CSV import¶
Most often understood as an acronym for “comma-separated values” (though sometimes called “character-separated values” because the separator character does not have to be a comma), CSV is a file format that stores tabular data in plain-text form. Information with common properties that can be expressed as a sequence of fields sharing a common header can be stored in plain-text using the CSV format, making it application agnostic and highly transportable.
A CSV file consists of a number of records (rows), that have identical fields, separated by commas (or in some cases, another separator). Often a header column (i.e. the cell values in first or top row of a CSV file) is included, naming each column and indicating what kind of data the column contains. Data is then entered using a separator or delimitor (such as a comma) to indicate a separation of fields (or cells), and a line break or carriage return to indicate rows (i.e. different records). Most spreadsheet applications (such as OpenOffice Calc or MS Excel) can open CSV files and express them as a spreadsheet. See Wikipedia for more information on CSV.
In AtoM, the CSV import function allows user to import data from a spreadsheet, or another database (so long as the export from the database is in CSV format). Artefactual has created a number of CSV templates that can be used to import
For small data imports (i.e. CSV files with less than 100 records), CSV files that have been mapped to the sample templates provided (below) can be imported via the user interface.
For large data imports (i.e. CSV files with 100 or more records), the import will need to be performed using the Command-line interface (CLI) - meaning you will need access to your installation environment and some basic familiarity with using the command line.
Below are instructions for using the CSV import module in AtoM to:
- Prepare for your import
- Map legacy IDs to express hierarchical data
- Import archival descriptions
- Import events
- Import archival institutions
- Import authority records
- Import accessions
- Display progress during a command-line import
- Load digital objects via the command line
- Index your content after an upload
See also
Before you import¶
Before you start importing records, there are a number of things you’ll need to do to prepare. You’ll likely want to determine import complexity to see how much technical resources need to be allocated and you’ll want to make modifications to your import data to ensure that it imports properly. Below are some guidelines to help you prepare your data for import into AtoM via CSV.
Important
We strongly recommend that imports never be carried out in your production environment, if possible. Instead, consider deploying a development/test version of your AtoM instance, performing the import(s) there, reviewing the data for any problems and making any required edits via the user interface, and then migrating this data to your production server. For more information, please see our section on Server migration in the Administrators manual.
Important
If your CSV import contains physical storage information, the CSV file must contain information in both of the physical object storage fields: physicalObjectName and physicalObjectLocation. Entering information in physicalObjectName only will result in the creation of duplicates, since AtoM defaults to duplicates rather than accidentally merging separate records with the same location. For example, several collections may contain physicalObjectName Box 1, but adding physicalObjectLocation Shelf 1 will differentiate it from Box 1 on Shelf 5.
Determining import complexity¶
To quickly gauge the complexity of CSV data you wish to import, the
csv:check-import command can be used in the command-line. This command
displays the following:
- The number of rows of data (useful when estimating the amount of processing time needed to perform the import, and whether or not you can use the user interface to perform the import)
- The number of columns (useful when estimating the amount of developer time needed to map the columns to AtoM data - see: CSV Column mapping below)
- How many instances of pipe (|) characters are found in each column (pipe characters are used by some systems to put multiple values in a single cell of data)
- Sample column values
You will need access to the command-line of the server on which AtoM is installed, and you will need to know the file path where your CSV is currently located. Run the command from the root directory of your AtoM install.
Example use:
php symfony csv:check-import lib/task/import/example/rad/example_information_objects_rad.csv
CSV Column mapping¶
AtoM was originally built to encourage broad adoption and use of the ICA’s international standards, and expanded to support other recognized standards. Consequently, all of the description templates in AtoM correspond to a recognized content or metadata exchange standard, and many of the fields in our underlying database model are also inspired by ICA standards. For your data to import successfully into AtoM, you will first need to map it to one of our existing CSV templates, which are derived from the various standards-based templates available in AtoM for description.
Mapping your data to the supplied CSV templates below implies a familiarity with the standards used in AtoM, so you can make appropriate decisions on which fields in your data map to which fields in AtoM, and how to proceed if your data does not easily map 1:1 with the standard upon which our templates are based.
For further information and source links to the standards used in AtoM, see:
The cell values in the top row of a CSV data file conventionally name each column. The name indicates what kind of data the column contains. If the CSV data you wish to import doesn’t include a row like this, you should insert one. You should then make the names correspond to AtoM-friendly names using the top row of data in the example CSV file(s) appropriate to your import.
Available example files are:
- ISAD archival description CSV template
- RAD archival description CSV template
- Authority record CSV template
- Authority record aliases CSV template
- Authority record relationships CSV template
- Accessions CSV template
- Events CSV template
All CSV templates can be found on the AtoM wiki:
You can also find all example CSV import templates included in your AtoM
installation, in: lib/task/import/example.
The order of the columns in the example CSV files is the same as the order in the AtoM interface, and should be maintained. Having the correct names in the cell values of the first row of your CSV data enables AtoM to import values in each column to the correct AtoM fields.
Tip
A good way to make sure your column mapping is correct is to create a blank row after the top row and populate this with test values. You can then do an import, stop it after the first row (using CTRL-C), and make sure that all the values from the CSV row are present in AtoM. Including, in each field of a row, the letter corresponding to the corresponding spreadsheet column (including, for example, the text “(A)” for data in spreadsheet column A) makes it easy to quickly determine if a field is showing up on the AtoM side after import.
Verify character encoding and line endings¶
For your CSV files to import properly, you will need to ensure two things prior to importing: that the character encoding of your CSV file is set to UTF-8, and that the end-of-line characters used in your CSV conform to the Unix/Linux style of newline character.
Important
Your import will likely fail if you don’t ensure these two things are are correctly set prior to import! Please review the sub-sections below for further details.
Character encoding (UTF-8)¶
For a CSV file to upload properly into AtoM (and display any special characters such as accents contained in the data), your CSV file must use a UTF-8 character encoding. If you have used a Windows or Mac spreadsheet application (such as Excel, for example), it’s possible that the default character encoding will not be UTF-8. For example, Excel uses machine-specific ANSI encoding as its defaults during install, so an EN-US installation might use Windows-1252 encoding by default, rather than something more universal such as UTF-8 (the default encoding in AtoM). This can cause problems on import into AtoM with special characters and diacritics. Make sure that if you are using Excel or another spreadsheet application, you are setting the character encoding to UTF-8. Many open source spreadsheet programs, such as LibreOffice Calc, use UTF-8 by default, and include an easy means for users to change the default encoding.
Tip
For Excel users, here is an eHow guide on converting CSV files to UTF-8: http://www.ehow.com/how_8387439_save-csv-utf8.html
Line endings¶
“In computing, a newline, also known as a line ending, end of line (EOL), or line break, is a special character or sequence of characters signifying the end of a line of text. The actual codes representing a newline vary across operating systems, which can be a problem when exchanging text files between systems with different newline representations.” (Wikipedia)
Here are some of the differences:
- Unix / Linux / FreeBSD / OS X use LF (line feed,
\n, 0x0A) - Macs prior to OS X use CR (carriage return,
\r, 0x0D) - Windows / DOS use CR+LF (carriage return followed by line feed,
\r\n, 0x0D0A)
AtoM’s CSV import will expect Unix-style line breaks ( \n ). If you have
been using a spreadsheet application (such as Excel) on a Mac or Windows, you
may encounter import issues. There are many command-line utilities and free
software options out there to convert newline characters. Please ensure that
your spreadsheet is using the correct line endings prior to upload, otherwise
the upload will fail.
Data transformation¶
If you are working with a CSV export from another system (such a different database), you may need to do further pre-processing to prepare your CSV. If your previous system was designed for standards-compliance to a standard that AtoM supports (see: Descriptive standards), the mapping process might be simple - but if your system used custom data fields, mapping to one of the supported standards could be trickier.
You may, for example, want to combine multiple CSV column values, that don’t cleanly map conceptually to AtoM-compatible CSV columns, into single columns so they can be put into AtoM as notes. So ColumnA and ColumnB could be combined into a generalNote column. This requires you to transform the data before importing.
Depending on the size of your import data, this work can be done manually using a spreadsheet program - simply cut and paste your data into the corresponding cell in the provided import templates. However, for larger data sets, data transformation can be done with custom programming (for example, a Python script written by a developer), existing tools such as the open source Pentaho Data Integration application, or by use of a CSV transformation script.
We have included some guidelines for creating custom CSV transformation scripts. See:
Note
Creating custom CSV scripts is an activity generally performed by a developer.
Estimating import duration¶
Once you’ve mapped the columns names in your CSV export to the corresponding AtoM-compatible CSV column names you may wish to perform a test import.
A test import gives you an idea how long the import will take to complete on your hardware. To estimate how long it will take to import 20,000 rows of CSV data, for example, you could time the import of the first 1000 records and multiply that by 20.
If your test import proves to be too slow on your hardware, or you don’t have hardware to spare, you can consider using cloud computing resources, such as Open Hosting, Amazon EC2, or Rackspace Cloud.
Testing your import¶
Once you’ve prepared your import, you may want to clone your AtoM site and test your import on the clone before importing to your production AtoM installation. This prevents you from having to delete any improperly imported data. During import testing if you want to delete all imported data you can use the command-line purge tool.
Legacy ID mapping: dealing with hierarchical data in a CSV¶
The legacyId column in imports is used to associate specific legacy data to AtoM data using ID columns. Why would you need to associate this data? Let’s say you’re importing a CSV file of description data you’ve exported from a non-AtoM system. If the imported descriptions are in any way hierarchical – with a fond containing items for example – a column in a child description will have to specify the legacy ID of its parent. The parent’s legacy ID can then be used to look up the AtoM ID of the parent that was imported earlier. With the AtoM ID discovered, the parent/child relationship can then be created. In addition to hierarchical description data, supplementary data such as events must specify a legacy parent ID when imported.
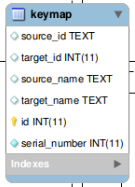
A representation of the keymap table in AtoM, from an Entity Relationship Diagram of AtoM’s MySQL database.
When CSV data is imported into AtoM, values in the legacyID column are stored in AtoM’s keymap table, in a column named source_id. A system administrator or developer can access this information, either via the command-line, or by using a graphical application such as phpMyAdmin to look up exising legacy ID values in the source_id column of the MySQL keymap table.
In cases where data is being imported from multiple sources, legacy IDs may
conflict. Two datasets, for example, may have objects with an ID of 3. When
importing, you can use the command-line option --source-name to only record
or reference mappings for a specific data source. This will add a value in
the source_name column of AtoM’s keymap table, which can then be used for
mapping subsequent imports.
The following example shows an import of information objects that records a specific source name when mapping legacy IDs to AtoM IDs:
php symfony csv:import information_objects_rad.csv --source-name=collection_name
In the above example, collection_name represents the value added by the user during import - now collection_name will be added to the source_name column of the keymap table for all records imported. Given the above example, the subsequent import of events using the following command would make sure that they get associated with information objects from the specific source identified as collection_name:
php symfony csv:event-import events.csv --source-name=collection_name
Tip
If you use the --source-name command-line option during your CSV
import and you want to use spaces in the source name you add, you will
need to enclose it in quotation marks. For example, both of the following
are valid:
php symfony csv:import information_objects_rad.csv –source-name=collection_name
or:
php symfony csv:import information_objects_rad.csv –source-name=”collection name”
The --source-name option can also be used to keep larger imports that
have been broken into multiple CSV files related. Adding the --source-name
option to each CSV import, with a common name added for each, will prevent
AtoM from duplicating import data, such as terms and actors
(authority records) during import.
Import archival descriptions via CSV¶
The information object import tool allows you to map CSV columns to AtoM data.
Example RAD and ISAD CSV template files are available in AtoM source code
(lib/task/import/example/rad/example_information_objects_rad.csv and
lib/task/import/example/isad/example_information_objects_isad.csv) or you
can download the files here:
Hierarchical relationships¶
Information objects often have parent-child relationships - for example, a series is a child of the fonds to which it belongs; it has a parent fonds. If you want to import a fonds or collection into AtoM along with its lower levels of description (i.e. its children - series, files, items, etc.), you will need a way to specify which rows in your CSV file belong to which parent description.
There are two basic ways to specify which information object is the parent of an information object being imported in your CSV - either through the use of the legacyID and parentID columns (generally used for new descriptions being imported, or from descriptions being migrated from another access system), or by using the qubitParentSlug column to import new child descriptions to an existing description in AtoM.
Warning
Note that if you set both the parentId and qubitParentSlug in a single row, the import will default to using the qubitParentSlug. In general, only one type of parent specification should be used for each imported information object (i.e. each row in your CSV).
You can use a mix of legacyId/parentId and qubitParentSlug in the same CSV, just not in the same row. So, for example, if you wanted to import a series description as a child of a description already in AtoM, as well as several files as children of the series description, you could set a legacyID for the series, use the qubitParentSlug to point to the parent fonds or collection already in AtoM, and then use the parentID column for all your lower-level file descriptions. However, using both parentID and qubitParentSlug in the same row will cause a conflict, and AtoM will prefer the qubitParentSlug so the import does not fail.
Both methods of establishing hierarchical relationships are described below.
LegacyID and parentID¶
One way to establish hierarchical relationships during a CSV import involves the use of the parentId column to specify a legacy ID (referencing the legacyId column of a previously imported information object). This way is most often used for migrations from other access systems. Using this method, parent descriptions (e.g. fonds, collections, etc) must appear first (i.e. above) in your CSV and must include a legacyID - while child records must appear after (i.e. below) their parent records in your CSV, and must include the legacyID of the parent record in the parentID column.
Here is an example of the first three columns of a CSV file (shown in a spreadsheet application), importing a Fonds > Series > Item hierarchy:

Important
When the CSV is imported, it progresses row by row - meaning, if your CSV is not properly ordered with parent records appearing before their children, your import will fail!
qubitParentSlug¶
The other method of importing hierarchical data into AtoM enables you to specify an existing archival description that doesn’t have a legacyID (one, for example, that has been manually created using the AtoM web interface), and import descriptions as children of the target description(s).
To specify a parent that exists in AtoM, you must first take note of the parent information object’s slug. The “slug” is a textual identifier that is included in the URL used to view the parent description. If the URL, for example, is http://myarchive.com/AtoM/index.php/example-fonds then the slug will be example-fonds. This slug value would then be included in your import in the qubitParentSlug column in the rows of children of the parent description.
Alternately, if you are using the command-line to perform your import, you can
use the --default-parent-slug option in the command-line to set a default
slug value, that will be used when no qubitParentSlug or parentID values
have been included for the row. For more information, see the details in the
Command-line options section below.
Here is an example of the first few columns of a CSV file (shown in a spreadsheet application), importing a new series to an existing fonds, and importing two new file-level descriptions to an existing series:

If desired, you can mix the use of the qubitParentSlug column with the use of the parentID column in the same CSV - for example, you could attach a new series to an existing fonds by giving it a legacyID and the slug for the existing fonds in the qubitParentSlug column, and then including lower-level files attached to the new series by adding the legacyID of the new series to the parentID column of the new files.
Important
You should not add both a parentID and a qubitParentSlug to the same row - AtoM expects one or the other. When the import encounters both columns populated in a single row, AtoM will default to use the qubitParentSlug value. In general, each row must have only one or the other - either a parent slug, or a parent ID.
Creator-related import columns (actors and events)¶
The eventActors, eventActorHistories, eventTypes, eventDates, eventStartDates, and eventEndDates columns are related to the creation of actors and events. In AtoM’s data model, an archival description is a description of a record, understood as the documentary evidence created by an action - or event. It is events that link actors (represented in AtoM by an authority record) to archival descriptions - see Entity types for more information.
The most common use for these columns is to add creation dates associated with an actor via an authority record - in this case, the eventType is Creation, the eventActor is the creator, and the various eventDates fields are the dates of creation associated with the description.
However, some standards support other types of events as well. For example, the ISAD(G) template in AtoM also supports Accummulation as an event type, while the Canadian RAD template allows direct association between actors and events, and includes many other event types, such as contribution, broadcasting, manufacturing, and more.
A brief summary of the fields is included below, followed by a longer discussion of their use:
eventActors: Add the associated creator or other actor name here. AtoM will link to an existing authority record or create a new one. For details on linking behavior, see below: On Authority records, archival descriptions, and CSV imports.eventActorHistories: Add the associated creator or other actor’s administrative or biographical history here. Equivalent to ISAD(G) 3.2.2, RAD 1.7B, and/or DACS 2.7 - Administrative/Biographical history. This will be mapped to the related authority record.eventTypes: Type of event. Values include:- ISAD: Creation, Accumulation
- RAD: Creation, Accumulation, Contribution, Collection, Broadcasting, Manufacturing, Custody, Publication, Reproduction, Distribution
eventDates: Display dates shown in public user interface for event onarchival description view page. May use free-text, including typographical conventions to express approximation or uncertainty (e.g. [190-?]; [ca. 1885]).
eventStartDates: Internal ISO-8601 formatted (e.g. YYYY, YYYY-MM,YYYY-MM-DD) start date of event
eventEndDates: Internal ISO-8601 formatted (e.g. YYYY, YYYY-MM,YYYY-MM-DD) end date of event
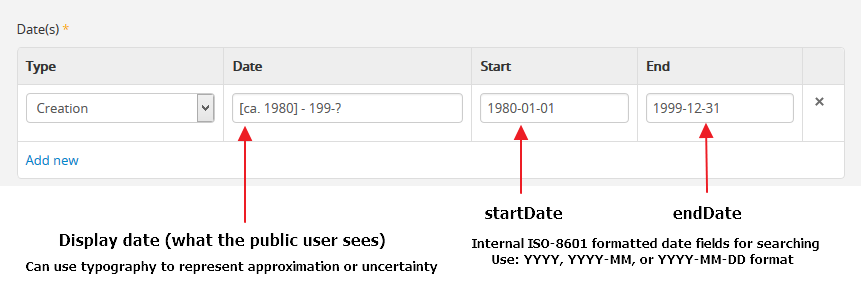
eventDescriptions: Only in RAD CSV template. Adds a note to the eventeventPlaces: Only in RAD CSV templates. Associates a place with the event.
If multiple actors/events exist for an information object, the values in these fields can be pipe-separated (e.g. using the | pipe separator between values).

On Authority records, archival descriptions, and CSV imports¶
AtoM tries to support the reusability of actor information through the maintenance of authority records that can be linked to archival descriptions and other entities. This, and the rationale for this, is outlined in greater detail in the following sections:
- AtoM, Authority records, Biographical histories, and Name access points
- On Name vs. Subject Access Points
This also affects how actor names are handled during a CSV import. Some of the key behaviors are outlined below:
Creating new actor records on import
- AtoM looks for creator names in the eventActors column in the RAD and ISAD CSV import templates, as well as access point names (used as subjects) in the nameAccessPoints column during a CSV import of archival descriptions.
- Similarly, any Administrative / biographical history data in an archival description CSV import (i.e. data contained in the eventActorHistories CSV column will be mapped to the “History” field (ISAAR-CPF 5.2.2) in the related authority record (generated from the data contained in the creators column of the CSV), and then is presented in AtoM in any related descriptions where the entity is listed as a creator.
- Where multiple creator names and histories are included in an import,
eventActors and eventActorHistories elements are matched 1:1 in the
order they appear in the CSV, divided by pipe elements (e.g.
|). For example, if the eventActors column containsname 1|name 2, the eventActorHistories should also includehistory 1|history 2to match on import. If there is no history for the first actor, you can includeNULL, and AtoM will ignore the imput - e.g.name 1|name 2should be matched withNULL|history 2to include only a history for name 2. - This same
NULLapproach can be used for any matched date values where multiple actor names are included for import -eventDates,eventStartDates,eventEndDatescan all includeNULLif you wish to leave these blank when associating multiple actors with an event. An example, using the RAD template:

- If a creator history element is included in a CSV import, but no creator name is included, AtoM will still automatically generate a stub authority record and map the history data to the “History” field (ISAAR-CPF 5.2.2) - the authority record will be left untitled, until the user manually adds the appropriate name to the authority record. Similarly, if there are more eventActorHistories elements included in an import than creator names included in the creators column, the final biographical/administrative history will be mapped to an untitled authority record. Because the slug is normally based on the title of the authority record, AtoM will generate a random alphanumeric string to use as the slug - and you will not be able to edit this through the user interface.
Attempting to match to existing authority records
Important
If you are attempting to import both an archival description CSV and an authority record CSV to supplement the actor data that is linked to your descriptions, you must import the authority record CSV first. On import, the description CSV code will look for exact matches to which it can link - but the authority record CSV import code does not currently have similar logic. If you import your authority record CSV template after the description CSV, you might end up creating duplicate authority records!
- AtoM will attempt to find matches for current authority records. However, to avoid collisions, or situations in which multiple imports overwrite the same authority record in a multi-repository system, the approach is conservative - for a match to be made and a link to an existing record added instead of a new record being created, the authorized form of name must be an exact match.
- Note that if biographical/administrative history included in the CSV will be ignored - it will not update an existing history when a match is made.
- If there is no exact match on the authorized form of name, then AtoM will create a new actor record. Since AtoM does not currently have the capacity to suspend the import and ask the user whether to update an existing authority record or ignore it and create a new one, this method was chosen as the least destructive. However, this means that currently, administrative or biographical histories CANNOT be updated via an import.
- This also means that users should be careful to double check authority linking behaviors in AtoM following an import, and manually perform any desired adjustments where needed.
See also
Digital object-related import columns¶
As of AtoM 2.1, two new columns have been added to the
ISAD and RAD CSV import
templates: digitalObjectPath and digitalObjectURI. These columns will
allow you to link or upload a digital object and attach it to the new
information object being created in that row of the CSV.
In AtoM, a 1:1 relationship is maintained between information objects and digital objects - meaning that for every archival description, you can only attach one digital object. If you wish, you can create new child records - a number of item descriptions as children of a file-level description; a number of part descriptions as children of an item (for multiple views of a single object, for example, or individual pages of a single book uploaded separately, etc), and so on.
In the CSV templates, the digitalObjectPath and digitalObjectURI
columns are positioned after the publicationStatus column, and before
the physical object-related import columns.

The digitalObjectPath column can be used to upload local digital objects -
simply provide a complete path and filename to the digital object.
The digitalObjectURI column can be used to link to externally hosted,
publicly available digital objects, such as those available at a specific URL
on the web. You must have a path directly to the digital object which includes
a file extension, and not just to a web page with a digital object located on
it somewhere - it is often the equivalent of right-clicking on a digital
object in your browser and selecting “View image”.
You can use a mixture of the digitalObjectPath and digitalObjectURI
columns throughout your CSV (linking some information object rows to locally
uploaded digital objects, and others to web-based resources), but you cannot
use both columns in the same row. If AtoM encounters a CSV row where both the
digitalObjectPath and digitalObjectURI columns are populated, it will
favor the digitalObjectURI value, and ignore the digitalObjectPath
value.
See also
Physical object-related import columns¶
The physicalObjectName, physicalObjectLocation, and physicalObjectType columns are related to the creation of physical objects and physical storage locations related to an archival description.

For more information on working with physical storage in AtoM, see: Physical storage.
Other data entry notes¶
- language and languageOfDescription, like culture, expect two-letter
ISO 639-1 language code values - for example, “en” for English; “fr” for French,
“it” for Italian, etc. See Wikipedia
for a full list of ISO 639-1 language codes. Unlike the culture column,
however, these two fields will accept multiple values separated by a pipe
character - for example,
en|fr|it. - The script and scriptOfDescription columns expect four-letter ISO 15924 script code values - for example, “Latn” for Latin-based scripts, “Cyrl” for Cyrillic scripts, etc. See Unicode for a full list of ISO 15924 script codes.
- Alternative identifiers and their display labels can be imported using the
alternativeIdentifiers and alternativeIdentifierLabels columns. Use pipe
(
|) separators to add multiple values. There should be a 1:1 relationship between the number of identifier values in the alternativeIdentifiers column and corresponding labels in the alternativeIdentifierLabels column. - An accessionNumber column can be added to create a link between an existing accession record and an archival description being imported via CSV. See the section on Accession CSV import below for more information.
Using the user interface¶
For small imports (i.e. CSV files with less than 100 records), imports can be performed via the user interface.
Important
Before proceeding, make sure that you have reviewed the instructions above, to ensure that your CSV import will work. Here is a basic checklist of things to check for importing a CSV of archival descriptions via the user interface:
- CSV file is saved with UTF-8 encodings
- CSV file uses Linux/Unix style end-of-line characters (
/n) - CSV file is less than 100 records
- All parent descriptions appear in rows above their children
- All new parent records have a legacyID value, and all children include the parent’s legacyID value in their parentID column
- No row uses both parentID and qubitParentSlug (only one should be used - if both are present AtoM will default to using the qubitParentSlug)
- Any records to be imported as children of an existing record in AtoM use the proper qubitParentSlug of the existing parent record
If you have double-checked the above, you should be ready to import your descriptions.
To import a CSV file via the user interface:
- Click on the
 Import menu, located in
the AtoM header bar, and select “CSV”.
Import menu, located in
the AtoM header bar, and select “CSV”.
- AtoM will redirect you to the CSV import page. Make sure that the “Type” drop-down menu is set to “Archival description”.
- Click the “Browse” button to open a window on your local computer. Select the CSV file that you would like to import.
- When you have selected the file from your device, its name will appear next to the “Browse” button. Click the “Import” button located in the button block to begin your import.
Note
Depending on the size of your CSV import, this can take some time to complete. Be patient! Remember, uploads performed via the user interface are limited by the browser’s timeout limits - this is one of the reasons we recommend importing only smaller CSV files via the user interface.
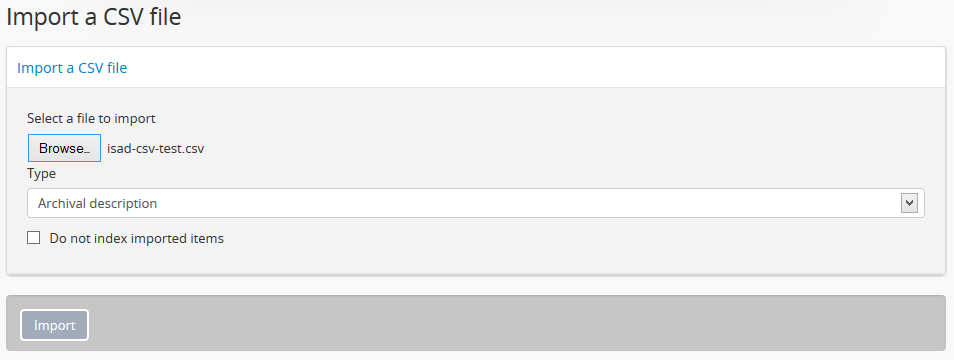
- After your import is complete, AtoM will list the amount of time the import took, and provide a link to the archival description browse page. Unlike the XML import, a link directly to your import is not provided, because a CSV upload may contain multiple descriptions; instead, a link to the browse page is given, so users can locate their descriptions.

Tip
Use the sort button located in the top-right hand side of the browse page to change the results display to be ordered by “Most recent” if it is not already - that way, the most recently added or edited descriptions will appear at the top of the results. If you have come directly here after importing your descriptions, they should appear at the top of the results.
- If any warnings or errors are encountered, AtoM will also display them on the import page. Some warnings will cause an import to fail (and some will not - they will alert the user, but the import will still complete), while all error messages mean that the import has failed, and a link to the archival description browse page will not be provided. - instead, the CSV upload page will reappear below the error message. Errors can occur for many reasons - please review the checklist above for suggestions on resolving the most common reasons that CSV imports fail.
Using the command-line interface (CLI)¶
For larger CSV imports (e.g. those with 100 or more records), we recommend using the Command-line interface to import your descriptions.
Example use (with the RAD CSV template) - run from AtoM’s root directory:
php symfony csv:import lib/task/import/example/rad/example_information_objects_rad.csv
Command-line options¶
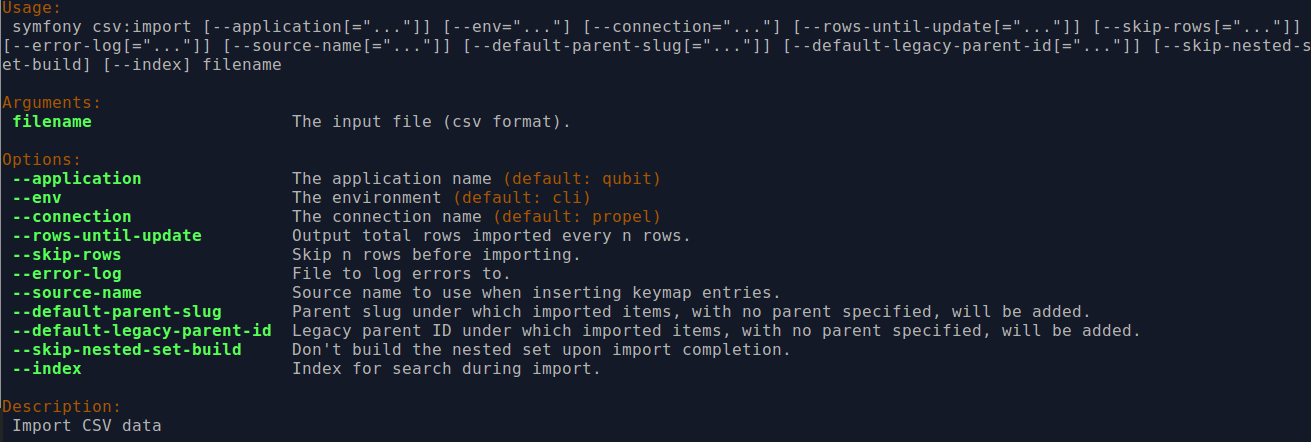
By typing php symfony help csv:import into the command-line from your root
directory, without specifying the location of a CSV, you will able able to
see the CSV import options available (pictured above). A brief explanation of
each is included below.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update option can be used for a simple visual
representation of progress in the command-line. Enter a whole integer, to
represent the number of rows should be imported from the CSV before the
command-line prints a period (e.g. `` . `` ) in the console, as a sort of
crude progress bar. For example, entering --rows-until-update=5 would
mean that the import progresses, another period will be printed every 5 rows.
This is a simple way to allow the command-line to provide a visual output of
progress. For further information on the --rows-until-update option and an
example of the command-line option in use, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
You can use the --skip-rows option to skip X amount of rows in the CSV
before beginning the import. This can be useful if you have interrupted the
import, and wish to re-run it without duplicating the records already
imported. --skip-rows=10 would skip the first 10 rows in the CSV file,
for example. Note that this count does not inlcude the header column, so
in fact, the above example would skip the header column, and rows 2-11 in
your CSV file.
The --error-log option can be used to specify a directory where errors
should be logged. Note that this option has not been tested by Artefactual
developers.
Use the --source-name option (described above
to specify a source when importing information objects from multiple sources
(with possibly conflicting legacy IDs). This will ensure that multiple related
CSV files will remain related - so, for example, if you import an
archival description CSV, and then supplement the
authority records created (from the creators field
in the description CSV templates) with an authority record CSV import, using the
--source-name option will make sure that matching names are linked and
related, instead of duplicate authority records being created. You can also
use this option to relate a large import that is broken up into multiple
CSV files. See the Legacy ID mapping: dealing with hierarchical data in a CSV section above for further
tips and details on the uses of this option.
The --default-legacy-parent-id option will allow the user to set a default
parentID value - for any row in the CSV where no parentID value is
included and no qubitParentSlug is present, this default value will be
inserted as the parentID.
Similarly, the --default-parent-slug option allows a user to set a
default qubitParentSlug value - wherever no slug value or parentID /
legacyID is included, AtoM will populate the qubitParentSlug with the
default value. If you are importing all rows in a CSV file to one parent
description already in AtoM, you could use the --default-parent-slug option
to specify the target slug of the parent, and then leave the legacyID,
parentID, and qubitParentSlug columns blank in your CSV. Note that this
example will affect ALL rows in a CSV - so use this only if you are
importing all descriptions to a single parent!
By default, AtoM will build the
nested set after an import
task. The nested set is a way to manage hierarchical data stored in the flat
tables of a relational database. However, as Wikipedia notes, “Nested sets are
very slow for inserts because it requires updating left and right domain values
for all records in the table after the insert. This can cause a lot of database
thrash as many rows are rewritten and indexes rebuilt.” When performing a large
import, it can therefore sometimes be desirable to disable the building of the
nested set during the import process, and then run it as a separate command-line
task following the completion of the import. To achieve this, the
--skip-nested-set-build option can be used to disable the default behavior.
NOTE that the nested set WILL need to be built for AtoM to behave as expected. You can use the following command-line task, from the AtoM root directory, to rebuild the nested set if you have disabled during import:
php symfony propel:build-nested-set
Tip
Want to learn more about why and how nested sets are used? Here are a few great resources:
- Mike Hyllier’s article on Managing Hierarchical data in MySQL
- Evan Petersen’s discussion of nested sets
- Wikipedia’s Nested set model
Similarly, when using the user interface to perform an import, the import is indexed automatically - but when running an import via the command-line interface, indexing is disabled by default. This is because indexing during import can be incredibly slow, and the command-line is generally used for larger imports. Generally, we recommend a user simply clear the cache and rebuild the search index following an import - from AtoM’s root directory, run:
php symfony cc && php symfony search:populate
However, if a user would like to index the import as it progresses, the
--index option can be used to enable this.
Import events via CSV¶
The information object (e.g., archival description) import tool allows you to import creation events, but doesn’t accommodate other types of events, such as accumulation, broadcasting, etc).
For this the event import tool is better suited and should be ran after you import your information objects.
The event import processes 3 CSV columns: legacyId, eventActorName, and
eventType. The legacyId should be the legacy ID of the information object the
event will be associated with. The eventActorName and eventType specify the
name of the actor involved in the event and the type of event. An example CSV
template file is available in the AtoM source code
(lib/task/import/example_events.csv) or can be downloaded here:
Important
Before proceeding, make sure that you have reviewed the instructions above, to ensure that your CSV import will work. Here is a basic checklist of things to check for importing a CSV of events via the user interface:
- CSV file is saved with UTF-8 encodings
- CSV file uses Linux/Unix style end-of-line characters (
/n) - CSV file is less than 100 records if importing via the user interface
- All legacyID values entered correspond to the legacyID values of their corresponding archival descriptions
- If you are referencing existing authority records already in AtoM, make sure that the name used in the actorName column matches the authorized form of name in the authority record exactly.
If you have double-checked the above, you should be ready to import your events.
Using the user interface¶
For small imports (i.e. CSV files with less than 100 records), imports can be performed via the user interface.
To import an events CSV file via the user interface:
- Click on the Import menu, located in
the AtoM header bar, and select “CSV”.
- AtoM will redirect you to the CSV import page. Make sure that the “Type” drop-down menu is set to “Event”.
- Click the “Browse” button to open a window on your local computer. Select the events CSV file that you would like to import.
- When you have selected the file from your device, its name will appear next to the “Browse” button. Click the “Import” button located in the button block to begin your import.
Note
Depending on the size of your CSV import, this can take some time to complete. Be patient! Remember, uploads performed via the user interface are limited by the browser’s timeout limits - this is one of the reasons we recommend importing only smaller CSV files via the user interface.
Using the command-line interface (CLI)¶
For larger CSV imports (e.g. those with 100 or more records), we recommend using the Command-line interface to import your descriptions.
Example use - run from AtoM’s root directory:
php symfony csv:event-import lib/task/import/example/example_events.csv
There are also various command-line options that can be used, as illustrated in the options depicted in the image below:
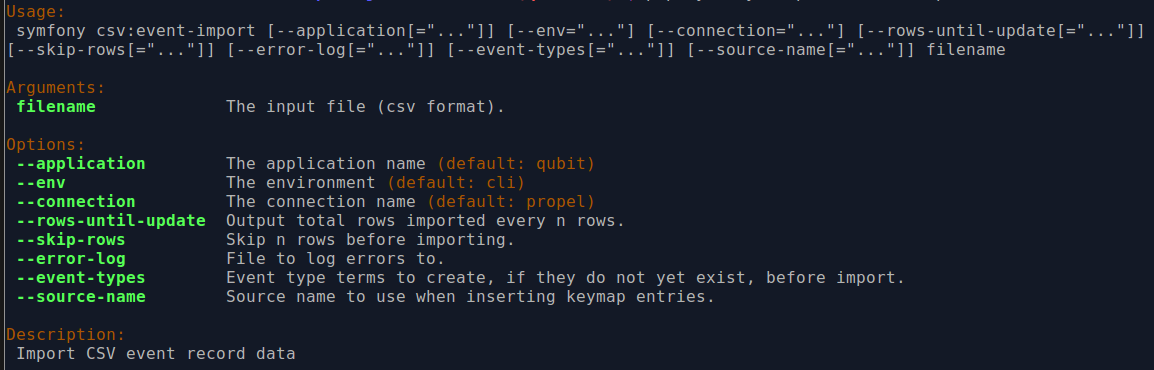
By typing php symfony help csv:event-import into the command-line from your
root directory, without specifying the location of a CSV, you will able able to
see the CSV import options available (pictured above). A brief explanation of
each is included below.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update, --skip-rows, and --error-log options can
be used the same was as described in the section above
on importing descriptions. For more information on the --rows-until-update
option, see also the section below, Display the progress of an upload via the command-line interface (CLI).
Use the --source-name to specify a source importing to a AtoM installation
in which information objects from multiple sources have been imported, and/or
to associate it explicitly with a previously-imported CSV file that used the
same --source-name value. An example is provided
above in the section on legacy ID mapping.
The --event-types option is deprecated, and no longer supported in AtoM.
Import archival institutions via CSV¶
You can import repositories (i.e. archival institutions into AtoM as well. At this time, there is no support for importing a repository CSV via the user interface - however, the command-line may be used.
Find the example CSV import template here:
CSV columns¶
- The uploadLimit column allows a user to set a default upload limit for a repository at the time of import. This value should be a number, representing Gigabytes. For more information on the use of respository upload limits in AtoM, see: Set digital object upload limit for an archival institution.
- Almost all other fields are drawn directly from the archival institution
edit template in AtoM, which is based upon the International Council on
Archives’ International Standard for Describing Institutions with Archival
Holdings (ISDIAH).
For more information on the use of each field, see: International Standard for Describing Institutions with Archival Holdings.
- Most fields in the CSV template have been named in a fairly obvious way, translating a simplified version of the field name in our data entry templates into a condensed camelCase. For example, ISDIAH 5.3.2, Geographical and cultural context (in the Description Area) becomes geoCulturalContext in the CSV template. Consult the ISDIAH for further help with fields.
- The culture column indicates to AtoM the language of the descriptions being uploaded. This column expects two-letter ISO 639-1 language code values - for example, “en” for English; “fr” for French, “it” for Italian, etc. See Wikipedia for a full list of ISO 639-1 language codes.
Important
Before proceeding, make sure that you have reviewed the “Before you import” instructions above, to ensure that your CSV import will work. Most importantly, make sure your:
- CSV file is saved with UTF-8 encodings
- CSV file uses Linux/Unix style end-of-line characters (
/n)
Using the command-line¶
Example use - run from AtoM’s root directory:
php symfony csv:repository-import lib/task/import/example/example_repositories.csv
There are also various command-line options that can be used, as illustrated in the options depicted in the image below:
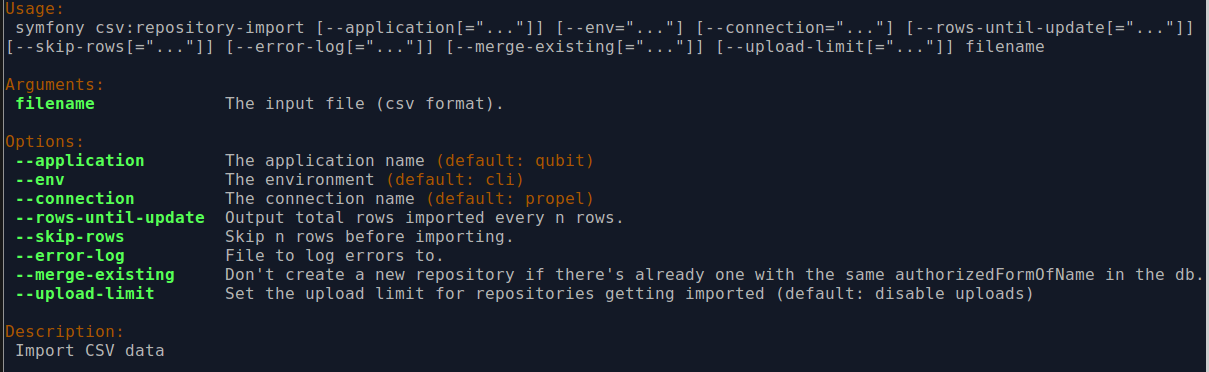
By typing php symfony help csv:repository-import into the command-line from
your root directory, without specifying the location of a CSV, you will able
able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update, --skip-rows, and --error-log options can
be used the same was as described in the section above
on importing descriptions. For more information on the --rows-until-update
option, see also the section below, Display the progress of an upload via the command-line interface (CLI).
The --merge-existing option may be used to avoid the creation of
duplicate repositories. That is - if, during import, any rows in the CSV
contain the same authorized form of name as a repository already in the
database, those rows will be ignored (i.e. not imported).
You can use the --upload-limit option to specify the default upload limit for
repositories which don’t specify their uploadLimit in the CSV file. That is,
if for example you performed a CSV import with the command-line option of
--upload-limit=5, then for every repository in the CSV that does NOT have
a value in the uploadLimit column, the default value of 5 GBs will be
assigned.
Import authority records via CSV¶
The authority record import tool allows you to import data about organizations and individuals. In addition to importing data detailing these entities, the tool also allows the simultaneous import of supplementary data (in separate CSV files) on how these entities relate to each other and alternate names these entities are known by.
You can view the example CSV files for authority records in the AtoM code (at
lib/task/import/example/authority_records/) or they can be downloaded directly
here:
CSV Columns¶
A brief explanation of the main fields in each CSV template is included below.
Authority records CSV¶
Important
If you are attempting to import both an archival description CSV and an authority record CSV to supplement the actor data that is linked to your descriptions, you must import the authority record CSV first. On import, the description CSV code will look for exact matches to which it can link - but the authority record CSV import code does not currently have similar logic. If you import your authority record CSV template after the description CSV, you might end up creating duplicate authority records!
- The culture column indicates to AtoM the language of the descriptions being uploaded. This column expects two-letter ISO 639-1 language code values - for example, “en” for English; “fr” for French, “it” for Italian, etc. See Wikipedia for a full list of ISO 639-1 language codes.
- the typeOfEntity column maps to the entity type terms recommended in ISAAR 5.1.1 Type of Entity, and maintained in AtoM in the Actor Entity Types taxonomy. This column expects one of three recommended values - Person, Corporate body, or Family.
- Almost all other fields are drawn directly from the authority record
edit template in AtoM, which is based upon the International Council on
Archives’ International Standard Archival Authority Record for Corporate
Bodies, Persons and Famillies (ISAAR-CPF).
For more information on the use of each field, see: International Standard Archival Authority Record for Corporate Bodies, Persons, and Families.
- Most fields in the CSV template have been named in a fairly obvious way, translating a simplified version of the field name in our data entry templates into a condensed camelCase. For example, ISAAR 5.2.1, Dates of Existence (in the ISAAR Description Area) becomes datesOfExistence in the CSV template. Consult the ISDIAH for further help with fields.
- The history column, which conforms to ISAAR 5.2.2, will appear as the Administrative or Biographical history in any archival description that the authority record is linked to. For more information on how AtoM manages authority records, see: Authority records.
Alternate names CSV¶
- The parentAuthorizedFormOfName should match exactly a target name in the related authority record CSV being imported. The aliases (or alternate names) included in the Aliases CSV will be associated with that actor’s authority record following import.
- The alternateForm should include the alternate name or alias you wish to import.
- The formType column contains data about what kind of alternate is being created. Each alias can be one of three forms: a parallel form, a standardized form according to other descriptive practices, or an “other” form. Enter either “parallel”, “standardized”, or “other” as a value in this the cells of this column. For more information on the distinction between these three types of alternate names, please consult ISAAR-CPF 5.1.3 - 5.1.5
- The culture column indicates to AtoM the language of the descriptions being uploaded. This column expects two-letter ISO 639-1 language code values - for example, “en” for English; “fr” for French, “it” for Italian, etc. See Wikipedia for a full list of ISO 639-1 language codes.
Relationships CSV¶
- The sourceAuthorizedFormOfName is used to specify one of the actors included in the Authority record CSV upload. This field should match exactly one of the actors listed in the authorizedFormOfName column of the Authority record CSV.
- The targetAuthorizedFormOfName is also used to specify one of the actors in the Authority record CSV upload - the actor with which you intend to create a relationship. The values entered int this column should match exactly one of the actors listed in the authorizedFormOfName column of the Authority record CSV.
- The category column contains data about the type of relationship you are creating, and maps to ISAAR 5.3.2 Category of Relationship. The terms recommended in the ISAAR standard are maintained in the Actor Relation Type taxonomy in AtoM. Values entered should be either “associative”, “family”, “hierarchical”, or “temporal”. For more information on the distinction between these terms, please consult ISAAR-CPF 5.3.2.
- The date field is a free-text string field that will allow a user to enter a date or date range for the relationship. It allows the use of special characters and typographical marks to indicate approximation (e.g. [ca. 1900]) and/or uncertainty (e.g. [199-?]). Use the startDate and endDate fields to enter ISO-formated date values (e.g. YYYY-MM-DD, YYYY-MM, or YYYY) that correspond to the free-text date field. Public users in the interface will see the date field values when viewing relationships; the startDate and endDate values are not visible, and are used for date range searching in the application.
- The culture column indicates to AtoM the language of the descriptions being uploaded. This column expects two-letter ISO 639-1 language code values - for example, “en” for English; “fr” for French, “it” for Italian, etc. See Wikipedia for a full list of ISO 639-1 language codes.
Important
Before proceeding, make sure that you have reviewed the “Before you import” instructions above, to ensure that your CSV import will work. Most importantly, make sure your:
- CSV file is saved with UTF-8 encodings
- CSV file uses Linux/Unix style end-of-line characters (
/n)
Using the user interface¶
Note
Only the basic Authoriy record CSV can be imported via the user interface. If you wish to import authority relationships and aliases as well, you will need to use the command-line. Imports conducted via the user interface should include no more than 100 records - otherwise we strongly recommend you use the command-line!
To import authority records via the user interface:
- Click on the Import menu, located in
the AtoM header bar, and select “CSV”.
- AtoM will redirect you to the CSV import page. Make sure that the “Type” drop-down menu is set to “Authority record”.
- Click the “Browse” button to open a window on your local computer. Select the authority record CSV file that you would like to import.
- When you have selected the file from your device, its name will appear next to the “Browse” button. Click the “Import” button located in the button block to begin your import.
Note
Depending on the size of your CSV import, this can take some time to complete. Be patient! Remember, uploads performed via the user interface are limited by the browser’s timeout limits - this is one of the reasons we recommend importing only smaller CSV files via the user interface.
Using the command-line interface (CLI)¶
Example use - run from AtoM’s root directory:
php symfony csv:authority-import lib/task/import/example/authority_records/example_authority_records.csv
There are also various command-line options that can be used, as illustrated in the options depicted in the image below:
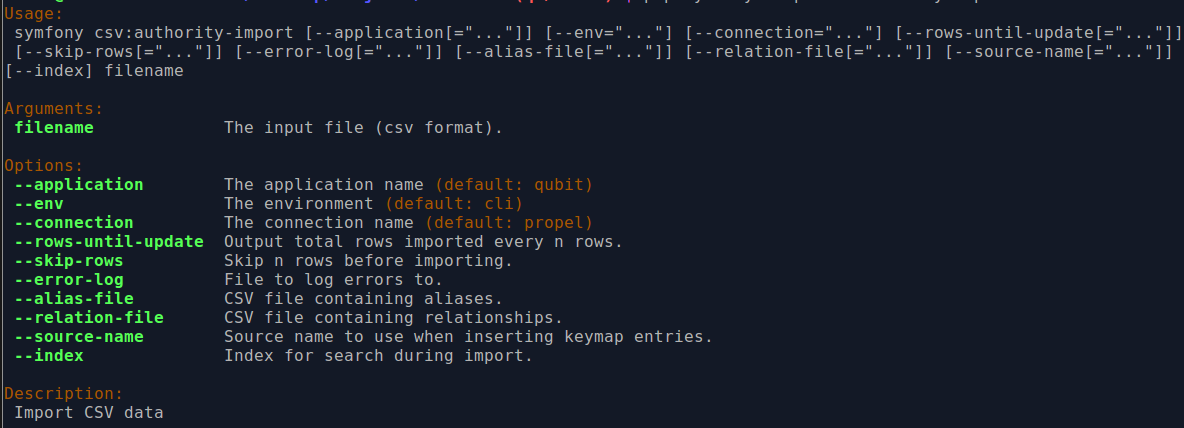
By typing php symfony help csv:authority-import into the command-line from
your root directory, without specifying the location of a CSV, you will
able able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
The --rows-until-update, --skip-rows, --error-log, and --index
options can be used the same was as described in the section
above on importing descriptions. For more information
on the --rows-until-update option, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
The --alias-file and --relation-file options are used to import
accompanying alternate name (aka Alias data) and relationship CSV files at
the same time as the authority record CSV import. An example of each will be
given below, though they can be used together.
Importing alternate names (Alias data)¶
Alternate names are defined in a separate CSV file. Each alias can be one of three forms: a parallel form, a standardized form, or “other” form. See the section on data entry above for further guidance.
An example CSV template file of supplementary alias data is available in the
AtoM source code ( at lib/task/import/example/authority_records/example_authority_
record_aliases.csv) or can be downloaded here:
The Alternate names CSV file must be imported at the same time as its related
Authority record CSV file. The --alias-file command-line option is used
to specify a separate path to the Alternate names CSV, with a back slash
( \ ) used to separate it from the path of the original authority record
CSV, as shown below.
Example import of authority records and corresponding aliases:
php symfony csv:authority-import lib/task/import/example/authority_records/example_authority_records.csv \
--alias-file=lib/task/import/example/authority_records/example_authority_record_aliases.csv
Import accessions via CSV¶
When importing information objects (e.g.
archival descriptions, you can specify an
associated accession record using an accessionNumber column in the
CSV. After importing your information objects you can then run the accession
import tool to import details about each accession from a CSV file.
An example CSV template file is available in the
lib/task/import/example/example_accessions.csv directory of AtoM, or it
can be downloaded here:
As of AtoM 2.1, a new column, qubitParentSlug has been added. This column
will behave similarly to the qubitParentSlug column in the
archival description CSV templates (described
above) - it will allow you to link new
CSV-imported accessions to existing descriptions in AtoM. To link an accession
row in your CSV to an existing description in your AtoM instance, simply enter
the slug of the target description in the qubitParentSlug column.
AtoM will located the matching description, and link the two during import,
similar to how an accession created through the user interface can be linked
to a description (see: Link an accession record to an archival description).
As of AtoM 2.2, creation event columns have been added as well. The
creators column can be used to add the name(s) of the creator of
the accession materials. For now, only creation events are supported, so the
the eventTypes value should always be Creation. eventDates,
eventStartDates, and eventEndDates columns can be used similarly to
those in the archival description CSV templates - The eventDates field
will map to the free-text display date field in AtoM, where users can use special
characters to express approximation, uncertainty, etc. (e.g. [190-?];
[ca. 1885]), while eventStartDates and eventEndDates should include
ISO-formatted date values (YYYY-MM-DD, YYYY-MM, or YYYY). If there are
multiple creators/events associated with the accession, these fields can all
accept multiple values, separated using the pipe | character.

Important
When using pipe-separated values to add multiple creators/events, values
will be matched 1:1 across all related rows (creators, eventTypes,
eventDates, eventStartDates and eventEndDates). This means that
even if you wish to leave the values for one creator blank (say the end
date for creator 1 of 2), you must still pipe the field when adding the
second creator’s endDate values, or else they will be matched up with
creator 1!
Using the user interface¶
For small imports (i.e. CSV files with less than 100 records), accession record imports can be performed via the user interface.
To import an accessions CSV file via the user interface:
- Click on the Import menu, located in
the AtoM header bar, and select “CSV”.
- AtoM will redirect you to the CSV import page. Make sure that the “Type” drop-down menu is set to “Accession”.
- Click the “Browse” button to open a window on your local computer. Select the authority record CSV file that you would like to import.
- When you have selected the file from your device, its name will appear next to the “Browse” button. Click the “Import” button located in the button block to begin your import.
Note
Depending on the size of your CSV import, this can take some time to complete. Be patient! Remember, uploads performed via the user interface are limited by the browser’s timeout limits - this is one of the reasons we recommend importing only smaller CSV files via the user interface.
Using the command-line interface (CLI)¶
For larger accession record imports (e.g. those with 100 or more records), we recommend using the command-line task to import your CSV file.
Example use - run from AtoM’s root directory:
php symfony csv:accession-import /path/to/my/example_accessions.csv
There are also a number of options available with this command-line task.
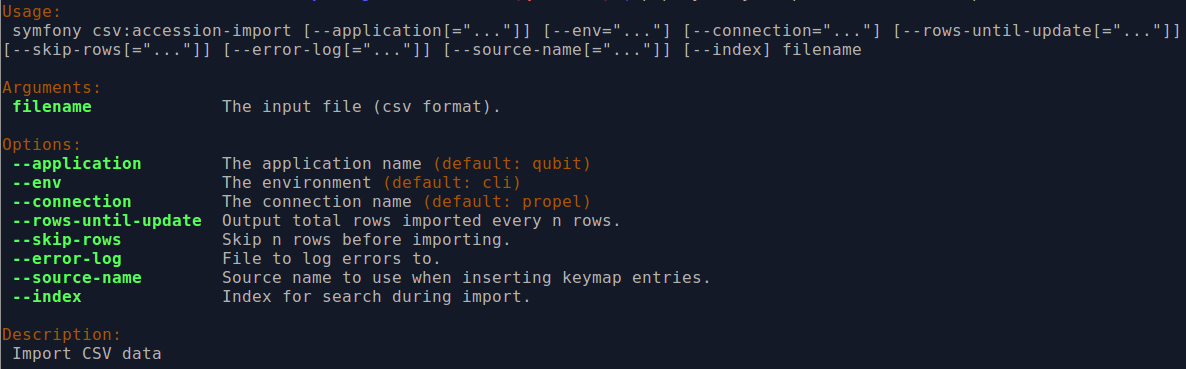
By typing php symfony help csv:accession-import into the command-line from
your root directory, without specifying the location of a CSV, you will
able able to see the CSV import options available (pictured above). A brief
explanation of each is included below.
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
Use the --source-name to specify a source importing to a AtoM installation
in which accessions and information objects from multiple sources have been
imported, and/or to associate it explicitly with a previously-imported CSV
file that used the same --source-name value. An example is provided
above in the section on legacy ID mapping.
The --rows-until-update, --skip-rows, --error-log, and --index
options can be used the same was as described in the section
above on importing descriptions. For more information
on the --rows-until-update option, see also the section below,
Display the progress of an upload via the command-line interface (CLI).
Display the progress of an upload via the command-line interface (CLI)¶
The various CSV import tools allow the use of the --rows-until-update
command-line option to display the current row of CSV data being imported.
This is an extremely simplified way to indicate progress graphically via the
command-line - the user sets a numerical value for the number of rows the task
will progress before an update, and then the task will output a dot (or period
) in the command-line every time the indicated number of rows has been
processed in the current CSV.
Example use reporting progress every 5 rows:
php symfony csv:import lib/task/import/example/rad/example_information_objects_rad.csv --rows-until-update=5
This can be useful for large imports, to ensure the import is still progressing, and to try to roughly determine how far the task has progressed and how long it will take to complete.
Load digital objects via the command line¶
Known as the Digital object load task, this command-line tool will allow a user to bulk attach digital objects to existing information objects (e.g. archival descriptions) through the use of a simple CSV file.
This task will take a CSV file as input, which contains two columns: filename
and EITHER information_object_id OR identifier as the second
column; the script will fail if these column headers are not
present in the first row of the CSV file, and it will fail if there are more
than 2 columns - you must choose which variable you prefer to work with (
identifier or object ID) for the second column. Each will be explained below.
The filename column contains the full (current) path to the digital asset
(file). The information_object_id or identifier column identifies the
linked information object. AtoM does not allow more than one digital object
per information object (with the exception of derivatives), and each digital
object must have a corresponding information object to describe it, so this
one-to-one relationship must be respected in the CSV import file.
The information_object_id is a unique internal value assigned to each
information object in AtoM’s database - it is not visible via the
user interface and you will have to perform a SQL query to find it out
- a sample SQL query with basic instructions has been included below.
The identifier can be used instead if preferred. A
description’s identifier is visible in the
user interface, which can make it less difficult to discover. **
However,**, if the target description’s identifier is not unique throughout
your AtoM instance, the digital object may not be attached to the correct
description - AtoM will attach it to the first matching identifier it finds.
Finding the information_object_id¶
The information_object_id is not a value that is accessible via the
user interface - it is a unique value used in AtoM’s database. You can,
however, use SQL in the command-line to determine the ID of an information
object. The following example will show you how to use a SQL query to find the
information_object_id, if you know the slug of the description:
First, you will need to access mysqlCLI to be able to input a SQL query. To do this, you will need to know the database name, user name, and password you used when creating your database during installation. If your database is on a different server (e.g. if you are trying to SSH in to access your database server), you will also need to know the hostname - that is, the IP address or domain name of the server where your database is located.
The following is an example of the CLI command to enter to access mysqlCLI:
mysql -u root -pMYSECRETPASSWORD atom
-u= user. If you followed our installation instructions, this will beroot-p= password. Enter the password you used during installation right after the-p. If you did not enter a password, include the-pon its own. If you are prompted later for a password and didn’t use one, just press enter.-h= hostname. If your database is on a different server, supply either an IP address, or the domain name, where it is located.atom= your database name. If you followed our installation instructions, this will beatom; otherwise enter the database name you used when installing AtoM.
You may be prompted for your password again. If so, enter it. If you did not use a password during installation, simply press enter.
Your command prompt should now say something like
mysql>. You can now enter a SQL query directly.The following example SQL command will return the information_object_id for a desription, when the information object’s slug is known:
SELECT object_id FROM slug WHERE slug='your-slug-here';
The query should return the object_id for the description. Here is an example:
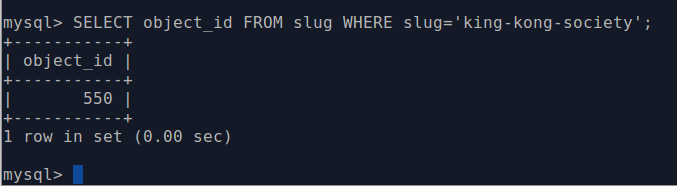
- Enter
quitto exit mysqlCLI.
Using the digital object load task¶
Before using this task, you will need to prepare:
- A CSV file with 2 columns - EITHER
information_object_idandfilename, ORidentifierandfilename - A directory with your digital objects inside of it
Important
You cannot use both information_object_id and identifier in the
same CSV - it must be one or the other. If you use the identifier, make
sure your target description identifiers are unique in AtoM - otherwise
your digital objects may not upload to the right description!
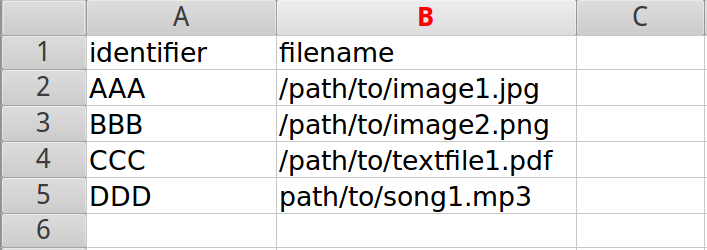
Here is a sample image of what the CSV looks like when the identifier is used, and the CSV is prepared in a spreadsheet application:
Tip
Before proceeding, make sure that you have reviewed the instructions
above, to ensure that your CSV will work when
used with the digitalobject:load task. The key point when creating a
CSV is to ensure the following:
- CSV file is saved with UTF-8 encodings
- CSV file uses Linux/Unix style end-of-line characters (
/n)
You can see the options available on the CLI task by typing in the following command:
php symfony help digitalobject:load
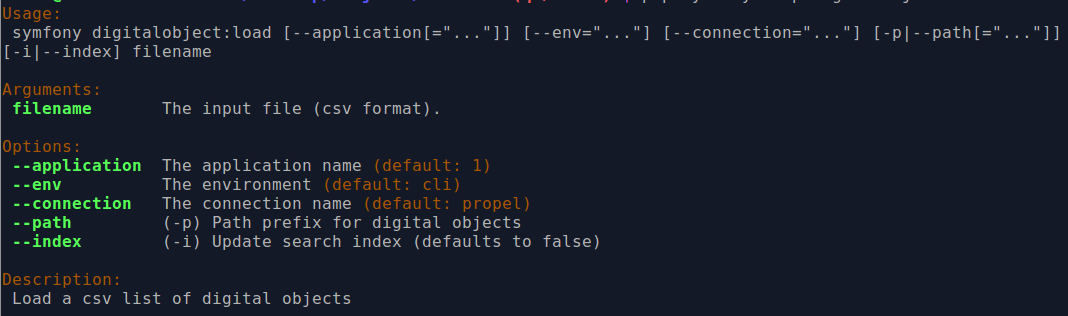
The --application, --env, and connection options should not be
used - AtoM requires the uses of the pre-set defaults for symfony to be
able to execute the import.
By default, the digital object load task will not index the collection as
it runs. This means that normally, you will need to manually repopulate the
search index after running the task. Running without indexing allows the task
to complete much more quickly - however, if you’re only uploading a small set
of digital objects, you can choose to have the task index the collection as it
progresses, using the --index (or -i) option
The --path option will allow you to simplify the filename column in
your CSV, to avoid repetition. If all the digital objects you intend to upload
are stored in the same folder, then adding /path/to/my/folder/ to each object
filename seems tedious - your filename column will need to look something
like this:
filename
/path/to/my/folder/image1.png
/path/to/my/folder/image2.jpg
/path/to/my/folder/text1.pdf
etc...
To avoid this when all digital objects are in the same directory, you can use
the --path option to pre-supply the path to the digital objects - for each
filename, the path supplied will be appended. Note that you will need to
use a trailing slash to finish your path prefix - e.g.:
php symfony digitalobject:load --path="/path/to/my/folder/" /path/to/my/spreadsheet.csv
TO RUN THE DIGITAL OBJECT LOAD TASK
php symfony digitalobject:load /path/to/your/loadfile.csv
NOTES ON USE
If an information object already has a digital object attached to it, it will be skipped during the import
Remember to repopulate the search index afterwards if you haven’t used the
--indexoption!php symfony search:populate
Regenerating derivatives¶
Sometimes the digitalobject:load task won’t generate the thumbnail
and reference images properly for digital
objects that were loaded (e.g. due to a crash or absence of convert installed,
etc.). In this case, you can regenerate these thumbsnail/reference images using
the following command:
php symfony digitalobject:regen-derivatives
Warning
All of your current derivatives will be deleted! They will be replaced with new derivatives after the task has finished running. If you have manually changed the thumbnail or reference display copy of a digital object via the user interface (see: Edit digital objects), these two will be replaced with digital object derivatives created from the master digital object.
For more information on this task and the options available, see: Regenerating derivatives.
Index your content after an upload¶
After an import, you’ll want to index your content so it can be searched by users. To do so, enter the following into the command-line:
php symfony search:populate