general guidance on preparing an archival description CSV with hierarchical data, see:
WARNING - rows with both ‘parentId’ and ‘qubitParentSlug’ populated¶
- Default behavior: Use
qubitParentSlugand ignoreparentIdvalue
This WARNING is provided when a single row in the import
CSV has values that appear in both the parentId and qubitParentSlug
columns.
Typically, the parentId column is used when importing new hierarchies,
where both the target parent record and any child descriptions are
both included as new descriptions in the CSV. Meanwhile, the qubitParentSlug
column is used to provide the slug of a parent description that already
exists in AtoM - the related CSV row will then import as a child record
of the existing parent.
If the validation task encounters a row that contains values in both columns, it will emit a WARNING, and output a count of rows where both fields are populated. Additionally, the detailed report will also include row numbers to help you find the affected rows.
AtoM’s default fallback behavior when this is found during an import is to use
the provided qubitParentSlug value, and ignore the parentId value.
However, since there is no intentional reason to include values for both
columns, this typically indicates user error during metadata preparation, and
you should review your CSV before importing to ensure it will import as
desired.
Recommendation
Use the information found in the detailed report to identify affected rows. Ensure that these rows have only one of the two columns populated before proceeding.
See also
For general guidance on preparing an archival description CSV with hierarchical data, see:
If you decide to use the parentId value, be sure to review the information
provided in the validation test described above, to avoid introducing the
related error:
WARNING - ‘parentId’ and ‘qubitParentSlug’ columns not present¶
- Default behavior: Import all rows as top-level descriptions
This WARNING is provided when the
archival description CSV file being validated does not include either
the parentId or the qubitParentSlug column.
For an archival description CSV to import successfully, these columns are not
necessary - provided that all rows are top-level descriptions. However, if
you intended for your descriptions to have a hierarchical relationship (for
example, you are attempting to import a Fonds with descendant series, files,
and items, etc.), then you must use either the legacyId and parentId
columns, or else the qubitParentSlug column to tell AtoM how each row
should be related to other descriptions. For general guidance on preparing an
archival description CSV with hierarchical data, see:
AtoM’s default import behavior when no information is included in either column for a given row is to import the record as a top-level description. However, to help the user ensure this is the desired outcome, the Parent Check test will emit a WARNING if neither column is found in the CSV, and the resulting report will include the following message:
WARNING 3 - Parent check
------------
'parentId' and 'qubitParentSlug' columns not present. CSV contents will be imported as top level records.
Recommendation
If you are intending to import all rows as top-level descriptions, then no action needs to be taken, and you can ignore the warning message.
If however your intent was to import hierarchically structured descriptive metadata (e.g. an archival unit), review the AtoM documentation for instructions on how to properly prepare your CSV, and make revisions as necessary before re-validating. See:
See also
If you decide to use the parentId column to implement hierarchical
relationships, be sure to review the information provided in the validation
test described above, to avoid introducing the related error:
Finally, if your CSV does contain these columns but you are still getting this message, review the results of the other validation tests for further information. It could be that a minor typo or case variation in your column header name has prevented AtoM from locating the column(s) - see:
Additionally, in some cases this error may be caused by improper character encoding. If the encoding used in your CSV is not UTF-8 (or there are non-UTF-8 characters in an otherwise well-formed CSV), then column header names in your CSV may not be rendered as expected, triggering the validation warning. For further information and troubleshooting recommendations, see:
Sample output¶
ERROR 8 - Parent check
------------
Rows with parentId populated: 11
Rows with qubitParentSlug populated: 2
Rows with both 'parentId' and 'qubitParentSlug' populated: 1
Column 'qubitParentSlug' will override 'parentId' if both are populated.
Verifying parentId values against legacyId values in this file.
Number of parentId values found for which there is no matching legacyID (will import as top level records): 1
Verifying qubitParentSlug values against object slugs in the AtoM database.
Number of qubitParentSlug values found for which there is no matching slug (will import as top level records): 2
Details:
CSV row numbers where issues were found: 8, 11, 16
Event value count test¶
- Test class: CsvEventValuesValidator
This test will evaluate the metadata entered into event and actor related rows in an archival description CSV submitted for validation. The following columns, often used for entering information about creators and related dates of creation, are included in the analysis:
- eventActors
- eventActorHistories
- eventTypes
- eventDates
- eventStartDates
- eventEndDates
- eventDescriptions (RAD template only)
- eventPlaces (RAD template only)
For general information on how these fields are intended to be used in a description CSV import, see:
If multiple actors/events exist for an archival description row, the values in
these fields can be pipe-separated (e.g. using the | pipe separator
between values).

To ensure that related metadata remains associated with the intended event and actor on import, this test will compare the number of pipe-separated values included per row for any of the columns that are populated. If there is a mismatch, the resulting validation report will include a WARNING so you can review your CSV and ensure it is properly structured to import as intended.
Jump to:
WARNING - Event value mismatches found¶
- Default behavior: When no
eventTypeis provided for a giveneventActor, use “Creation” as the event type
This WARNING is provided when some or all of the event-related CSV columns are found in the CSV, but the number of pipe-separated values does not match in a given row.
In AtoM’s data model, an archival description is a description of a record, understood as the documentary evidence created by an action - or event. It is events that link actors (represented in AtoM by an authority record) to archival descriptions - see Entity types for more information.
AtoM shares a single internal data model across its various standards-based data entry templates - so while creator names/histories and dates of creation are separate fields in the ISAD(G) template, in the data model both actors and dates are associated together via an events table, much as they are represented in the Canadian RAD description standard.
AtoM’s description CSV import can support the import of more than one event
per row, by using pipe separators (|) between data elements. Where multiple
creator (or other event type actors, e.g. contributors, accumulators, etc)
names and histories are included in an import, the pipe-separated
eventActors and eventActorHistories elements in a row are matched 1:1
in the order they appear in the CSV. For example, if the eventActors
column contains two names in a row (name 1|name 2), then the
eventActorHistories column should also include history 1|history 2
to match on import. If there is no history for the first actor, you can
include NULL, and AtoM will ignore the input during the import - e.g.
name 1|name 2 should be matched with NULL|history 2 to include only a
history for name 2. If you do not include this NULL value for first actor
history, then history 2 would end up importing as the history of name 1.
This same NULL approach can be used for any matched date values where
multiple actor names are included for import - eventDates,
eventStartDates, eventEndDates (and the RAD-specific eventPlaces
and eventDescriptions) can all include NULL if you wish to
leave these blank post-import when associating multiple actors with an event.
An example, using the RAD template:

For further information on preparing actor and event-related metadata in an archival description CSV for import, see:
During the validation process, AtoM will check for the presence of data in any of the event-related columns per row. If at least one field is populated, the test will then compare the event columns to ensure that there is no mismatch between the number of pipe-separated elements in each column per row.
Any event column with no data in a particular row is ignored during validation, as the test will assume this is an intentional choice not to import data for this field. This avoids the test returning warnings for lower level records in an archival unit that have, for example dates of creation but no creator name listed.
However, if piped values are found and there is a mismatch in the number of pipe-separated values across the event fields for a particular row, the test will emit a WARNING message in the resulting report.
Note that due to the underlying data model, AtoM will expect all
event-related columns to be equally aligned when piped values are present in one
or more column. However, this may not align with the data entry experiences of
using some templates. For example, the ISAD(G) standard
separates creator name (ISAD 3.2.1) from dates of creation (ISAD 3.1.3). A user
could conceivably enter two creators, and only one date of creation. On export
however, AtoM would populate the resulting CSV with 3 piped values - one for the
dates with NULL values for the actor columns, and the other two will
NULL date values and populated actor values, like so:

To avoid unnecessary import errors, AtoM does have some import fallback behavior
in place. When an actor is referenced in one of the event columns that does not
have an associated eventType value, AtoM will treat the actor on import as a
creator. This way, it is possible to create CSVs that have only one
date of creation and multiple actors without piping all date-related imputs. So
long as the actor values are properly piped, the import will succeed, even if
the validation warning is returned.
Recommendation
The explanation given above is why AtoM emits a WARNING as opposed to an ERROR when there is a mismatch in piped values. Ideally, all event-related columns will share the same number of pipe-separated values per row. However, an import with multiple creators but only one creation date may still succeed.
Use the information provided in the report to review any rows triggering the
warning. If you are including multiple actors with eventActorHistories,
make sure that the pipes in the eventActors column match, and that the
order of piped values matches across columns. Similarly, when multiple dates
are being imported, ensure that the number of piped values and the order of the
piped metadata elements matches across all relevant columns:
eventTypeeventDateseventStartDateseventEndDates
If you are using the RAD template, also consider piped
values in eventDescriptions and eventPlaces.
Remember that the validation test expects the same number of pipes across all event-related columns - both actor and date-related ones. Depending on your expected outcome post-import, no changes may be needed in your CSV. If you are uncertain, we recommend creating a test CSV with only a few rows and importing to see the results in AtoM’s user interface. Alternatively, you can make a test description in AtoM’s user interface and then export it to see how AtoM will normally structure the data in the event columns.
If you would like to fix all validation warnings resulting from this check,
ensure that every row has an equal amount of piped values in the event-related
columns, and that the alignment between piped values matches across the column
(for example, creator 2’s name and history are both the second piped value, so
they will remain associated during import). You can enter NULL to leave a
piped value blank while still properly piping all column values.
With cases where there are more actors than dates - for example, two creators - but one (shared) date of creation - there are several approaches you can take.
The first option is to use NULL values to ensure that all event columns
are piped the same, but only the first actor is associated with the dates of
creation. This will avoid the warning and should display properly in AtoM’s
various display standard templates. Internally in the database, only
the first actor would actually have dates associated with their creation
event, but this may not affect your intended use or the display of the
metadata in AtoM’s view pages, and is the easiest way to
resolve the warning message from this validation check.
The second option is to properly associate each creation event with the related dates and an actor in the database. In your CSV, you would enter the same dates for every piped actor. However, depending on the display standard being used in AtoM, this might lead to the date of creation being shown twice or more in the related view page for the description.
The third option is to simply ignore the warning. However, you may still want
to review your data to ensure that your actor metadata in the event columns
are properly pipe-separated, so that any history data associated with an actor
imports to the correct authority record. AtoM’s default fallback
behavior of assuming any actor name in the event columns without an associated
eventType value will be treated as a creator means that the import
should proceed without errors. Internally in the database, only the first
actor would actually have dates associated with their creation event.
Finally, remember that in archival description hierarchies, AtoM will automatically inherit the creator name from ancestor descriptions if no parent is added directly. This means that at lower levels of description in an archival unit, if the creator is the same, then you only need to add your dates of creation - lower level description rows in your CSV can leave the actor-related event columns empty.
If you’ve previously linked the same creator at multiple levels in an archival unit, AtoM does have a command-line task that can remove unneeded relations. This can help improve performance and reduce noise in related user interface display pages (for example, the related descriptions shown on an authority record view page). For more information, see:
Sample output¶
WARNING 4 - Event Value Count Test
----------------------
Checking columns: eventTypes,eventDates,eventStartDates,eventEndDates,eventActors,eventActorHistories
Event value mismatches found: 1
Details:
CSV row numbers where issues were found: 11
Repository check¶
- Test class: CsvRepoValidator
This test will emit a WARNING if an archival description CSV submitted for validation will create a new stub archival institution record on import.
AtoM’s description CSV import templates contain a repository column
that can be used to link a description to an archival institution as the
holding repository. If this column is populated, on import AtoM will use the
value to search for an exact match in the authorized form of name field
(ISDIAH 5.1.2) of any existing archival institution
records. If an exact match is found, AtoM will link the description to
that repository record. When no match is found, AtoM’s default import
behavior is to create a new stub repository record with the authorized form of
name, as well as the link between the description and this new stub repository.
Because the import logic depends on an exact match on the repository name field, any typos in the import metadata can lead to the accidental creation of duplicate repository records. To help avoid user error leading to unwanted duplicate records on import, AtoM will emit a warning whenever a CSV submitted for validation will lead to the creation of a new archival institution.
Jump to:
See also
WARNING - New repository records will be created¶
- Default behavior:: Create new stub repository record when encountering an
unrecognized name in the
repositorycolumn.
This WARNING is provided when one or more of the values
in the repository column of your CSV will cause a new stub
archival institution record to be created on import. It is intended as
an informational element during validation, to help users avoid accidentally
creating duplicate repository records due to typos or minor spelling
variations.
The short version of the report shown in the console log of the related
job details page will include a count of new repository
records that will be created if you proceed with the import, as well as an
output of the relevant repository column metadata values that have
triggered the warning. Additionally, the downloadable
detailed report will also include the CSV
row numbers where the values appear.
Recommendation
Use the details included in the validation report to review the
archival institution names entered into the repository column of
your CSV.
If you are intending to create one or more new repository records via your
import, then it’s possible that no action needs to be taken. If you have data
in more than one row of the CSV’s repository column it is still recommended
to review the report’s output and ensure that a typo or minor spelling variation
will not lead to more repository records being created than expected.
Otherwise, compare any repository names with those found in your AtoM installation, and correct any variations in spelling found to ensure your descriptions will link to the existing repostiory record before re-validating the CSV to confirm the issue is resolved.
Sample output¶
WARNING 5 - Repository Check
----------------
Number of NEW repository records that will be created by this CSV: 2
New repository records will be created for: Example Repository,Example Repository2
Details:
CSV row numbers where issues were found: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 16
Digital object path check¶
- Test class: CsvDigitalObjectPathValidator
This suite of tests will attempt to validate the filepaths pointing to
digital object files that are included in an
archival description CSV in the digitalObjectPath column.
This column can be used to upload locally stored digital objects and attach them to target descriptions during CSV import.
Paths in this column should point to local digital objects placed in AtoM’s
root installation directory, which are intended for upload as part of the
CSV import. When the CSV is processed, a new description will be created
for a given row, and the related digital object referenced in the
digitalObjectPath column for that row will be uploaded and attached to the
description.
Note
AtoM also has a second digital object column in the description CSV
templates, called digitalObjectURI. This column can be used to link to
externally hosted, publicly available digital objects, such as those
available at a specific URL on the web.
You can use a mixture of the digitalObjectPath and digitalObjectURI
columns throughout your CSV (linking some information object rows to
locally uploaded digital objects, and others to web-based resources), but
you cannot use both columns in the same row. If AtoM encounters a CSV row
where both the digitalObjectPath and digitalObjectURI columns are
populated, it will favor the digitalObjectURI value, and ignore the
digitalObjectPath value.
For more information on using the digital object import columns when preparing your archival description CSV, see:
Jump to
- ERROR - Digital objects referenced by CSV not found in folder
- ERROR - Unable to open digital object folder path
- WARNING - Duplicated digital object paths found in CSV
- WARNING - ‘digitalObjectPath’ will be overridden
- WARNING - Digital objects in folder not referenced by CSV
- Sample output
See also
ERROR - Digital objects referenced by CSV not found in folder¶
This ERROR message is returned when one or more of the
file paths included in the digitalObjectPath column cannot be found or
accessed by the validation task.
The short version of the report shown in the console log of the related job details page will include a count of how many digital objects referenced in the CSV could not be accessed. Additionally, the downloadable detailed report will include an output of the filepath values that could not be found, as shown in the example below:
ERROR 9 - Digital Object Path Test
------------------------
Column 'digitalObjectPath' found.
Digital object folder location not specified.
Digital objects referenced by CSV not found in folder: 3
Details:
Unable to locate digital object: /usr/share/nginx/atom/import-objects/banjobun.fake
Unable to locate digital object: /usr/share/nginx/atom/bun-butt.jpg
Unable to locate digital object: bunnyBerry.jpg
Recommendation
Use the information included in the validation report to locate the problem file paths in the CSV.
Begin by reviewing the contents of your digital object upload directory, and
comparing this against the metadata in the digitalObjectPath of your CSV -
confirm that all files referenced in the CSV column exist in the target
directory, and correct any variations in spelling or case, typos, etc.
When the digitalObjectPath column is used in a CSV intended to be uploaded
via the user interface, you must specify the absolute path to the
file in the CSV. Files should be placed somewhere in AtoM’s root installation
directory - we recommend creating a temporary directory in the root directory
called something like “imports” or “objects”, and placing your upload files
there.
Note
AtoM already has directories named images and uploads in use - do
not use these as your temporary upload directory name.
In the CSV, you can then use the absolute path to refer to the target digital object per row.
For example:
- If you have followed the recommended
installation instructions, then the absolute
path to your root installation directory is typically
/usr/share/nginx/atom - If you create a temporary directory to store your digital objects called
import-objectsin the root installation directory, and have a digital object namedimage01.jpg, then the absolute path to include in your CSV for that object would be:/usr/share/nginx/atom/import-objects/image01.jpg
Be sure to check for any typos and/or variations in capitalization in your file paths. Remember that AtoM maintains a 1:1 relationship between a digital object and an archival description - you can only attach one digital object per description. For more general information on managing digital objects, see:
This means that attempts to use a pipe separator (|) to add more than
one digital object per row will result in validation errors. You can always
create additional lower levels to attach digital objects if necessary - all
levels of description are in a user-editable taxonomy that an
administrator can customize as needed. AtoM includes Part as an
example sub-item level of description, but others could be created and used
as well.
If you are still receiving validation errors, you may need to double-check the
filesystem permissions in your installation, to ensure that the location can
be accessed. AtoM expects the www-data user to be the owner of all files
and directories below the root installation directory. If you have followed
our recommended installation instructions, you
can reset the filesystem permissions correctly with the following command:
sudo chown -R www-data:www-data /usr/share/nginx/atom
See also
Once an upload has successfully completed, a copy of the original file(s) will
be stored in AtoM’s uploads directory along with any generated
derivatives. The temporary upload directory (e.g. the import-objects
directory and its contents in the example above) can be deleted once you have
confirmed that the import has completed successfully and your objects are
attached to the correct descriptions.
Tip
When performing validation via the
command-line task, there is a
--path-to-digital-objects option that can be used to set the path to
your directory where the objects are stored. When this option is used, you
do not need to specify the full absolute path per row in the import CSV -
in fact, doing so can be the cause of error messages!
Instead, include the path to the directory once via the option, and in the
CSV just specify the target digital object’s filename (e.g.
image01.jpg, etc) per row. If you specify the full path in both
locations (the CSV and the --path-to-digital-objects CLI option), AtoM
may combine the inputs when looking for the target file, leading to
directories that do not exist.
For more information, see:
If this error message is being triggered when using the command-line task
with the --path-to-digital-objects option, it means that either the
path provided is incorrect, the filename of the digital object in the CSV
is incorrect, or else the filesystem permissions are incorrectly set. Apply
the same review and corrective suggestions recommended above before
attempting to re-validate your CSV.
ERROR - Unable to open digital object folder path¶
This ERROR message is only returned when using
the command-line to run your validation, with the --digital-object-path
option. For more information on command-line CSV validation, see:
The --path-to-digital-objects option can be used during command-line
validation to include a path to where your import digital objects are located
on the local filesystem. When using this option, you do not need to specify
the absolute path to each object in your CSV - instead, the task option will
pass the parent directory path to the task, and the CSV need only contain the
filename of each referenced object found in the target directory.
This error message will be returned validation if the path provided cannot be found or accessed by AtoM, as in the example shown below:
ERROR 10 - Digital Object Path Test
------------------------
Column 'digitalObjectPath' found.
Unable to open digital object folder path: /usr/share/nginx/atom/some-nonexistent-folder
Recommendation
Use the path provided in the ERROR message to compare it against the actual location of your digital object directory. Correct any typos, spelling or case variations, etc.
In general, we recommend not using spaces or special characters in your upload directory name. If you make changes to the temporary digital objects upload directory on your server, remember to update the CSV correspondingly before attempting to re-validate.
Review the documentation for the
command-line validation task, which includes
an example when using the --path-to-digital-objects option - ensure you have
entered all command options and parameters as described.
When using the --path-to-digital-objects option with the command-line
validation task, do not include the absolute path to your digital object(s)
in your CSV’s digitalObjectPath column. The purpose of the
--path-to-digital-objects option is to provide AtoM with a single shared
location for all files intede to be uploaded as digital objects. As such,
the CSV should only contain the filename of the target digital object per row.
If you specify in both locations (i.e. using the absolute path the relevant
CSV rows and the --path-to-digital-objects CLI option), AtoM may combine
the inputs when looking for the target file, leading to directories that do
not exist.
If you are still receiving validation errors, you may need to double-check the
filesystem permissions in your installation, to ensure that the path location
can be accessed. AtoM expects the www-data user to be the owner of all
files and directories below the root installation directory. If you have
followed our recommended
installation instructions, you can reset the
filesystem permissions correctly with the following command:
sudo chown -R www-data:www-data /usr/share/nginx/atom
See also
WARNING - Duplicated digital object paths found in CSV¶
This WARNING message is returned when one or more of the
rows in the digitalObjectPath column reference the same
digital object. AtoM will compare the file path values included in the
column, and if two or more rows contain the exact same path, the warning
will be returned in the report.
There are two counts included in the report related to this message. In the
short version of the report shown in the console log of the related
job details page, AtoM will include a count of how many
unique digital object paths appear more than once. Additionally, the
downloadable detailed report will include
an output of the duplicated object path, along with a count of how many times
that particular path appears in the digitalObjectPath column.
For example:
WARNING 6 - Digital Object Path Test
------------------------
Column 'digitalObjectPath' found.
Digital object folder location not specified.
Number of duplicated digital object paths found in CSV: 2
Details:
Number of duplicates for path '/usr/share/nginx/atom/import-objects/bunny.jpg': 3
Number of duplicates for path '/usr/share/nginx/atom/import-objects/puppy.png': 2
In this example, the bunny.jpg digital object has been referenced in this
CSV in three different rows, while the puppy.png file has been
referenced in two different rows of the digitalObjectPath column.
Recommendation
Use the information contained in the validation report to review the metadata
included in the digitalObjectPath column of your CSV, and make any changes
as needed.
Note that this is a WARNING message, not an error - meaning you may choose to proceed without making changes if you intend to attach the same digital object to multiple descriptions. If you do, here are some details on the results when two descriptions are created with the same digital object:
- Only one master digital object will be created and stored on the
filesystem- both descriptions will reference the same digital object stored
in the
uploadsdirectory. - Each archival description will have its own reference display copy and thumbnail generated. If you delete the derivatives on one description, it will not impact the derivatives associated with the second description
- Deleting the digital object entirely on only one description will not remove
it from the
uploadsdirectory - the master digital object will not be deleted from the filesystem until it has been disassociated from all linked descriptions
Otherwise, make any corrections needed to the file paths included in the
digitalObjectPath column of your CSV before attempting to re-validate. To
fully resolve this validation warning, ensure that each filepath added to the
column is unique. For information on how to prepare the digital object
columns in an archival description CSV, see:
For more general information on managing digital objects, see:
WARNING - ‘digitalObjectPath’ will be overridden¶
- Default behavior: Use
digtialObjectURIvalue when both this column and thedigitalObjectPathcolumn are populated in the same row
This WARNING message is returned when one or more rows in
the archival description CSV contain metadata in both the
digitalObjectPath and digitalObjectURI columns.
In AtoM, a 1:1 relationship is maintained between archival descriptions and digital objects - meaning that for every archival description, you can only attach one digital object. For more general infomation on managing digital objects in AtoM, see:
To avoid throwing an error and halting the import, AtoM has a default behavior
when one CSV row contains data in both digital object columns - it will use
the URI provided in the digitalObjectURI column, and ignore the local
digital object referenced in the digitalObjectPath column. Since this may
not be your intended outcome (after all, there is no reason to intentionally
include values in both columns for a single row), AtoM issues the warning
during validation so you can review any affected rows.
The warning will include a count of rows where both columns have values, as in the example below:
WARNING 7 - Digital Object Path Test
------------------------
Column 'digitalObjectPath' found.
Digital object folder location not specified.
'digitalObjectPath' will be overridden by 'digitalObjectURI' if both are populated.
'digitalObjectPath' values that will be overridden by 'digitalObjectURI': 1
Recommendation
Use the information contained in the validation report to review the metadata included in the digital object columns of your CSV, and make any changes as needed.
You can use a mixture of the digitalObjectPath and digitalObjectURI
columns throughout your CSV (linking some archival description rows to
locally uploaded digital objects, and others to web-based resources), but you
cannot use both columns in the same row. If AtoM encounters a CSV row where
both the digitalObjectPath and digitalObjectURI columns are populated,
the default import behavior will favor the digitalObjectURI value, and
ignore the digitalObjectPath value.
To fully resolve this warning, ensure that each row of your CSV contains only
one digital object reference - that is, either the digitalObjectPath
or the digitalObjectURI column may be populated per row, but not both.
Even if the default import behavior (using the URI value) is your intended
outcome, we still recommend deleting any unnecessary values from the
digitalObjectPath column whenever possible.
WARNING - Digital objects in folder not referenced by CSV¶
- Default behavior: Ignore unreferenced digital object files and proceed with import
This WARNING message is only returned when using
the command-line to run your validation, with the --digital-object-path
option. For more information on command-line CSV validation, see:
The --path-to-digital-objects option can be used during command-line
validation to include a path to where your import digital objects are located
on the local filesystem. When using this option, you do not need to specify the
absolute path to each object in your CSV - instead, the task option will
pass the path to the task, and the CSV need only contain the filename of each
referenced object found in the target directory.
This warning message will display following validation if AtoM finds one or
more digital objects in the target directory that are not referenced in the
CSV at all. The default short version of the report will simply include a
count of digital objects found in the target directory that are not referenced
in the CSV. However, when validation is run using the --verbose option
(the command-line equivalent of the downloadable
detailed report provided in the user
interface), the output will also include a list of filenames not referenced
in the CSV, as in the example below:
WARNING 8 - Digital Object Path Test
------------------------
Column 'digitalObjectPath' found.
Digital objects in folder not referenced by CSV: 8
Details:
Unreferenced digital object: bun-butt.jpg
Unreferenced digital object: attack-rabbit.jpg
Unreferenced digital object: bunny-tongue.jpg
Unreferenced digital object: bunny-petting-guide.jpg
Unreferenced digital object: bunnyBerry.jpg
Unreferenced digital object: bubblegum.jpg
Unreferenced digital object: fox-bunny.jpg
Unreferenced digital object: banjo-bunny.jpg
In this case, since these objects are not referenced in the import CSV file, AtoM will ignore them during the import process and they will not be uploaded. The WARNING returned attempts to ensure that users do not accidentally miss intended imports due to typos, case variations, or other minor details.
Recommendation
Use the --verbose output of the task to review the list of files that will
not be uploaded if you proceed with an import. Compare this as needed to the
metadata found in your import CSV.
If you did not intend to upload these digital objects in association with this particular CSV import, then no action needs to be taken - AtoM’s default behavior on import will be to ignore these files.
Otherwise, make corrections and additions as needed in your CSV until you are ready to re-validate the file. Be sure that the filenames match exactly, including case. In general, we recommend you avoid using spaces and special characters in your file and directory names.
Sample output¶
ERROR 11 - Digital Object Path Test
------------------------
Column 'digitalObjectPath' found.
Digital object folder location not specified.
'digitalObjectPath' will be overridden by 'digitalObjectURI' if both are populated.
'digitalObjectPath' values that will be overridden by 'digitalObjectURI': 2
Number of duplicated digital object paths found in CSV: 1
Digital objects referenced by CSV not found in folder: 3
Details:
Number of duplicates for path '/usr/share/nginx/atom/import-objects/bunny-tongue.jpg': 3
Unable to locate digital object: /usr/share/nginx/atom/import-objects/banjobun.fake
Unable to locate digital object: /usr/share/nginx/atom/bun-butt.jpg
Unable to locate digital object: bunnyBerry.jpg
Digital object URI check¶
- Test class: CsvDigitalObjectUriValidator
This test attempts to evaluate any URLs added to the digitalObjectURI
column of an archival description CSV submitted for validation.
This column can be used to upload and link externally hosted, publicly available digital objects, such as those available at a specific URL on the web. AtoM requires 3 criteria to be met for uploads via URI to succeed:
- The URI must begin with
httporhttps- FTP or SFTP paths, as well as paths to local networked drives, etc. will not succeed - The digital object must be available on the public web - no passwords, VPNs, or other barriers to access should be in place, or else AtoM will not be able to resolve the URI and fetch the digital object.
- The URI must end in the file extension of the digital object - e.g.
.png,.jpg,.mp4,.pdf, etc. Linking to a web page that contains a digital object but also has other information - for example, a YouTube link - will fail, since AtoM will be unable to tell what page element it is supposed to be fetching.
Tip
To find a URI that leads directly to the digital object and includes the file extension, it is often possible to right-click on a digital object in your web browser and select “open in new tab.”
During validation, this test will attempt to verify the second criteria - that
all metadata entered into the digitalObjectURI column begins with either
http or https. If an invalid URI is found, the test will issue
an ERROR.
Note
AtoM also has a second digital object column in the description CSV
templates, called digitalObjectPath. This column can be used to link to
local digital object files that have been placed somewhere in below the
root AtoM installation directory for upload during the import of
description metadata.
You can use a mixture of the digitalObjectPath and digitalObjectURI
columns throughout your CSV (linking some information object rows to
locally uploaded digital objects, and others to web-based resources), but
you cannot use both columns in the same row. If AtoM encounters a CSV row
where both the digitalObjectPath and digitalObjectURI columns are
populated, it will favor the digitalObjectURI value, and ignore the
digitalObjectPath value.
For more information on using the digital object import columns when preparing your archival description CSV, see:
Jump to:
- ERROR - Invalid digitalObjectURI values detected
- WARNING - Repeating Digital object URIs found
- Sample output
See also
ERROR - Invalid digitalObjectURI values detected¶
This ERROR is returned when a link added to the
digitalObjectURI column of an archival description CSV does not
begin with either http or https.
AtoM expects all URIs to be publicly available on the web, and that the link
provided begin with either http or https - local FTP or SFTP links
will not work, nor will local networked drives, etc.
Recommendation
Use the information contained in the validation report to review the links
added in the digitalObjectURI column of your CSV.
Remember the following criteria for uploading digital objects via URI:
- The URI must begin with
httporhttps- FTP or SFTP paths, as well as paths to local networked drives, etc. will not succeed - The digital object must be available on the public web - no passwords, VPNs, or other barriers to access should be in place, or else AtoM will not be able to resolve the URI and fetch the digital object.
- The URI must end in the file extension of the digital object - e.g.
.png,.jpg,.mp4,.pdf, etc. Linking to a web page that contains a digital object but also has other information - for example, a YouTube link - will fail, since AtoM will be unable to tell what page element it is supposed to be fetching.
The error refers to this first criteria, so be sure to verify that your
values are well-formed in the digitalObjectURI column. It’s also wise to
test your links in a web browser first, to ensure they resolve correctly.
For more information on using the digital object import columns when preparing your archival description CSV, see:
For general information on uploading and managing digital objects in AtoM, see:
WARNING - Repeating Digital object URIs found¶
This WARNING will be emitted by the test if the same
URI appears in the digitalObjectURI column more than once in your CSV. It
is intended to help you avoid accidentally duplicating digital objects in your
CSV import. The short version of the report included in the console log of the
related job details page will only mention that repeated
digital object URIs have been found in the CSV. However, the
downloadable detailed report will also
include an output of any URIs that have been duplicated.
Below is an example output of the warning:
WARNING 9 - Digital Object URI Test
-----------------------
Column 'digitalObjectURI' found.
Repeating Digital object URIs found in CSV.
Details:
Number of duplicates for URI 'https://www.artefactual.com/wp-content/uploads/2016/04/cat.jpg': 2
Recommendation
Use the information provided in the
detailed report to search your CSV and
review the metadata in the digitalObjectURI column.
If you intend to import the same digital object via URI to more than one archival description, then no action needs to be taken. Otherwise, correct the CSV as needed before attempting to re-validate.
Sample output¶
ERROR 12 - Digital Object URI Test
-----------------------
Column 'digitalObjectURI' found.
Invalid digitalObjectURI values detected: 2
Details:
Invalid URI: ftp://some-path/bunny.png
Invalid URI: www.example.com/kitten.jpg
Language check (descriptions)¶
- Test class: CsvLanguageValidator
This test class will attempt to validate the values used the language column
of archival description and archival institution CSV files.
Validation is performed by comparing the values against an internally maintained
list of accepted language codes. If mismatches are found, AtoM will return an
ERROR during the validation process.
Jump to:
ERROR - Invalid language values¶
AtoM expects ISO 639-1 language codes to be used in the language column -
these are typically two-letter codes, though in a few cases AtoM can support the
addition of ISO 3116 country codes to specify locale, such as pt_BR
(Portuguese Brazilian), fr_CH (Swiss French), etc.
This column can accept multiple pipe-separated values per row - for example, to
list English, Spanish, and French as the languages of a record, you can enter
en|es|fr in the appropriate CSV row.
AtoM maintains an internal list of these language codes, and this validation test
will attempt to compare any values it finds in the language column
to those maintained internally. If a mismatch is found, AtoM will emit an
ERROR.
The short report shown in the console log of the related
job details page will include a count of rows with invalid
language values, as well as a list of the invalid values found during the
validation test. Additionally, the details included in the downloadable
verbose report will also include a list of
CSV row numbers where issues have been found.
Recommendation
Use the values provided in the the detailed report to search your CSV and identify the problem language values. Ensure that only supported ISO 639-1 language values are used - replace any problem values with the appropriate language code before re-validating.
For a full list of supported languages and related codes in AtoM, see:
Sample output¶
ERROR 13 - Language Check
--------------
Rows with invalid language values: 1
Invalid language values: English
Details:
CSV row numbers where issues were found: 7
Script of description check¶
- Test class: CsvScriptValidator
This test will attempt to validate the values used in the scriptOfDescription
column of an archival description CSV against an internally maintained
list of accepted script codes. If mismatches are found, AtoM will return an
ERROR during the validation process.
Jump to:
See also
ERROR - Invalid scriptOfDescription values¶
This ERROR is returned when one or more values in the
scriptOfDescription column do not match AtoM’s internal list of accepted
script codes.
AtoM expects ISO 15924 script codes to be used in the scriptOfDescription
column - these are typically four-letter codes where the first letter is
capitalized. See Unicode for a full list of ISO 15924 script codes. This
column can accept multiple pipe-separated values per row - for example, to
list Latin and Coptic as the scripts of a record, you can enter Latn|Copt
in the appropriate CSV row.
AtoM maintains an internal list of these codes, and this validation test will
attempt to compare any values it finds in the scriptOfDescription column
to those maintained internally. If a mismatch is found, AtoM will emit an
ERROR.
The short report shown in the console log of the related
job details page will include a count of rows with
invalid scriptOfDescription values, as well as a list of the invalid
values found during the validation test. Additionally, the downloadable
detailed report will also include a list of
CSV row numbers where issues have been found.
Recommendation
Use the values provided in the report to search your CSV and identify the
problem scriptOfDescription values. Ensure that only supported ISO
15924 script code values are used - replace any problem values with the
appropriate script code before re-validating. See Unicode for a full list
of ISO 15924 script codes.
Sample output¶
ERROR 14 - Script of Description Check
---------------------------
Rows with invalid scriptOfDescription values: 2
Invalid scriptOfDescription values: Latin and Coptic, Weird runes
Details:
CSV row numbers where issues were found: 4, 5
CSV validation tests - archival institutions¶
This section describes supplementary tests that are run when an archival institution import CSV is submitted for validation, in addition to the general validation tests run for all entity types.
Jump to:
Language check (repositories)¶
- Test class: CsvLanguageValidator
This test class will attempt to validate the values used the language column
of archival description and archival institution CSV files.
Validation is performed by comparing the values against an internally maintained
list of accepted language codes. If mismatches are found, AtoM will return an
ERROR during the validation process.
Jump to:
ERROR - Invalid language values¶
AtoM expects ISO 639-1 language codes to be used in the language column -
these are typically two-letter codes, though in a few cases AtoM can support the
addition of ISO 3116 country codes to specify locale, such as pt_BR
(Portuguese Brazilian), fr_CH (Swiss French), etc.
This column can accept multiple pipe-separated values per row - for example, to
list English, Spanish, and French as the languages of a record, you can enter
en|es|fr in the appropriate CSV row.
AtoM maintains an internal list of these language codes, and this validation test
will attempt to compare any values it finds in the language column
to those maintained internally. If a mismatch is found, AtoM will emit an
ERROR.
The short report shown in the console log of the related
job details page will include a count of rows with invalid
language values, as well as a list of the invalid values found during the
validation test. Additionally, the downloadable
detailed report will also include a list of
CSV row numbers where issues have been found.
Recommendation
Use the values provided in the the report to search your CSV and identify the problem language values. Ensure that only supported ISO 639-1 language values are used - replace any problem values with the appropriate language code before re-validating.
For a full list of supported languages and related codes in AtoM, see:
Sample output¶
ERROR 15 - Language Check
--------------
Rows with invalid language values: 1
Invalid language values: English
Details:
CSV row numbers where issues were found: 7